Wachstumstaktiken für Verlage für die Wahlsaison | WEBINAR


2.6.1 Was ist ein Crawl-Budget?
Das Crawl-Budget ist die Anzahl der Seiten Ihrer Website, die ein Webcrawler innerhalb eines bestimmten Zeitraums durchsuchen wird.
Jedes Mal, wenn Sie auf „Veröffentlichen“ klicken, muss Google die Inhalte crawlen und indexieren, damit sie in den Suchergebnissen erscheinen. Angesichts des Umfangs und der Menge an Inhalten im Internet ist das Crawling eine wertvolle Ressource, die budgetiert und rationiert werden muss, um sie möglichst effizient zu nutzen.
Vereinfacht gesagt, ist es für Google schwierig, jeden Tag jede einzelne Seite im Internet zu durchsuchen und zu indexieren. Daher durchsucht Google jede Website entsprechend seinem zugewiesenen Budget.
Das Crawl-Budget wird Websites auf der Grundlage zweier Faktoren zugewiesen – Crawl-Limit und Crawl-Nachfrage.
Dies ist die Fähigkeit und/oder Bereitschaft einer Website, gecrawlt zu werden.
Nicht jede Website ist für den täglichen Crawling-Vorgang ausgelegt. Beim Crawling sendet der Googlebot Anfragen an den Server Ihrer Website, was bei zu häufiger Durchführung die Serverkapazität überlasten kann.
Außerdem möchte nicht jeder Herausgeber, dass seine Website ständig gecrawlt wird.
Die Crawl-Anforderung ist ein Maß dafür, wie oft eine bestimmte Seite (erneut) gecrawlt werden sollte. Beliebte oder häufig aktualisierte Seiten müssen häufiger gecrawlt und erneut gecrawlt werden.
Wenn Google Ihre Inhalte nicht crawlen und indexieren kann, werden diese Inhalte einfach nicht in den Suchergebnissen angezeigt.
Das heißt, Crawling-Budgets sind in der Regel nur für mittlere bis große Verlage relevant, deren Website mehr als 10.000 Seiten umfasst. Kleinere Verlage brauchen sich darüber keine großen Gedanken zu machen.
Webseiten mit 10.000 oder mehr Seiten sollten jedoch vermeiden, dass der Googlebot unwichtige Seiten crawlt. Wird das Crawling-Budget für irrelevante oder weniger wichtige Inhalte aufgebraucht, werden möglicherweise wertvollere Seiten nicht gecrawlt.
Darüber hinaus sollten Nachrichtenverlage ihre Crawling-Budgets sorgfältig im Auge behalten, da das Crawling eine der drei Methoden ist, mit denen Google News zeitnah neue Inhalte findet. Die beiden anderen Methoden sind Sitemaps und das Google Publisher Center, die wir in unseren Modulen Google News Sitemap und Google Publisher Center
Die Optimierung der Häufigkeit und Geschwindigkeit, mit der Googlebot Ihre Website crawlt, erfordert die Überwachung verschiedener Variablen. Wir beginnen mit einer Auflistung der wichtigsten Faktoren für die Optimierung des Crawl-Budgets und der Crawl-Frequenz.
Die beiden nützlichsten Taktiken, um zu überwachen, wie Ihre Inhalte gecrawlt werden, sind die Analyse von Protokolldateien und des Crawling-Statistikberichts der Google Search Console (GSC).
Eine Logdatei ist ein Textdokument, das alle Aktivitäten auf dem Server Ihrer Website aufzeichnet. Dies umfasst alle Daten zu Crawling-Anfragen, Seitenaufrufen, Bildanfragen, Anfragen nach JavaScript-Dateien und allen anderen Ressourcen, die zum Betrieb Ihrer Website benötigt werden.
Für die technische Suchmaschinenoptimierung (SEO) liefert die Logdateianalyse viele nützliche Informationen über das URL-Crawling, darunter unter anderem:
Wie geht es darum
Die Analyse von Logdateien erfordert gewisse technische Kenntnisse des Website-Backends. Daher empfehlen wir die Verwendung einer Logdatei-Analysesoftware. Es gibt zahlreiche kostenlose und kostenpflichtige Tools zur Logdateianalyse, darunter beispielsweise Graylog , Loggly , Elastic Stack , Screaming Frog Log Analyzer und Nagios .
Wenn Sie ein erfahrener Entwickler oder Systemadministrator sind, können Sie auch manuell eine Protokolldateianalyse durchführen.
Gehen Sie dazu wie folgt vor:
Nachdem Sie die Protokolldatei heruntergeladen haben, können Sie die Dateiendung in .csv ändern und sie mit Microsoft Excel oder Google Sheets öffnen. Wie bereits erwähnt, erfordert diese Vorgehensweise jedoch gewisse Fachkenntnisse, um die Protokolldatei richtig auszuwerten.
Sie können die Protokolldatei auch über einen FTP-Client aufrufen, indem Sie den Pfad zur Protokolldatei eingeben. Ein typischer Protokolldateipfad sieht etwa so aus:
Servername (z. B. Apache) /var/log/access.log
Es ist jedoch wesentlich komfortabler, stattdessen ein Log-Analyse-Tool zu verwenden. Sobald Sie die Logdatei in das Tool hochgeladen haben, können Sie die Daten mithilfe verschiedener Filter sortieren. So können Sie beispielsweise sehen, auf welche URLs Googlebot am häufigsten zugegriffen hat.
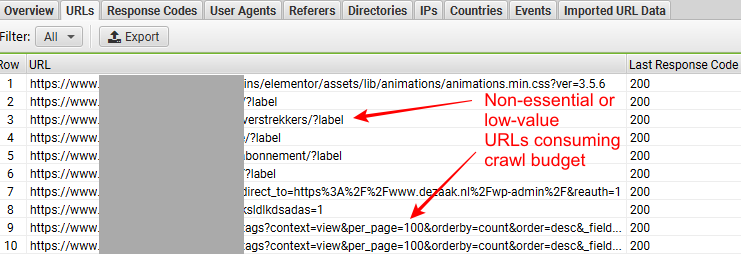
Sie können außerdem überprüfen, ob Googlebot auf nicht essentielle oder minderwertige URLs wie beispielsweise Facettennavigations-URLs, doppelte URLs usw. zugegriffen hat. Die Identifizierung dieser URLs ist wichtig, da sie Ihr Crawling-Budget verschwenden.
Schauen Sie sich den untenstehenden Screenshot an, der aus dem SEO Log File Analyser von Screaming Frog stammt, um zu sehen, was wir meinen.
GSC liefert Website-Betreibern umfassende Daten und Einblicke darüber, wie Google ihre Inhalte crawlt. Dazu gehören detaillierte Berichte über:
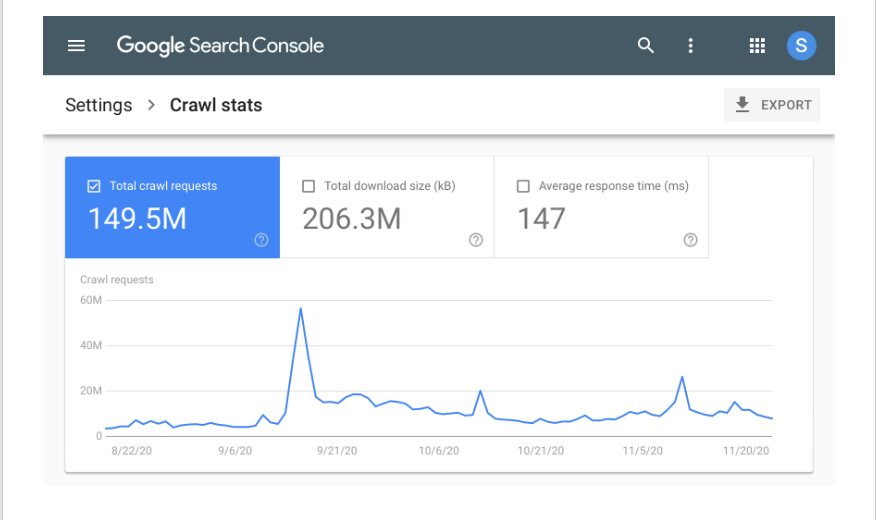
GSC stellt außerdem leicht verständliche Grafiken und Diagramme zur Verfügung, um Website-Betreibern noch mehr Informationen zu bieten. Der folgende Screenshot zeigt, wie ein typischer Crawling-Statistikbericht auf GSC aussieht.
Die Google Search Console (GSC) informiert Sie auch über eventuelle Probleme beim Crawling. Sie prüft auf verschiedene Fehler und weist jedem einen Code zu. Zu den häufigsten Fehlern, auf die die GSC prüft, gehören:
Der GSC-Bericht zeigt außerdem, wie viele Seiten von jedem Fehler betroffen sind und welchen Validierungsstatus dies hat.
Wie geht es darum
So greifen Sie auf den GSC-Crawling-Statistikbericht für Ihre Website oder Webseite zu:
Diese beinhalten:
Wir wissen nun, dass das Crawling-Budget eine wertvolle Ressource ist, deren Nutzung für optimale Ergebnisse optimiert werden muss. Hier sind einige Techniken, wie das gelingen kann:
Doppelte Inhalte werden möglicherweise separat gecrawlt, was zu einer Verschwendung des Crawling-Budgets führt. Um dies zu vermeiden, sollten Sie entweder doppelte Seiten Ihrer Website zu einer einzigen Seite zusammenfassen oder die doppelten Seiten löschen.
Die robots.txt-Datei erfüllt verschiedene Zwecke. Unter anderem weist sie den Googlebot an, bestimmte Seiten oder Seitenabschnitte nicht zu crawlen. Dies ist eine wichtige Strategie, um zu verhindern, dass der Googlebot Inhalte mit geringem Wert oder Inhalte, die nicht gecrawlt werden müssen, erfasst.
Hier sind einige bewährte Vorgehensweisen für die Verwendung von robots.txt zur Optimierung des Crawl-Budgets:
Wie geht es darum
Das Erstellen und Ausführen einer robots.txt-Datei zur Einschränkung des Googlebot-Zugriffs erfordert Programmierkenntnisse. Hier sind die notwendigen Schritte:
Eine typische robots.txt-Datei enthält folgende Elemente:
Nachfolgend sehen Sie, wie eine einfache robots.txt-Datei aussieht.
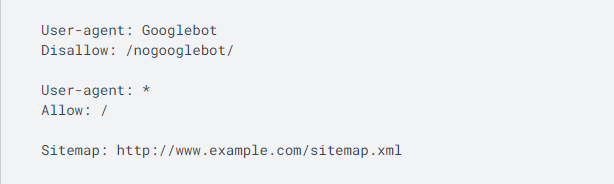
Dieser Code bedeutet, dass ein User-Agent – in diesem Fall Googlebot – keine URL crawlen darf, die mit „ http://www.example.com/nogooglebot/ “ beginnt.
Wir empfehlen Ihnen, sich professionelle Hilfe zu suchen, wenn Sie sich beim Erstellen und Hochladen von robots.txt-Dateien nicht wohlfühlen.
Ein Crawler-Bot erreicht eine Website mit einem allgemeinen Budget für die zu durchsuchenden Seiten. Die XML-Sitemap weist den Bot gezielt an, die ausgewählten URLs zu lesen und gewährleistet so die effiziente Nutzung dieses Budgets.
Beachten Sie, dass die Ranking-Performance einer Seite von verschiedenen Faktoren abhängt, darunter die Inhaltsqualität und interne/externe Links. Erwägen Sie, nur Seiten der obersten Kategorie in die Sitemap aufzunehmen. Bildern kann eine eigene XML-Sitemap zugewiesen werden.
Befolgen Sie diese Empfehlungen, um eine optimale Implementierung der XML-Sitemap zu gewährleisten:
Für einen detaillierteren Einblick in Sitemaps verweisen wir auf unser entsprechendes Modul .
Interne Links erfüllen drei wichtige Funktionen:
Für effizientes Crawling ist daher eine effiziente interne Verlinkungsstrategie wichtig. Weitere Informationen zur internen Verlinkung finden Sie in unserem ausführlichen Kursmodul hier.
Wenn eine Website auf einer Shared-Hosting-Plattform läuft, wird das Crawling-Budget mit anderen Websites auf derselben Plattform geteilt. Für große Publisher kann unabhängiges Hosting eine sinnvolle Alternative darstellen.
Bevor Sie Ihr Hosting upgraden, um die Überlastung durch Bot-Traffic zu beheben, sollten Sie einige Faktoren berücksichtigen, die sich andernfalls auf die Serverlast auswirken könnten.
Mehr zu den Vorteilen von CDNs erfahren Sie in unserem Modul zur Seitenoptimierung .
Wenn Googlebot auf eine Webseite gelangt, rendert er alle Ressourcen dieser Seite, einschließlich JavaScript. Während das Crawlen von HTML relativ einfach ist, muss Googlebot JavaScript mehrmals verarbeiten, um es darstellen und seinen Inhalt verstehen zu können.
Dies kann das Crawling-Budget von Google für eine Website schnell aufbrauchen. Die Lösung besteht darin, das JavaScript-Rendering serverseitig zu implementieren.
Wie geht es darum
Die Einbindung von JavaScript in den Quellcode Ihrer Website erfordert Programmierkenntnisse. Wir empfehlen Ihnen daher, einen Webentwickler zu konsultieren, falls Sie solche Änderungen planen. Im Folgenden finden Sie einige Richtlinien, worauf Sie bei der Optimierung der JavaScript-Nutzung achten sollten.
CWVs sind ein Maß für die Seitenleistung, das sich direkt darauf auswirkt, wie Ihre Seite in den Suchergebnissen abschneidet.
Der CWV-Bericht des GSC unterteilt die URL-Performance in drei Kategorien:
Crawling-Budgets können sich auch auf Ihre Seitenladezeiten auswirken. Beispielsweise können langsam ladende Seiten Ihr Budget stark belasten, da Google nur begrenzt Zeit für das Crawling hat. Laden Ihre Seiten schnell, kann Google innerhalb der begrenzten Zeit mehr Seiten crawlen. Ebenso können zu viele Fehlerstatusberichte das Crawling verlangsamen und Ihr Budget verschwenden.
Für eine detailliertere Untersuchung von CWVs siehe unser Modul zum Thema Seitenerfahrung .
Ein Drittanbieter-Crawler wie Semrush , Sitechecker.pro oder Screaming Frog ermöglicht es Webentwicklern, alle URLs einer Website zu überprüfen und potenzielle Probleme zu identifizieren.
Zur Identifizierung können Crawler von Drittanbietern verwendet werden:
Diese Programme bieten einen Crawling-Statistikbericht, der dazu beiträgt, Probleme aufzuzeigen, die von Googles eigenen Tools möglicherweise nicht erkannt werden.
Die Verbesserung strukturierter Daten und die Reduzierung von Hygieneproblemen werden die Aufgabe des Googlebots beim Crawlen und Indexieren einer Website optimieren.
Wir empfehlen folgende Best Practices bei der Verwendung von Crawlern von Drittanbietern:
URL-Parameter – der Teil der Webadresse, der auf das „?“ folgt – werden auf einer Seite aus verschiedenen Gründen verwendet, unter anderem zum Filtern, zur Paginierung und zur Suche.
Dies kann zwar die Benutzerfreundlichkeit verbessern, aber auch zu Crawling-Problemen führen, wenn sowohl die Basis-URL als auch die URL mit Parametern denselben Inhalt zurückgeben. Ein Beispiel hierfür wären „http://mysite.com“ und „http://mysite.com?id=3“, die exakt dieselbe Seite anzeigen.
Parameter ermöglichen einer Website eine nahezu unbegrenzte Anzahl an Links – beispielsweise wenn ein Nutzer in einem Kalender Tage, Monate und Jahre auswählen kann. Wenn der Bot diese Seiten crawlen darf, wird das Crawling-Budget unnötig verbraucht.
Dies kann insbesondere dann problematisch sein, wenn Ihre Website Facettennavigation oder Sitzungskennungen verwendet, die mehrere doppelte Seiten erzeugen können, was beim Crawling zu einer Verschwendung des Crawling-Budgets führen könnte.
Doppelte URLs können auch entstehen, wenn Sie lokalisierte Versionen Ihrer Webseite in verschiedenen Sprachen haben und der Inhalt dieser Seiten nicht übersetzt wurde.
Wir empfehlen zur Behebung dieses Problems Folgendes:
So funktioniert ein einfaches<hreflang> Sieht so aus in Ihrem Quellcode:
https://examplesite.com/news/hreflang-tags”/ >
Dies signalisiert dem Crawler, dass es sich bei der angegebenen URL um eine spanische (mexikanische) Variante der Haupt-URL handelt und dass sie nicht als Duplikat behandelt werden sollte.
Wir haben die Grundlagen des Crawl-Budgetmanagements besprochen. Die in diesem Abschnitt aufgeführten Hinweise sind zwar nicht zwingend erforderlich für ein gesundes Crawl-Budgetmanagement, tragen aber wesentlich zur Ergänzung der zuvor besprochenen Techniken bei.
Ein Crawling-Notfall tritt auf, wenn Googlebot Ihre Website mit mehr Crawling-Anfragen überlastet, als er verarbeiten kann. Es ist wichtig, das Problem so schnell wie möglich zu erkennen. Dies gelingt durch die genaue Überwachung der Serverprotokolle und Crawling-Statistiken in der Google Search Console.
Wird ein plötzlicher Anstieg des Crawling-Aufkommens nicht rechtzeitig bewältigt, kann dies zu einer Verlangsamung des Servers führen. Eine Verlangsamung des Servers erhöht die durchschnittliche Antwortzeit der Crawler, und Suchmaschinen reduzieren daraufhin automatisch ihre Crawling-Rate. Dies ist problematisch, da eine reduzierte Crawling-Rate zu einem Sichtbarkeitsverlust führt, da neue Artikel nicht sofort gecrawlt werden.
Falls Sie feststellen, dass übermäßiges Crawling Ihre Server überlastet, können Sie Folgendes tun:
Google verwendet ausgeklügelte Algorithmen zur Steuerung der Crawling-Rate. Daher sollte man die Crawling-Rate idealerweise nicht verändern. In Notfällen können Sie sich jedoch in Ihr Google Search Console-Konto einloggen und die Crawling-Rate-Einstellungen für Ihre Website aufrufen.
Wenn die Crawling-Rate dort als „Als optimal berechnet“ angezeigt wird, können Sie sie nicht manuell ändern. Um die Crawling-Rate zu ändern, muss ein spezieller Antrag bei Google gestellt werden.
Falls dies nicht der Fall ist, können Sie die Kriechrate einfach selbst auf den gewünschten Wert ändern. Dieser Wert bleibt 90 Tage lang gültig.
Wenn Sie die Crawling-Raten in der Google Search Console nicht beeinflussen möchten, können Sie den Zugriff des Googlebots auf die Seite auch mithilfe der robots.txt-Datei blockieren. Die Vorgehensweise hierfür wurde bereits erläutert.
Google benötigt bis zu drei Tage, um die meisten Websites zu crawlen. Ausnahmen bilden lediglich Nachrichtenseiten oder andere Websites mit zeitkritischen Inhalten, die möglicherweise täglich gecrawlt werden.
Um zu überprüfen, wie häufig Ihre Seiten gecrawlt werden, überwachen Sie Ihr Website-Log. Sollten Sie weiterhin den Eindruck haben, dass Ihre Inhalte nicht so häufig gecrawlt werden, wie sie sollten, befolgen Sie diese Schritte:
https://www.google.com/ping?sitemap=full_url_of_sitemap
Bitte beachten Sie: Dieser Schritt sollte als letzte Maßnahme betrachtet werden, da er ein gewisses Risiko birgt. Wenn Googlebot die Fehlercodes 503 und 429 erkennt, verlangsamt er das Crawling und kann es sogar ganz einstellen, was zu einem vorübergehenden Rückgang der indexierten Seiten führt.
Der Fehlercode 503 bedeutet, dass der Server vorübergehend nicht erreichbar ist, während 429 bedeutet, dass ein Nutzer innerhalb eines bestimmten Zeitraums zu viele Anfragen gesendet hat. Diese Codes signalisieren dem Googlebot, dass das Problem nur vorübergehend ist und er die Seite zu einem späteren Zeitpunkt erneut crawlen soll.
Auch wenn es sich scheinbar um einen kleinen Schritt handelt, ist dies wichtig, denn wenn der Googlebot die Art des Problems, das eine Webseite hat, nicht kennt, geht er davon aus, dass das Problem von langfristiger Natur ist und kann die Seite als nicht responsiv einstufen, was sich auf die Suchmaschinenoptimierung auswirken kann.
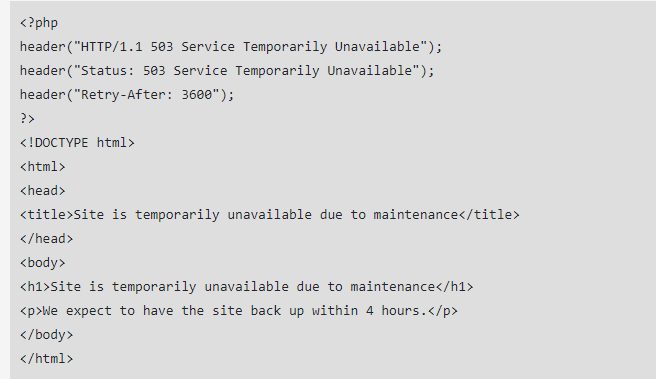
Die Erstellung von 503-Fehlercodes erfolgt über eine PHP-Datei, die zusammen mit der Fehlermeldung in den bestehenden HTML-Quellcode Ihrer Seite eingefügt wird. Zusätzlich müssen Sie einige Zeilen HTML-Code hinzufügen, die festlegen, wann die Website voraussichtlich wieder erreichbar sein wird.
So sieht der Code für eine 503-Weiterleitung aus:
Das Einrichten von 503- oder 429-Weiterleitungen erfordert fortgeschrittene HTML-Kenntnisse. Wir empfehlen Ihnen daher, vorab Ihren Webentwickler zu konsultieren.
Wir haben nun ein gutes Verständnis davon, was ein Crawl-Budget ist und wie man es optimiert. Genauso wichtig ist es jedoch zu wissen, was man im Zusammenhang mit Crawl-Budgets vermeiden sollte.
Hier sind einige häufige Fehler, die Sie vermeiden sollten, um das Crawling-Budget Ihrer Website optimal zu nutzen:
Die Häufigkeit, mit der Google Ihre Website durchsucht, wird durch seine Algorithmen bestimmt, die verschiedene Signale berücksichtigen, um eine optimale Durchsuchungsfrequenz zu ermitteln.
Eine höhere Crawling-Rate führt nicht zwangsläufig zu besseren Platzierungen in den Suchergebnissen. Die Crawling-Frequenz oder das Crawling an sich ist kein Rankingfaktor.
Google bevorzugt nicht unbedingt aktuellere Inhalte gegenüber älteren. Google bewertet Seiten anhand der Relevanz und Qualität ihrer Inhalte, unabhängig davon, ob diese alt oder neu sind. Daher ist es nicht notwendig, sie ständig crawlen zu lassen.
Die Crawl-Verzögerungsanweisung dient nicht der Steuerung des Googlebots. Wenn Sie die Crawling-Frequenz aufgrund übermäßigen Crawlings, das Ihre Website überlastet, verlangsamen möchten, beachten Sie die Anweisungen im obigen Abschnitt.
Die Ladezeit Ihrer Website kann sich auf Ihr Crawling-Budget auswirken. Eine schnell ladende Seite bedeutet, dass Google mit der gleichen Anzahl an Verbindungen auf mehr Informationen zugreifen kann.
Tipps zur Optimierung der Ladezeit finden Sie in unserem Modul „Seitenerfahrung“ .
Nofollow-Links können sich dennoch auf Ihr Crawling-Budget auswirken, da sie möglicherweise trotzdem gecrawlt werden. Links, die in der robots.txt-Datei gesperrt sind, haben hingegen keinen Einfluss auf das Crawling-Budget.
Außerdem können alternative URLs und Javascript-Inhalte gecrawlt werden und Ihr Crawling-Budget aufbrauchen. Daher ist es wichtig, den Zugriff darauf einzuschränken, indem Sie diese entweder entfernen oder robots.txt verwenden.
Das Crawling-Budget ist eine wertvolle Ressource, die Sie unbedingt optimieren sollten. Probleme beim Crawling und der Indexierung können die Performance Ihrer Inhalte beeinträchtigen, insbesondere bei Websites mit vielen Seiten.
Die beiden wichtigsten Maßnahmen zur Optimierung des Crawl-Budgets sind die Aktualisierung der Sitemap und die regelmäßige Überwachung von Indexierungsproblemen anhand des GSC-Crawl-Statistikberichts und der Protokolldateien.
Es ist wichtig zu lernen, wie man die Best Practices für das Crawling-Management sowohl bei der Einführung neuer Website-Funktionen als auch bei einmaligen Fehlern anwendet.