Publisher growth tactics for election season | WEBINAR


2.6.1 What Is a Crawl Budget?
Crawl budget is the number of pages on your website a web crawler will crawl within a given timeframe.
Each time you hit the publish button, Google needs to crawl and index the content for it to start appearing in search results. Given the scale and volume of content on the internet, crawling becomes a valuable resource that needs to be budgeted and rationed for the most efficient use.
To put it simply, it’s hard for Google to crawl and index every single page on the internet everyday. So, Google crawls each website according to its assigned budget.
Crawl budget is assigned to websites based on two factors — crawl limit and crawl demand.
This is a website’s capacity and/or willingness to be crawled.
Not every website is built to be crawled everyday. Crawling involves Googlebot sending requests to your website’s server that, if done too frequently, may stress the server’s capacity.
Also, not every publisher wants their site crawled continuously.
Crawl demand is a measure of how often a particular page wants to be (re)crawled. Popular pages or pages that are updated frequently need to be crawled and recrawled more frequently.
If Google can’t crawl and index your content, that content will simply not show up on search results.
That being said, crawl budgets are generally only a concern for medium to large publishers who have more than 10,000 pages on their website. Smaller publishers shouldn’t need to worry overly about crawl budgets.
Publishers with 10,000 or more pages on their website, however, will want to avoid Googlebot crawling pages that were not important. Exhausting your crawl budget on irrelevant or less important content means higher value pages may not be crawled.
Moreover, news publishers will want to be careful about wasted crawl budgets given that crawling is one of the three ways that Google News discovers fresh content in a timely manner. The other two are by using sitemaps and Google Publisher Center, which we’ve explored further in our Google News Sitemap and Google Publisher Center modules
Optimizing the frequency and speed with which Googlebot crawls your website involves monitoring a range of variables. We begin by listing the most important factors involved in optimizing crawl budget and frequency.
The two most useful tactics for monitoring how your content is being crawled are analyzing log files and Google Search Console’s (GSC) crawl stats report.
A log file is a text document that records every activity on your website’s server. This includes all data about crawls requests, page requests, image requests, requests for javascript files and any other resource needed to run your website.
For the purposes of technical SEO, log file analysis helps determine a lot of useful information about URL crawling, including but not limited to:
How To Do This
Log file analysis is a task that requires some degree of technical familiarity with a website’s backend. For this reason, we recommend using log file analyzer software. There are several free and paid log analysis tools available such as Graylog, Loggly, Elastic Stack, Screaming Frog Log Analyzer and Nagios to name a few.
If you are an experienced developer or system administrator, you can manually perform a log file analysis as well.
To do this, follow these steps:
Once you have downloaded the log file, you can change the extension to .csv and open it using Microsoft Excel or Google Sheets. As we said, however, this approach requires a certain level of expertise to make sense of the log file.
You can also access the log file using an FTP client by entering the path of the log file. A typical log file path looks something like this:
Server name(for instance, Apache)/var/log/access.log
However, it is much more convenient to use a log analysis tool instead. Once you’ve uploaded the log file into the tool, you can sort the data using several filters. For example, you’ll be able to see which URLs have been accessed most frequently by Googlebot.
You’ll also be able to see if Googlebot has been accessing non-essential or low-value URLs such as faceted navigation URLs, duplicate URLs, etc. Identifying these is important as they are wasting your crawl budget.
Look at the below screenshot, taken from Screaming Frog’s SEO Log File Analyser, to see what we mean.
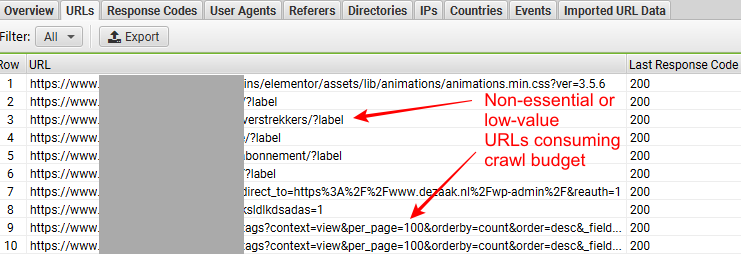
GSC provides website owners with comprehensive data and insights about how Google crawls their content. This includes detailed reports on:
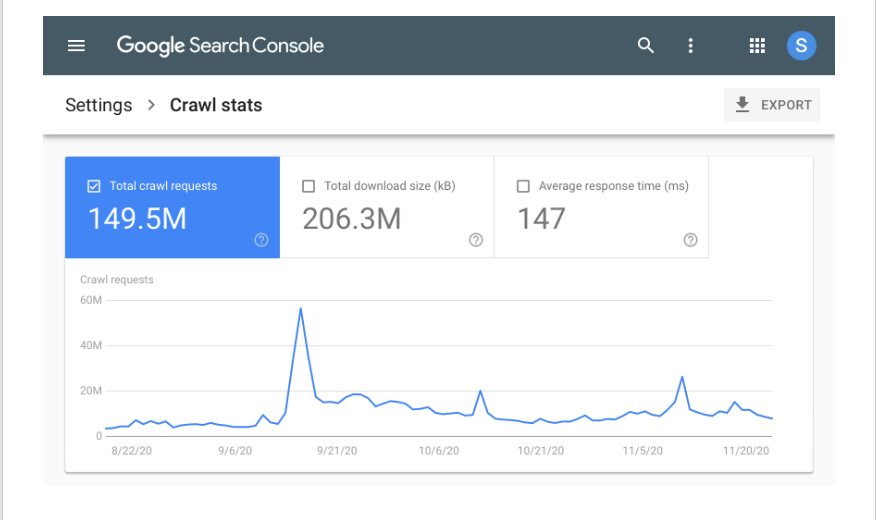
GSC also makes available easy to understand graphs and charts to provide website owners with even more information. The screenshot below is what a typical crawl stats report on GSC looks like.
The GSC also lets you know if there are any issues with crawling. It checks for several errors and assigns each a code. The most common errors that GSC checks for include:
The GSC report also shows how many pages have been affected by each error alongside the validation status.
How To Do This
Here’s how you can access the GSC crawl stats report for your website or web page:
These include:
We now know that crawl budget is a valuable resource whose use must be optimized for best results. Here are a few techniques to do this:
Duplicate content may end up being crawled separately, leading to a wastage of crawl budget. To avoid this from happening, either consolidate duplicate pages on your website into one, or delete duplicate pages.
Robots.txt is a file that serves a number of purposes, one of which is to tell Googlebot not to crawl certain pages or sections of pages. This is an important strategy that can be used to prevent Googlebot from crawling low-value content or content that doesn’t need crawling.
Here are a few best practices when using robots.txt to optimize crawl budget:
How To Do This
Creating and executing a robots.txt file to restrict Googlebot access requires some coding knowledge. Here are the steps involved:
A typical robots.txt file will have the following elements:
Below is what a simple robots.txt file looks like.
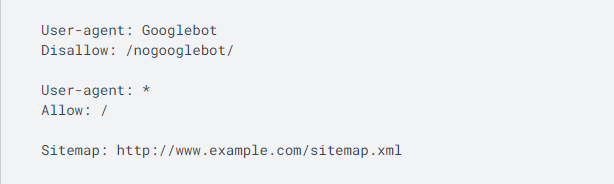
This code means that a user agent — Googlebot in this instance — is not allowed to crawl any URL that begins with “http://www.example.com/nogooglebot/”.
We suggest seeking expert help if you don’t feel comfortable creating and uploading robots.txt files yourself.
A crawl bot arrives at a site with a general allocation of how many pages it will crawl. The XML sitemap effectively directs the bot to read selected URLs, ensuring the effective use of that budget.
Note that a page’s ranking performance depends on several factors including content quality and internal/external links. Consider including only top-tier pages in the map. Images can be allocated their own XML sitemap.
Follow these recommendations to ensure optimal XML sitemap implementation:
For a more detailed look at sitemaps, refer to our dedicated module on this topic.
Internal links perform three important functions:
Thus for efficient crawling, it is important to implement an efficient internal linking strategy. For more on internal linking, refer to our detailed course module here.
If a website runs on a shared hosting platform, crawl budget will be shared with other websites running on said platform. A large publisher may find independent hosting to be a valuable alternative.
Prior to upgrading your hosting to resolve bot traffic overload, there are some factors worth considering that might impact server loads otherwise.
For more on the advantages of CDNs, check out our page experience module.
When Googlebot lands on a web page it renders all the assets on said page, including Javascript. While crawling HTML is rather straightforward, Googlebot must process Javascript a number of times in order to be able to render it and understand its content.
This can quickly drain Google’s crawl budget for a website. The solution is to implement Javascript rendering on the server side.
How To Do This
Addressing Javascript in your website’s source code requires coding expertise and we recommend consulting a web developer if you plan to make any such changes. That said, here are a few guidelines on what to look for when trying to optimize the use of Javascript.
CWVs are a measure of page performance that directly affects how your page performs in search rankings.
The GSC’s CWV report groups URL performance under three categories:
CWVs can also impact your crawl budget. For example, slow loading pages can eat up into your crawl budget as Google has a limited amount of time for crawling tasks. If your pages load fast, Google can crawl more of them within the limited time it has. Similarly, too many error status reports can slow crawling down and waste your crawl budget.
For a more thorough examination of CWVs, see our module on page experience.
A third-party crawler such as Semrush, Sitechecker.pro or Screaming Frog allows web developers to audit all of a site’s URLs and identify potential issues.
Third-party crawlers can be used to identify:
These programs offer a crawl stats report to help highlight problems that Google’s own tools may not.
Improving structured data and cutting down on hygiene issues will streamline Googlebot’s job of crawling and indexing a site.
We recommend the following best practices when using third-party crawlers:
URL parameters — the section of the web address that follows the “?” — are used on a page for a variety of reasons, including filtering, pagination and searching.
While this can boost the user experience, it can also cause crawling issues when both the base URL and one with parameters return the same content. An example of this would be “http://mysite.com” and “http://mysite.com?id=3” returning the exact same page.
Parameters allow a site to have a near unlimited number of links — such as when a user can select days, months and years on a calendar. If the bot is allowed to crawl these pages, the crawl budget will be used up needlessly.
This can especially be an issue for concern if your website uses faceted navigation or session identifiers that can spawn multiple duplicate pages which, if crawled, could lead to a wastage of crawl budget.
Duplicate URLs can also result if you have localized versions of your webpage in different languages, and the content on these pages has not been translated.
We recommend the following to address this:
Here’s how a simple <hreflang> looks like in your source code:
<link rel=”alternate” hreflang=”es-mx” href=”https://examplesite.com/news/hreflang-tags”/>
This tells the crawler that the specified URL is a Spanish (Mexican) variant of the main URL, and it should not be treated as a duplicate.
We’ve discussed the essentials of crawl budget management. The pointers listed in this section, though not critical to healthy crawl budget management, go a long way toward supplementing the techniques discussed previously.
A crawling emergency occurs when Googlebot overwhelms your website with more crawl requests than it can handle. It’s important to identify the issue as quickly as possible, which can be done by closely monitoring server logs and crawl stats in Google Search Console.
If a sudden surge in crawling is not managed in time, it could cause the server to slow down. Server slowdown would increase the average response time for crawlers and, as a result of this high response time, search engines will automatically reduce their crawl rate. This is problematic because reduced crawl rates will lead to a loss in visibility, with new articles not being crawled immediately.
If you notice over crawling is taxing your servers, here a few things you can do:
Google has sophisticated algorithms that control the crawl rate. So ideally, one should not tamper with the crawl rate. However, in an emergency situation, you can log into your GSC account and navigate to Crawl Rate Settings for your property.
If you see the crawl rate there as Calculated As Optimal, you won’t be able to change it manually. A special request needs to be filed with Google to change the crawl rate.
If this isn’t the case, you can simply change the crawl rate yourself to your desired value. This value will stay valid for 90 days.
If you do not wish to tamper with crawl rates in the GSC, you can also block access to the page by Googlebot using robots.txt. The procedure to do this has been explained previously.
It can take Google up to three days to crawl most sites. The only exceptions are news sites or other sites that publish time-sensitive content which may be crawled daily.
To check how frequently your pages are being crawled, monitor your site log. If you still feel your content is not being crawled as frequently as it should be, follow these steps:
https://www.google.com/ping?sitemap=FULL_URL_OF_SITEMAP
Please note: This step should be viewed as the last action anyone should take as it carries a certain degree of risk. If Googlebot sees 503 and 429 errors then it will start to crawl slower and may stop the crawling, leading to a temporary drop in the number of indexed pages.
A 503 error code means that the server is temporarily down, while 429 means that a user has sent too many requests in a specific amount of time. These codes let Googlebot know that the problem is temporary, and it should return to crawl the page at a later time.
Although a seemingly minor step, this is important because if Googlebot doesn’t know the nature of the problem a web page is experiencing, it assumes the problem is of a long-term nature and may mark the page down as being unresponsive, which can affect SEO.
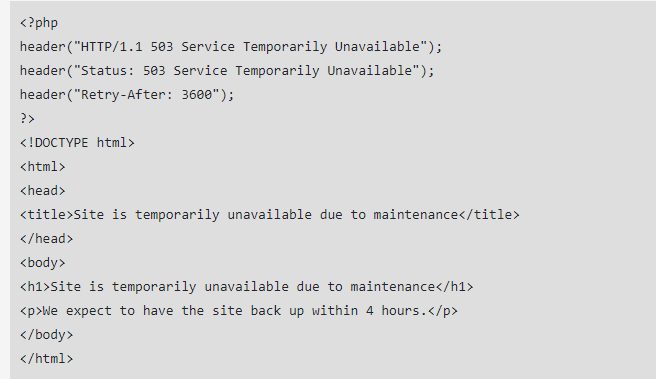
Creating 503 error codes is done through a PHP file, which is inserted within the existing HTML source code of your page along with an error message. You’ll also need to write a few additional lines of HTML code mentioning when the site is expected to return.
This is what the code for a 503 redirect looks like:
Doing 503 or 429 redirects requires advanced HTML coding skills and we suggest consulting with your web developer before attempting this.
We now have a good understanding of what a crawl budget is and how to optimize it. However, knowing what not to do when it comes to crawl budgets is equally important.
Here are some common pitfalls to avoid to ensure you get the most out of your website’s crawl budget:
The frequency with which Google crawls your website is determined by its algorithms, which take into account several signals to arrive at an optimal crawl frequency.
Increasing the crawl rate does not necessarily lead to better positions in search results. Crawling frequency or even crawling itself is not a ranking factor in and of itself.
Google does not necessarily prefer fresher content over older content. Google ranks pages based on the relevance and quality of the content irrespective of whether it is old or new. So, it is not necessary to keep having them crawled.
The crawl-delay directive does not help to control Googlebot. If you wish to slow down crawling frequency in response to excessive crawling that is overwhelming your website, refer to the instructions provided in the section above.
Your website’s loading speed can affect your crawl budget. A fast loading page means Google can access more information over the same number of connections.
For tips on loading speed optimization, check out our module on page experience.
Nofollow links may still end up affecting your crawl budget as these may still end up being crawled. On the other hand, links that robots.txt have disallowed have no effect on crawl budget.
Also, alternate URLs and Javascript content may end up being crawled, consuming your crawl budget, so it’s important to restrict access to them by either removing them or by using robots.txt.
Crawl budget is a valuable resource and it’s critical that you optimize for it. Crawling and indexing issues can affect the performance of your content, especially if your website has a large number of pages.
The two most fundamental operations involved in optimizing crawl budget are keeping your sitemap updated and regularly monitoring indexing issues from the GSC crawl stats report and log files.
It’s important to learn how to apply crawl management best practices both during the rollout of new website features and also when one-off errors happen.