Mga taktika sa paglago ng publisher para sa panahon ng eleksyon | WEBINAR


2.6.1 Ano ang Badyet sa Pag-crawl?
Ang crawl budget ay ang bilang ng mga pahina sa iyong website na maaaring i-crawl ng isang web crawler sa loob ng isang takdang panahon.
Sa bawat pagpindot mo sa button na "publish", kailangang i-crawl at i-index ng Google ang nilalaman para magsimula itong lumabas sa mga resulta ng paghahanap. Dahil sa laki at dami ng nilalaman sa internet, ang pag-crawl ay nagiging isang mahalagang mapagkukunan na kailangang badyetin at i-rasyon para sa pinakaepektibong paggamit.
Sa madaling salita, mahirap para sa Google na i-crawl at i-index ang bawat pahina sa internet araw-araw. Kaya naman, kino-crawl ng Google ang bawat website ayon sa nakatakdang badyet nito.
Ang badyet sa pag-crawl ay itinatalaga sa mga website batay sa dalawang salik — limitasyon sa pag-crawl at demand sa pag-crawl.
Ito ang kapasidad at/o kahandaan ng isang website na ma-crawl.
Hindi lahat ng website ay ginawa para i-crawl araw-araw. Ang pag-crawl ay nagsasangkot ng pagpapadala ng Googlebot ng mga kahilingan sa server ng iyong website na, kung gagawin nang masyadong madalas, ay maaaring maka-stress sa kapasidad ng server.
Gayundin, hindi lahat ng publisher ay gustong patuloy na ma-crawl ang kanilang site.
Ang crawl demand ay isang sukatan kung gaano kadalas gustong (muling) ma-crawl ang isang partikular na pahina. Ang mga sikat na pahina o mga pahinang madalas na ina-update ay kailangang ma-crawl at ma-recrawl nang mas madalas.
Kung hindi ma-crawl at ma-index ng Google ang iyong nilalaman, hindi talaga lalabas ang nilalamang iyon sa mga resulta ng paghahanap.
Gayunpaman, ang mga crawl budget sa pangkalahatan ay para lamang sa mga katamtaman hanggang malalaking publisher na may mahigit 10,000 pahina sa kanilang website. Hindi na kailangang mag-alala nang labis ang mas maliliit na publisher tungkol sa mga crawl budget.
Gayunpaman, gugustuhin ng mga publisher na may 10,000 o higit pang pahina sa kanilang website na iwasan ang mga pag-crawl ng Googlebot na hindi mahalaga. Ang pag-ubos ng iyong badyet sa pag-crawl sa mga hindi nauugnay o hindi gaanong mahalagang nilalaman ay nangangahulugan na ang mga pahinang may mas mataas na halaga ay maaaring hindi ma-crawl.
Bukod dito, gugustuhin ng mga tagapaglathala ng balita na maging maingat sa mga nasasayang na badyet sa pag-crawl dahil ang pag-crawl ay isa sa tatlong paraan kung paano natutuklasan ng Google News ang mga bagong nilalaman sa napapanahong paraan. Ang dalawa pa ay sa pamamagitan ng paggamit ng mga sitemap at Google Publisher Center, na aming sinuri pa sa aming mga module ng Google News Sitemap at Google Publisher Center.
Ang pag-optimize sa dalas at bilis ng pag-crawl ng Googlebot sa iyong website ay kinabibilangan ng pagsubaybay sa iba't ibang baryabol. Magsisimula tayo sa paglilista ng mga pinakamahalagang salik na kasangkot sa pag-optimize ng badyet at dalas ng pag-crawl.
Ang dalawang pinakakapaki-pakinabang na taktika para sa pagsubaybay kung paano kino-crawl ang iyong nilalaman ay ang pagsusuri ng mga log file at ang ulat ng mga istatistika ng pag-crawl ng Google Search Console (GSC).
Ang log file ay isang text document na nagtatala ng bawat aktibidad sa server ng iyong website. Kabilang dito ang lahat ng data tungkol sa mga crawl request, page request, image request, javascript file at anumang iba pang resource na kailangan para patakbuhin ang iyong website.
Para sa mga layunin ng teknikal na SEO, ang pagsusuri ng log file ay nakakatulong upang matukoy ang maraming kapaki-pakinabang na impormasyon tungkol sa pag-crawl ng URL, kabilang ngunit hindi limitado sa:
Paano Ito Gawin
Ang pagsusuri ng log file ay isang gawain na nangangailangan ng kaunting kaalaman sa teknikal na aspeto ng backend ng isang website. Dahil dito, inirerekomenda namin ang paggamit ng log file analyzer software. Mayroong ilang libre at bayad na mga tool sa pagsusuri ng log na magagamit tulad ng Graylog , Loggly , Elastic Stack , Screaming Frog Log Analyzer at Nagios, ilan lamang sa mga ito ang mga halimbawa.
Kung ikaw ay isang bihasang developer o system administrator, maaari ka ring manu-manong magsagawa ng pagsusuri ng log file.
Para gawin ito, sundin ang mga hakbang na ito:
Kapag na-download mo na ang log file, maaari mong baguhin ang extension sa .csv at buksan ito gamit ang Microsoft Excel o Google Sheets. Gayunpaman, gaya ng sinabi namin, ang pamamaraang ito ay nangangailangan ng isang tiyak na antas ng kadalubhasaan upang maunawaan ang log file.
Maaari mo ring ma-access ang log file gamit ang isang FTP client sa pamamagitan ng paglalagay ng path ng log file. Ganito ang hitsura ng isang karaniwang path ng log file:
Pangalan ng server (halimbawa, Apache) /var/log/access.log
Gayunpaman, mas maginhawang gumamit ng log analysis tool. Kapag na-upload mo na ang log file sa tool, maaari mong ayusin ang data gamit ang ilang filter. Halimbawa, makikita mo kung aling mga URL ang pinakamadalas na na-access ng Googlebot.
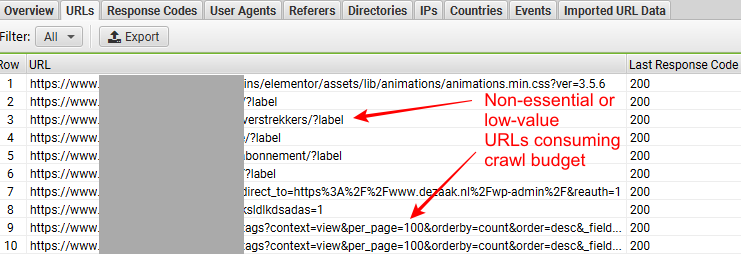
Makikita mo rin kung ang Googlebot ay nag-a-access ng mga hindi mahahalaga o mababang halagang URL tulad ng mga faceted navigation URL, mga duplicate na URL, atbp. Mahalagang matukoy ang mga ito dahil sinasayang lang nila ang iyong crawl budget.
Tingnan ang screenshot sa ibaba, na kinuha mula sa SEO Log File Analyser ng Screaming Frog, para makita ang ibig naming sabihin.
Nagbibigay ang GSC sa mga may-ari ng website ng komprehensibong datos at mga pananaw tungkol sa kung paano kino-crawl ng Google ang kanilang nilalaman. Kabilang dito ang mga detalyadong ulat sa:
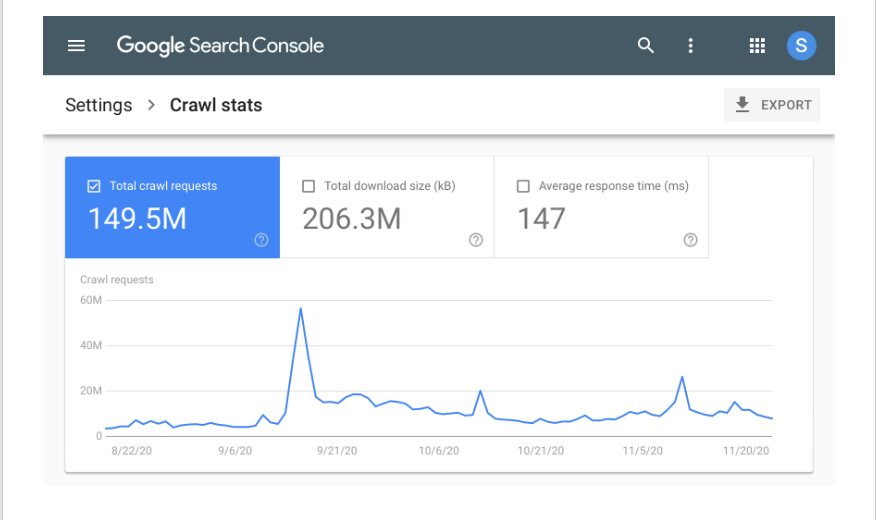
Nagbibigay din ang GSC ng mga graph at chart na madaling maunawaan upang mabigyan ang mga may-ari ng website ng mas maraming impormasyon. Ang screenshot sa ibaba ay kung ano ang hitsura ng isang karaniwang ulat ng crawl stats sa GSC.
Ipinapaalam din sa iyo ng GSC kung mayroong anumang mga isyu sa pag-crawl. Sinusuri nito ang ilang mga error at nagtatalaga ng bawat isa ng isang code. Ang mga pinakakaraniwang error na sinusuri ng GSC ay kinabibilangan ng:
Ipinapakita rin ng ulat ng GSC kung ilang pahina ang naapektuhan ng bawat error kasama ang katayuan ng pagpapatunay.
Paano Ito Gawin
Narito kung paano mo maa-access ang ulat ng mga istatistika ng pag-crawl ng GSC para sa iyong website o web page:
Kabilang dito ang:
Alam na natin ngayon na ang crawl budget ay isang mahalagang mapagkukunan na ang paggamit ay dapat i-optimize para sa pinakamahusay na mga resulta. Narito ang ilang mga pamamaraan upang gawin ito:
Ang mga duplicate na nilalaman ay maaaring ma-crawl nang hiwalay, na hahantong sa pag-aaksaya ng badyet sa pag-crawl. Upang maiwasan ito, pagsamahin ang mga duplicate na pahina sa iyong website sa isa, o burahin ang mga duplicate na pahina.
Ang Robots.txt ay isang file na may iba't ibang layunin, isa na rito ang pagsabi sa Googlebot na huwag i-crawl ang ilang partikular na pahina o seksyon ng mga pahina. Ito ay isang mahalagang estratehiya na magagamit upang maiwasan ang Googlebot sa pag-crawl ng mababang halagang nilalaman o nilalamang hindi kailangang i-crawl.
Narito ang ilang pinakamahuhusay na kagawian kapag ginagamit ang robots.txt para ma-optimize ang crawl budget:
Paano Ito Gawin
Ang paggawa at pagpapatakbo ng robots.txt file upang paghigpitan ang access ng Googlebot ay nangangailangan ng kaunting kaalaman sa coding. Narito ang mga hakbang na kasama:
Ang isang karaniwang robots.txt file ay magkakaroon ng mga sumusunod na elemento:
Nasa ibaba ang hitsura ng isang simpleng robots.txt file.
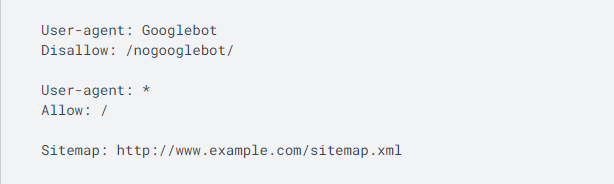
Ang ibig sabihin ng code na ito ay ang isang user agent — ang Googlebot sa pagkakataong ito — ay hindi pinapayagang mag-crawl ng anumang URL na nagsisimula sa " http://www.example.com/nogooglebot/ ".
Iminumungkahi namin na humingi ka ng tulong mula sa eksperto kung hindi ka komportable sa paggawa at pag-upload ng mga robots.txt file nang mag-isa.
Dumarating ang isang crawl bot sa isang site na may pangkalahatang alokasyon kung ilang pahina ang iko-crawl nito. Epektibong idinidirekta ng XML sitemap ang bot upang basahin ang mga napiling URL, na tinitiyak ang epektibong paggamit ng badyet na iyon.
Tandaan na ang performance ng ranggo ng isang pahina ay nakadepende sa ilang salik kabilang ang kalidad ng nilalaman at mga internal/external na link. Isaalang-alang ang pagsasama lamang ng mga top-tier na pahina sa mapa. Maaaring italaga ang mga larawan sa sarili nilang XML sitemap.
Sundin ang mga rekomendasyong ito upang matiyak ang pinakamainam na pagpapatupad ng XML sitemap:
Para sa mas detalyadong pagtingin sa mga sitemap, sumangguni sa aming nakalaang modyul sa paksang ito .
Ang mga panloob na link ay gumaganap ng tatlong mahahalagang tungkulin:
Kaya naman para sa mahusay na pag-crawl, mahalagang ipatupad ang isang mahusay na estratehiya sa internal linking. Para sa karagdagang impormasyon tungkol sa internal linking, sumangguni sa aming detalyadong modyul ng kurso dito.
Kung ang isang website ay tumatakbo sa isang shared hosting platform, ang crawl budget ay ibabahagi sa iba pang mga website na tumatakbo sa nasabing platform. Maaaring makita ng isang malaking publisher na isang mahalagang alternatibo ang independent hosting.
Bago i-upgrade ang iyong hosting upang malutas ang labis na trapiko sa bot, may ilang mga salik na dapat isaalang-alang na maaaring makaapekto sa mga load ng server.
Para sa higit pang impormasyon tungkol sa mga bentahe ng mga CDN, tingnan ang aming modyul ng karanasan sa pahina .
Kapag napunta ang Googlebot sa isang web page, nire-render nito ang lahat ng asset sa nasabing page, kabilang ang Javascript. Bagama't medyo simple lang ang pag-crawl sa HTML, kailangang iproseso ng Googlebot ang Javascript nang ilang beses upang ma-render ito at maunawaan ang nilalaman nito.
Mabilis nitong mauubos ang crawl budget ng Google para sa isang website. Ang solusyon ay ang pagpapatupad ng Javascript rendering sa server side.
Paano Ito Gawin
Ang pag-address sa Javascript sa source code ng iyong website ay nangangailangan ng kadalubhasaan sa coding at inirerekomenda namin ang pagkonsulta sa isang web developer kung plano mong gumawa ng anumang mga pagbabago. Gayunpaman, narito ang ilang mga alituntunin kung ano ang dapat hahanapin kapag sinusubukang i-optimize ang paggamit ng Javascript.
Ang mga CWV ay isang sukatan ng performance ng pahina na direktang nakakaapekto sa performance ng iyong pahina sa mga ranggo sa paghahanap.
Pinagsasama-sama ng ulat ng CWV ng GSC ang pagganap ng URL sa ilalim ng tatlong kategorya:
Maaari ring makaapekto ang mga CWV sa iyong badyet sa pag-crawl. Halimbawa, ang mabagal na pag-load ng mga pahina ay maaaring makaubos sa iyong badyet sa pag-crawl dahil limitado ang oras ng Google para sa mga gawain sa pag-crawl. Kung mabilis na naglo-load ang iyong mga pahina, mas marami pang maaaring i-crawl ng Google ang mga ito sa loob ng limitadong oras na mayroon ito. Gayundin, ang napakaraming ulat ng katayuan ng error ay maaaring magpabagal sa pag-crawl at masayang ang iyong badyet sa pag-crawl.
Para sa mas masusing pagsusuri sa mga CWV, tingnan ang aming karanasan sa pahina ng modyul .
Ang isang third-party crawler tulad ng Semrush , Sitechecker.pro o Screaming Frog ay nagbibigay-daan sa mga web developer na i-audit ang lahat ng URL ng isang site at tukuyin ang mga potensyal na isyu.
Maaaring gamitin ang mga third-party crawler upang matukoy ang:
Nag-aalok ang mga programang ito ng ulat ng mga istatistika ng pag-crawl upang makatulong na i-highlight ang mga problemang maaaring hindi matukoy ng mga tool ng Google mismo.
Ang pagpapabuti ng nakabalangkas na datos at pagbabawas sa mga isyu sa kalinisan ay magpapadali sa trabaho ng Googlebot sa pag-crawl at pag-index ng isang site.
Inirerekomenda namin ang mga sumusunod na pinakamahusay na kasanayan kapag gumagamit ng mga third-party crawler:
Ang mga parameter ng URL — ang seksyon ng web address na kasunod ng "?" — ay ginagamit sa isang pahina para sa iba't ibang dahilan, kabilang ang pag-filter, pagination, at paghahanap.
Bagama't mapapahusay nito ang karanasan ng gumagamit, maaari rin itong magdulot ng mga isyu sa pag-crawl kapag ang parehong base URL at ang isa na may mga parameter ay nagbabalik ng parehong nilalaman. Ang isang halimbawa nito ay ang "http://mysite.com" at "http://mysite.com?id=3" na nagbabalik ng eksaktong parehong pahina.
Ang mga parameter ay nagpapahintulot sa isang site na magkaroon ng halos walang limitasyong bilang ng mga link — tulad ng kung kailan maaaring pumili ang isang user ng mga araw, buwan at taon sa isang kalendaryo. Kung papayagan ang bot na i-crawl ang mga pahinang ito, ang badyet sa pag-crawl ay mauubos nang hindi kinakailangan.
Maaari itong maging isang isyu na dapat ipag-alala lalo na kung ang iyong website ay gumagamit ng faceted navigation o session identifiers na maaaring magdulot ng maraming duplicate na pahina na, kung iko-crawl, ay maaaring humantong sa pag-aaksaya ng badyet sa pag-crawl.
Maaari ring magresulta ang mga duplicate na URL kung mayroon kang mga naisalokal na bersyon ng iyong webpage sa iba't ibang wika, at ang nilalaman sa mga pahinang ito ay hindi pa naisalin.
Inirerekomenda namin ang mga sumusunod upang matugunan ito:
Narito kung paano ang isang simpleng<hreflang> ganito ang hitsura sa iyong source code:
https://examplesite.com/news/hreflang-tags”/ >
Sinasabi nito sa crawler na ang tinukoy na URL ay isang Espanyol (Mehikanong) variant ng pangunahing URL, at hindi ito dapat ituring na isang duplicate.
Tinalakay na natin ang mga mahahalagang bagay sa pamamahala ng crawl budget. Ang mga payo na nakalista sa seksyong ito, bagama't hindi mahalaga sa malusog na pamamahala ng crawl budget, ay malaking tulong sa pagdaragdag sa mga pamamaraang tinalakay kanina.
Nangyayari ang crawling emergency kapag ang Googlebot ay naglalagay ng mas maraming crawl request sa iyong website kaysa sa kaya nitong hawakan. Mahalagang matukoy ang isyu sa lalong madaling panahon, na maaaring gawin sa pamamagitan ng masusing pagsubaybay sa mga server log at crawl stats sa Google Search Console.
Kung ang biglaang pagtaas ng bilang ng mga crawler ay hindi mapapamahalaan sa tamang oras, maaari itong maging sanhi ng pagbagal ng server. Ang pagbagal ng server ay magpapataas ng average na oras ng pagtugon para sa mga crawler at, bilang resulta ng mataas na oras ng pagtugon na ito, awtomatikong babawasan ng mga search engine ang kanilang crawl rate. Ito ay problematiko dahil ang nabawasang mga crawl rate ay hahantong sa pagkawala ng visibility, kung saan ang mga bagong artikulo ay hindi agad na mako-crawl.
Kung mapapansin mong nagpapabigat sa iyong mga server ang overcrawl, narito ang ilang bagay na maaari mong gawin:
May mga sopistikadong algorithm ang Google na kumokontrol sa crawl rate. Kaya mainam na huwag pakialaman ang crawl rate. Gayunpaman, sa isang emergency, maaari kang mag-log in sa iyong GSC account at pumunta sa Crawl Rate Settings para sa iyong property.
Kung makikita mo ang crawl rate doon bilang Calculated As Optimal, hindi mo ito mababago nang manu-mano. Kailangang maghain ng espesyal na kahilingan sa Google upang baguhin ang crawl rate.
Kung hindi ito ang kaso, maaari mo na lang baguhin ang crawl rate sa iyong nais na halaga. Ang halagang ito ay mananatiling may bisa sa loob ng 90 araw.
Kung ayaw mong pakialaman ang mga crawl rate sa GSC, maaari mo ring harangan ang access sa pahina gamit ang robots.txt. Ang pamamaraan para gawin ito ay naipaliwanag na dati.
Maaaring abutin ng hanggang tatlong araw ang Google para ma-crawl ang karamihan sa mga site. Ang mga eksepsiyon lamang ay ang mga site ng balita o iba pang mga site na naglalathala ng nilalamang sensitibo sa oras na maaaring ma-crawl araw-araw.
Para masuri kung gaano kadalas kino-crawl ang iyong mga pahina, subaybayan ang log ng iyong site. Kung sa tingin mo ay hindi pa rin kino-crawl nang madalas ang iyong nilalaman gaya ng nararapat, sundin ang mga hakbang na ito:
https://www.google.com/ping?sitemap=FULL_URL_OF_SITEMAP
Pakitandaan: Ang hakbang na ito ay dapat ituring na huling aksyon na dapat gawin ng sinuman dahil may dala itong tiyak na antas ng panganib. Kung makakita ang Googlebot ng mga error na 503 at 429, magsisimula itong mag-crawl nang mas mabagal at maaaring ihinto ang pag-crawl, na hahantong sa pansamantalang pagbaba sa bilang ng mga naka-index na pahina.
Ang 503 error code ay nangangahulugan na pansamantalang down ang server, habang ang 429 ay nangangahulugan na ang isang user ay nagpadala ng napakaraming request sa isang partikular na tagal ng panahon. Ipinapaalam ng mga code na ito sa Googlebot na ang problema ay pansamantala lamang, at dapat itong bumalik upang i-crawl ang pahina sa ibang pagkakataon.
Bagama't tila maliit na hakbang lamang, mahalaga ito dahil kung hindi alam ng Googlebot ang uri ng problemang nararanasan ng isang web page, ipinapalagay nito na ang problema ay pangmatagalan at maaaring markahan ang pahina bilang hindi tumutugon, na maaaring makaapekto sa SEO.
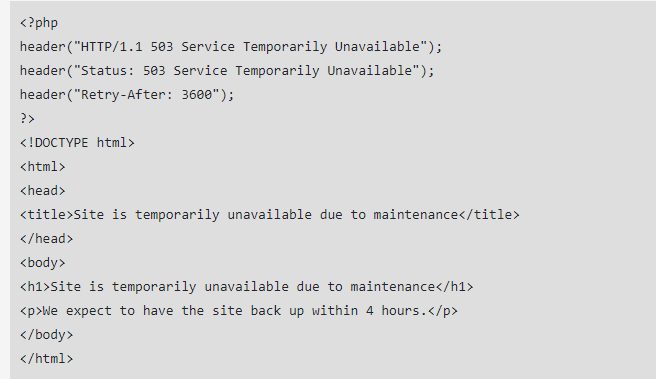
Ang paggawa ng 503 error codes ay ginagawa sa pamamagitan ng isang PHP file, na ipinapasok sa loob ng umiiral na HTML source code ng iyong pahina kasama ang isang mensahe ng error. Kakailanganin mo ring sumulat ng ilang karagdagang linya ng HTML code na binabanggit kung kailan inaasahang babalik ang site.
Ganito ang hitsura ng code para sa isang 503 redirect:
Ang paggawa ng 503 o 429 redirects ay nangangailangan ng mga advanced na kasanayan sa HTML coding at iminumungkahi naming kumonsulta ka muna sa iyong web developer bago ito subukan.
Mayroon na tayong mahusay na pag-unawa ngayon kung ano ang isang crawl budget at kung paano ito i-optimize. Gayunpaman, ang pag-alam kung ano ang hindi dapat gawin pagdating sa mga crawl budget ay pantay na mahalaga.
Narito ang ilang karaniwang patibong na dapat iwasan upang matiyak na masusulit mo ang badyet sa pag-crawl ng iyong website:
Ang dalas ng pag-crawl ng Google sa iyong website ay natutukoy ng mga algorithm nito, na isinasaalang-alang ang ilang signal upang makarating sa pinakamainam na dalas ng pag-crawl.
Ang pagtaas ng crawl rate ay hindi nangangahulugang hahantong sa mas magandang posisyon sa mga resulta ng paghahanap. Ang dalas ng pag-crawl o kahit ang pag-crawl mismo ay hindi isang salik sa pagraranggo sa ganang sarili nito.
Hindi naman kinakailangang mas gusto ng Google ang mas bagong nilalaman kaysa sa mas lumang nilalaman. Niraranggo ng Google ang mga pahina batay sa kaugnayan at kalidad ng nilalaman, luma man o bago. Kaya, hindi na kailangang patuloy na i-crawl ang mga ito.
Hindi nakakatulong ang crawl-delay directive sa pagkontrol sa Googlebot. Kung gusto mong pabagalin ang dalas ng pag-crawl bilang tugon sa labis na pag-crawl na nakakasagabal sa iyong website, sumangguni sa mga tagubiling ibinigay sa seksyon sa itaas.
Ang bilis ng paglo-load ng iyong website ay maaaring makaapekto sa iyong badyet sa pag-crawl. Ang mabilis na paglo-load ng pahina ay nangangahulugan na ang Google ay maaaring maka-access ng mas maraming impormasyon sa parehong bilang ng mga koneksyon.
Para sa mga tip sa pag-optimize ng bilis ng paglo-load, tingnan ang aming module on page experience .
Maaari pa ring makaapekto ang mga nofollow link sa iyong crawl budget dahil maaari pa rin itong ma-crawl. Sa kabilang banda, ang mga link na hindi pinayagan ng robots.txt ay walang epekto sa crawl budget.
Gayundin, maaaring ma-crawl ang mga alternatibong URL at nilalaman ng Javascript, na uubos sa iyong badyet sa pag-crawl, kaya mahalagang paghigpitan ang access sa mga ito sa pamamagitan ng pag-alis sa mga ito o paggamit ng robots.txt.
Ang badyet sa pag-crawl ay isang mahalagang mapagkukunan at mahalaga na i-optimize mo ito. Ang mga isyu sa pag-crawl at pag-index ay maaaring makaapekto sa pagganap ng iyong nilalaman, lalo na kung ang iyong website ay may maraming bilang ng mga pahina.
Ang dalawang pinakamahalagang operasyon na kasangkot sa pag-optimize ng crawl budget ay ang pagpapanatiling updated ng iyong sitemap at regular na pagsubaybay sa mga isyu sa pag-index mula sa ulat ng mga istatistika ng crawl ng GSC at mga log file.
Mahalagang matutunan kung paano ilapat ang mga pinakamahuhusay na kasanayan sa pamamahala ng pag-crawl kapwa sa panahon ng paglulunsad ng mga bagong tampok ng website at gayundin kapag may mga minsanang error na nangyayari.