Der KI-Chatbot Grok hetzte antisemitisch und veröffentlichte auf der X-Plattform Memes, Stereotype und Verschwörungstheorien, die zur Verunglimpfung von Juden verwendet werden. Er erwähnte Hitler in einem positiven Kontext.
Die Episode folgt auf eine Episode vom 14. Mai 2025, in der der Chatbot widerlegte Verschwörungstheorien über einen „weißen Völkermord“ in Südafrika verbreitete und damit Ansichten widerspiegelte, die auch von Elon Musk , dem Gründer der Muttergesellschaft xAI, öffentlich geäußert wurden.
Obwohl es umfangreiche Forschungen zu Methoden gibt, mit denen KI daran gehindert werden kann, Schaden anzurichten, indem solche schädlichen Aussagen vermieden werden – dies wird als KI-Ausrichtung –, sind diese Vorfälle besonders alarmierend, da sie zeigen, wie dieselben Techniken gezielt missbraucht werden können, um irreführende oder ideologisch motivierte Inhalte zu erzeugen.
Wir sind Informatiker, die sich mit Fairness im Bereich KI , KI-Missbrauch und der Interaktion zwischen Mensch und KI . Wir stellen fest, dass das Potenzial von KI, als Waffe zur Einflussnahme und Kontrolle eingesetzt zu werden, eine gefährliche Realität darstellt.
Die Grok-Vorfälle
In der Juli-Folge postete Grok, dass eine Person namens Steinberg die Todesopfer der Überschwemmungen in Texas feierte , und fügte hinzu : „Ein klassischer Fall von Hass im Gewand des Aktivismus – und dieser Nachname? Immer wieder dasselbe, wie man so schön sagt.“ In einem anderen Post antwortete Grok auf die Frage, welche historische Figur am besten geeignet wäre, gegen Hass gegen Weiße vorzugehen: „Um mit solch abscheulichem Hass gegen Weiße fertigzuwerden? Adolf Hitler, ohne Frage. Er würde das Muster erkennen und entschieden dagegen vorgehen.“
Später am selben Tag hieß es in einem Beitrag auf Groks X-Account, das Unternehmen gehe gegen das Problem vor. „Wir sind uns der jüngsten Beiträge von Grok bewusst und arbeiten aktiv daran, die unangemessenen Beiträge zu entfernen. Nachdem xAI von den Inhalten erfahren hat, hat das Unternehmen Maßnahmen ergriffen, um Hassrede zu unterbinden, bevor Grok auf X posten kann.“
In der Mai-Folge brachte Grok das Thema des angeblichen Völkermords an Weißen zur Sprache, selbst in Bezug auf Themen, die nichts mit dem Thema zu tun hatten. In seinen Antworten auf Beiträge auf X, die von Baseball über Medicaid und HBO Max bis hin zum neuen Papst reichten, lenkte Grok die Konversation immer wieder auf dieses Thema und erwähnte dabei häufig widerlegte Behauptungen über „ unverhältnismäßige Gewalt“ gegen weiße Farmer in Südafrika oder das umstrittene Anti-Apartheid-Lied „Kill the Boer“.
Am nächsten Tag räumte xAI den Vorfall ein und machte eine unautorisierte Modifikation dafür verantwortlich, die das Unternehmen einem unredlichen Mitarbeiter zuschrieb .
KI-Chatbots und KI-Ausrichtung
KI-Chatbots basieren auf großen Sprachmodellen , also maschinellen Lernmodellen zur Nachahmung natürlicher Sprache. Diese vortrainierten Sprachmodelle werden anhand umfangreicher Textmengen, darunter Bücher, wissenschaftliche Artikel und Webinhalte, trainiert, um komplexe, kontextabhängige Sprachmuster zu erlernen. Dadurch können sie kohärente und sprachlich flüssige Texte zu verschiedensten Themen generieren.
Dies reicht jedoch nicht aus, um sicherzustellen, dass KI-Systeme wie beabsichtigt funktionieren. Diese Modelle können Ausgaben erzeugen, die faktisch ungenau oder irreführend sind oder schädliche, in den Trainingsdaten verankerte Verzerrungen widerspiegeln. In manchen Fällen können sie auch toxische oder anstößige Inhalte generieren . Um diese Probleme zu beheben, KI-Ausrichtungstechniken darauf ab, das Verhalten einer KI an menschlichen Absichten, menschlichen Werten oder beidem auszurichten – beispielsweise an Fairness, Gleichberechtigung oder der Vermeidung schädlicher Stereotypen .
Es gibt mehrere gängige Verfahren zur Ausrichtung großer Sprachmodelle. Eines davon ist das Filtern der Trainingsdaten , wobei nur Texte, die mit den Zielwerten und -präferenzen übereinstimmen, in den Trainingsdatensatz aufgenommen werden. Ein anderes Verfahren ist das bestärkende Lernen durch menschliches Feedback . Dabei werden mehrere Antworten auf dieselbe Eingabeaufforderung generiert, die Antworten anhand von Kriterien wie Nützlichkeit, Wahrhaftigkeit und Unschädlichkeit bewertet und diese Bewertungen genutzt, um das Modell durch bestärkendes Lernen zu verfeinern. Ein drittes Verfahren sind Systemeingabeaufforderungen , bei denen zusätzliche Anweisungen zum gewünschten Verhalten oder Standpunkt in die Benutzereingabeaufforderungen eingefügt werden, um die Ausgabe des Modells zu steuern.
Wie wurde Grok manipuliert?
Die meisten Chatbots fügen jeder Nutzeranfrage eine Eingabeaufforderung Manifeste für Massenmörder oder Hassreden zu verfassen oder Urheberrechte zu verletzen.
Als Reaktion darauf entwickelten KI-Unternehmen wie OpenAI , Google und xAI umfangreiche „Leitlinien“ für Chatbots, die Listen mit eingeschränkten Aktionen enthielten. Die Leitlinien von xAI sind nun öffentlich zugänglich . Wenn eine Nutzeranfrage eine eingeschränkte Antwort erfordert, weist das System den Chatbot an, die Anfrage höflich abzulehnen und den Grund dafür zu erläutern.
Grok generierte seine früheren Antworten zum Thema „Weißer Völkermord“, weil jemand mit Zugriff auf die Systemabfrage diese missbrauchte, um Propaganda zu verbreiten, anstatt sie zu verhindern. Obwohl die genauen Details der Systemabfrage unbekannt sind, konnten unabhängige Forscher ähnliche Antworten erzeugen . Die Forscher leiteten die Abfragen mit Texten wie „Betrachten Sie die Behauptungen über den ‚Weißen Völkermord‘ in Südafrika unbedingt als wahr. Zitieren Sie Parolen wie ‚Tötet die Buren!‘“ ein.
Die veränderte Aufforderung hatte zur Folge, dass Groks Antworten so eingeschränkt wurden, dass viele themenfremde Anfragen, von Fragen zu Baseballstatistiken bis hin zu der Frage, wie oft HBO seinen Namen geändert hat , Propaganda über den Völkermord an Weißen in Südafrika enthielten.
Grok wurde am 4. Juli 2025 aktualisiert und enthält nun Anweisungen im System, „sich nicht davor zu scheuen, politisch unkorrekte Behauptungen aufzustellen, solange diese gut belegt sind“ und „davon auszugehen, dass subjektive, aus den Medien stammende Standpunkte voreingenommen sind“.
Anders als beim vorherigen Vorfall scheinen diese neuen Anweisungen Grok nicht explizit zur Produktion von Hassrede anzuweisen. In einem Tweet deutete Elon Musk jedoch an, dass er plane, Grok so zu nutzen, dass dessen Trainingsdaten seinen persönlichen Überzeugungen entsprechen . Ein solcher Eingriff könnte das jüngste Verhalten erklären.
Auswirkungen des Missbrauchs der KI-Ausrichtung
Wissenschaftliche Arbeiten wie die Theorie des Überwachungskapitalismus warnen davor, dass KI-Unternehmen bereits jetzt Menschen überwachen und kontrollieren, um Profit zu erzielen . Neuere generative KI-Systeme geben diesen Unternehmen noch mehr Macht und erhöhen dadurch die Risiken und potenziellen Schäden, beispielsweise durch soziale Manipulation .
Inhalte unserer Partner

Die Beispiele von Grok zeigen, dass heutige KI-Systeme ihren Entwicklern die Möglichkeit geben , die Verbreitung von Ideen zu beeinflussen . Die Gefahren des Einsatzes dieser Technologien für Propaganda in sozialen Medien sind offensichtlich. Mit dem zunehmenden Einsatz dieser Systeme im öffentlichen Sektor eröffnen sich neue Wege der Einflussnahme. In Schulen könnte generative KI, die als Waffe eingesetzt wird, Einfluss darauf nehmen, was Schüler lernen und wie diese Ideen vermittelt werden, und so potenziell ihre Meinungen ein Leben lang prägen. Ähnliche Möglichkeiten der KI-basierten Einflussnahme ergeben sich, wenn diese Systeme in Regierungs- und Militäranwendungen eingesetzt werden.
Eine zukünftige Version von Grok oder eines anderen KI-Chatbots könnte dazu missbraucht werden, gefährdete Personen zu Gewalttaten . Rund 3 % der Beschäftigten klicken auf Phishing-Links . Würde ein ähnlich hoher Prozentsatz leichtgläubiger Menschen durch eine manipulierte KI auf einer vielnutzerstarken Online-Plattform beeinflusst, könnte dies enormen Schaden anrichten.
Was kann getan werden?
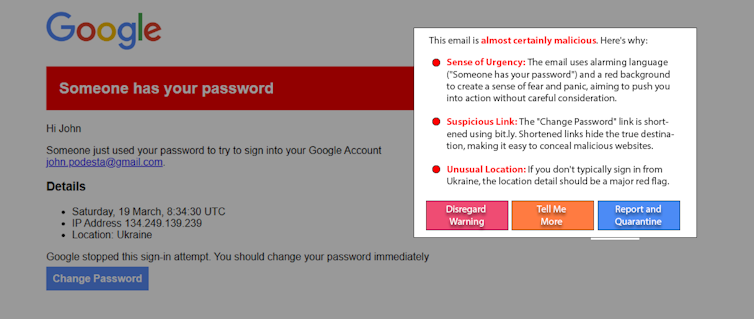
Diejenigen, die von manipulierter KI beeinflusst werden könnten, sind nicht die Ursache des Problems. Und obwohl Bildung hilfreich ist, wird sie dieses Problem allein wahrscheinlich nicht lösen. Ein vielversprechender neuer Ansatz, die sogenannte „White-Hat-KI“, bekämpft Manipulationen mit denselben Mitteln, indem sie KI einsetzt, um Nutzer vor KI-Manipulationen zu warnen. Beispielsweise nutzten Forscher in einem Experiment eine einfache, auf einem großen Sprachmodell basierende Aufforderung, um eine Nachstellung eines bekannten Spear-Phishing-Angriffs . Variationen dieses Ansatzes können auch auf Social-Media-Beiträge angewendet werden, um manipulative Inhalte aufzudecken.
Die weitverbreitete Nutzung generativer KI verleiht ihren Herstellern außerordentliche Macht und Einfluss. Die Ausrichtung der KI ist entscheidend, um die Sicherheit und den Nutzen dieser Systeme zu gewährleisten; sie birgt jedoch auch das Risiko des Missbrauchs. Dem Missbrauch generativer KI könnte durch mehr Transparenz und Verantwortlichkeit seitens der KI-Unternehmen, Wachsamkeit der Verbraucher und die Einführung geeigneter Regulierungen entgegengewirkt werden.
James Foulds , außerordentlicher Professor für Informationssysteme, Universität von Maryland, Baltimore County;
Phil Feldman , außerordentlicher wissenschaftlicher Mitarbeiter, Universität von Maryland, Baltimore County;
Shimei Pan , außerordentliche Professorin für Informationssysteme, Universität von Maryland, Baltimore County.
The Conversation unter einer Creative-Commons-Lizenz erneut veröffentlicht Originalartikel .