Stratégies de croissance pour les éditeurs en période électorale | WEBINAIRE


2.6.1 Qu'est-ce qu'un budget d'exploration ?
Le budget d'exploration correspond au nombre de pages de votre site web qu'un robot d'exploration explorera dans un laps de temps donné.
Chaque fois que vous cliquez sur le bouton « Publier », Google doit explorer et indexer le contenu pour qu'il apparaisse dans les résultats de recherche. Compte tenu de l'ampleur et du volume du contenu sur Internet, l'exploration devient une ressource précieuse qui doit être budgétisée et utilisée de manière optimale.
En clair, il est difficile pour Google d'explorer et d'indexer chaque page web chaque jour. C'est pourquoi Google explore chaque site web en fonction du budget qui lui est alloué.
Le budget d'exploration est attribué aux sites web en fonction de deux facteurs : la limite d'exploration et la demande d'exploration.
Il s'agit de la capacité et/ou de la volonté d'un site web à être indexé.
Tous les sites web ne sont pas conçus pour être indexés quotidiennement. L'indexation consiste pour Googlebot à envoyer des requêtes au serveur de votre site web, ce qui, si ces requêtes sont trop fréquentes, peut surcharger la capacité du serveur.
De plus, tous les éditeurs ne souhaitent pas que leur site soit indexé en permanence.
La demande d'exploration mesure la fréquence à laquelle une page doit être explorée (et réexplorée). Les pages populaires ou fréquemment mises à jour nécessitent une exploration et une réexploration plus fréquentes.
Si Google ne peut pas explorer et indexer votre contenu, ce dernier n'apparaîtra tout simplement pas dans les résultats de recherche.
Cela dit, les budgets d'exploration ne concernent généralement que les éditeurs de taille moyenne à grande dont le site web compte plus de 10 000 pages. Les éditeurs plus petits n'ont pas à s'en préoccuper outre mesure.
Les éditeurs dont le site web compte 10 000 pages ou plus voudront éviter que Googlebot n'explore des pages non pertinentes. Consacrer tout leur budget d'exploration à du contenu non pertinent ou de moindre importance risque de priver d'exploration des pages à forte valeur ajoutée.
De plus, les éditeurs de presse devront veiller à ne pas gaspiller leur budget d'exploration, car l'exploration est l'un des trois moyens utilisés par Google Actualités pour découvrir rapidement du contenu récent. Les deux autres sont l'utilisation des sitemaps et de Google Publisher Center, que nous avons détaillés dans nos modules « Sitemap Google Actualités » et « Google Publisher Center ».
Optimiser la fréquence et la vitesse d'exploration de votre site web par Googlebot implique de surveiller plusieurs variables. Nous commençons par lister les facteurs les plus importants pour optimiser le budget et la fréquence d'exploration.
Les deux tactiques les plus utiles pour surveiller la façon dont votre contenu est exploré consistent à analyser les fichiers journaux et le rapport de statistiques d'exploration de Google Search Console (GSC).
Un fichier journal est un document texte qui enregistre toutes les activités sur le serveur de votre site web. Cela inclut toutes les données relatives aux requêtes d'exploration, aux requêtes de pages, aux requêtes d'images, aux requêtes de fichiers JavaScript et à toute autre ressource nécessaire au fonctionnement de votre site web.
Dans le cadre du référencement technique, l'analyse des fichiers journaux permet de déterminer de nombreuses informations utiles sur l'exploration des URL, notamment :
Comment faire cela
L'analyse des fichiers journaux exige une certaine connaissance technique du fonctionnement interne d'un site web. C'est pourquoi nous recommandons l'utilisation d'un logiciel d'analyse de fichiers journaux. Plusieurs outils d'analyse de journaux, gratuits ou payants, sont disponibles, tels que Graylog , Loggly , Elastic Stack , Screaming Frog Log Analyzer et Nagios, pour n'en citer que quelques-uns.
Si vous êtes un développeur ou un administrateur système expérimenté, vous pouvez également effectuer manuellement une analyse des fichiers journaux.
Pour ce faire, suivez ces étapes :
Une fois le fichier journal téléchargé, vous pouvez le convertir au format .csv et l'ouvrir avec Microsoft Excel ou Google Sheets. Toutefois, comme indiqué précédemment, cette méthode requiert une certaine expertise pour interpréter correctement le fichier journal.
Vous pouvez également accéder au fichier journal à l'aide d'un client FTP en saisissant son chemin d'accès. Un chemin d'accès typique pour un fichier journal ressemble à ceci :
Nom du serveur (par exemple, Apache) /var/log/access.log
Il est toutefois bien plus pratique d'utiliser un outil d'analyse de journaux. Une fois le fichier journal importé dans l'outil, vous pouvez trier les données à l'aide de plusieurs filtres. Par exemple, vous pourrez voir quelles URL ont été le plus souvent consultées par Googlebot.
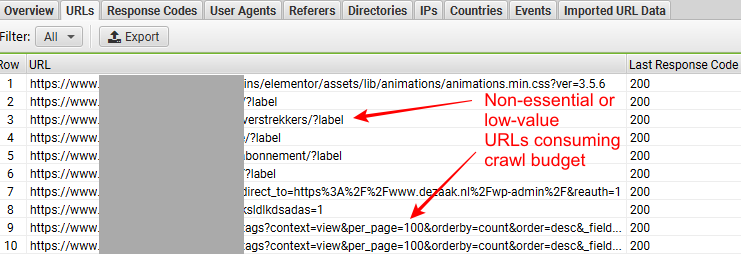
Vous pourrez également voir si Googlebot a accédé à des URL non essentielles ou de faible valeur, telles que les URL de navigation à facettes, les URL dupliquées, etc. Il est important de les identifier car elles gaspillent votre budget d'exploration.
Consultez la capture d'écran ci-dessous, extraite de l'outil d'analyse des fichiers journaux SEO de Screaming Frog, pour comprendre ce que nous voulons dire.
La Search Console fournit aux propriétaires de sites web des données et des analyses complètes sur la façon dont Google explore leur contenu. Cela inclut des rapports détaillés sur :
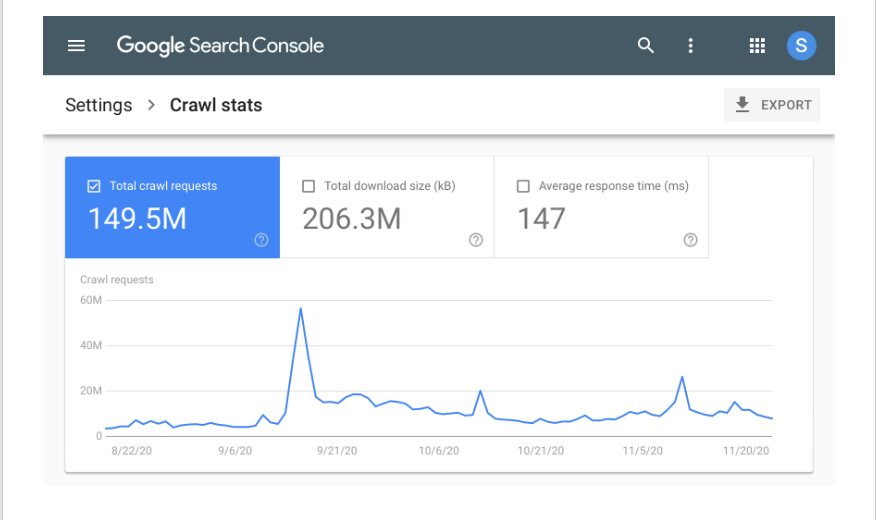
Google Search Console propose également des graphiques et des tableaux faciles à comprendre afin de fournir aux propriétaires de sites web encore plus d'informations. La capture d'écran ci-dessous illustre un exemple de rapport de statistiques d'exploration sur Search Console.
Le GSC vous informe également en cas de problème d'exploration. Il vérifie plusieurs erreurs et attribue un code à chacune. Les erreurs les plus courantes que le GSC vérifie sont les suivantes :
Le rapport GSC indique également le nombre de pages affectées par chaque erreur, ainsi que l'état de validation.
Comment faire cela
Voici comment accéder au rapport de statistiques d'exploration de la Search Console pour votre site web ou votre page web :
Cela comprend :
Nous savons désormais que le budget d'exploration est une ressource précieuse dont l'utilisation doit être optimisée pour obtenir les meilleurs résultats. Voici quelques techniques pour y parvenir :
Le contenu dupliqué risque d'être indexé séparément, ce qui entraîne un gaspillage du budget d'exploration. Pour éviter cela, regroupez les pages dupliquées de votre site web en une seule ou supprimez-les.
Le fichier robots.txt remplit plusieurs fonctions, notamment celle d'indiquer à Googlebot de ne pas explorer certaines pages ou sections de pages. Il s'agit d'une stratégie importante pour empêcher Googlebot d'explorer du contenu de faible valeur ou qui n'a pas besoin d'être exploré.
Voici quelques bonnes pratiques pour optimiser le budget d'exploration avec le fichier robots.txt :
Comment faire cela
La création et l'exécution d'un fichier robots.txt pour restreindre l'accès à Googlebot nécessitent certaines connaissances en programmation. Voici les étapes à suivre :
Un fichier robots.txt typique contient les éléments suivants :
Voici à quoi ressemble un fichier robots.txt simple.
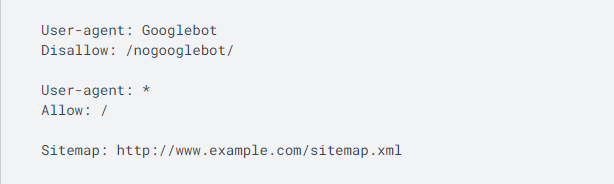
Ce code signifie qu'un agent utilisateur — Googlebot dans ce cas précis — n'est pas autorisé à explorer toute URL commençant par « http://www.example.com/nogooglebot/ ».
Nous vous suggérons de faire appel à un expert si vous ne vous sentez pas à l'aise pour créer et télécharger vous-même des fichiers robots.txt.
Un robot d'exploration arrive sur un site avec un nombre global de pages à explorer. Le sitemap XML lui indique précisément les URL à consulter, garantissant ainsi une utilisation optimale de ce budget.
Notez que le classement d'une page dépend de plusieurs facteurs, notamment la qualité du contenu et les liens internes/externes. Il est conseillé d'inclure uniquement les pages de premier niveau dans le sitemap. Les images peuvent avoir leur propre sitemap XML.
Suivez ces recommandations pour garantir une implémentation optimale du sitemap XML :
Pour une présentation plus détaillée des plans de site, consultez notre module dédié à ce sujet .
Les liens internes remplissent trois fonctions importantes :
Pour un référencement efficace, il est donc important de mettre en œuvre une stratégie de maillage interne performante. Pour en savoir plus sur le maillage interne, consultez notre module de cours détaillé ici.
Si un site web est hébergé sur une plateforme mutualisée, son budget d'exploration sera partagé avec les autres sites utilisant cette même plateforme. Un éditeur important pourrait trouver qu'un hébergement indépendant représente une alternative intéressante.
Avant de mettre à niveau votre hébergement pour résoudre le problème de la surcharge liée au trafic des robots, il convient de prendre en compte certains facteurs susceptibles d'avoir un impact sur la charge du serveur.
Pour en savoir plus sur les avantages des CDN, consultez notre module d'expérience utilisateur .
Lorsque Googlebot arrive sur une page web, il analyse tous les éléments de cette page, y compris le JavaScript. Si l'exploration du HTML est relativement simple, Googlebot doit traiter le JavaScript à plusieurs reprises afin de pouvoir l'interpréter et en comprendre le contenu.
Cela peut rapidement épuiser le budget d'exploration de Google pour un site web. La solution consiste à implémenter le rendu JavaScript côté serveur.
Comment faire cela
L'intégration de JavaScript dans le code source de votre site web requiert des compétences en programmation ; nous vous recommandons donc de consulter un développeur web si vous envisagez d'effectuer de telles modifications. Ceci étant dit, voici quelques conseils pour optimiser l'utilisation de JavaScript.
Les CWV (coefficients de variation du contenu) sont une mesure de la performance d'une page qui influe directement sur son classement dans les résultats de recherche.
Le rapport CWV du GSC classe les performances des URL en trois catégories :
Les CWV (Call-Time Values) peuvent également impacter votre budget d'exploration. Par exemple, les pages lentes à charger peuvent consommer votre budget d'exploration, car Google dispose d'un temps limité pour les tâches d'exploration. Si vos pages se chargent rapidement, Google peut en explorer davantage dans le temps imparti. De même, un trop grand nombre de rapports d'erreur peut ralentir l'exploration et gaspiller votre budget.
Pour un examen plus approfondi des CWV, consultez notre module sur l'expérience de la page .
Un outil d'exploration tiers tel que Semrush , Sitechecker.pro ou Screaming Frog permet aux développeurs web d'auditer toutes les URL d'un site et d'identifier les problèmes potentiels.
Des robots d'exploration tiers peuvent être utilisés pour identifier :
Ces programmes proposent un rapport de statistiques d'exploration permettant de mettre en évidence des problèmes que les outils de Google ne détectent pas forcément.
L'amélioration des données structurées et la réduction des problèmes d'hygiène permettront de simplifier le travail de Googlebot lors de l'exploration et de l'indexation d'un site.
Nous recommandons les bonnes pratiques suivantes lors de l'utilisation de robots d'exploration tiers :
Les paramètres d'URL — la partie de l'adresse web qui suit le « ? » — sont utilisés sur une page pour diverses raisons, notamment le filtrage, la pagination et la recherche.
Bien que cela puisse améliorer l'expérience utilisateur, cela peut également engendrer des problèmes d'exploration lorsque l'URL de base et celle avec paramètres renvoient le même contenu. Par exemple, « http://mysite.com » et « http://mysite.com?id=3 » renvoient exactement la même page.
Les paramètres permettent à un site d'avoir un nombre quasi illimité de liens, par exemple lorsqu'un utilisateur peut sélectionner des jours, des mois et des années sur un calendrier. Si le robot est autorisé à explorer ces pages, le budget d'exploration sera inutilement consommé.
Cela peut s'avérer particulièrement problématique si votre site web utilise une navigation à facettes ou des identifiants de session susceptibles de générer plusieurs pages dupliquées qui, si elles sont explorées, pourraient entraîner un gaspillage du budget d'exploration.
Des URL dupliquées peuvent également apparaître si vous avez des versions localisées de votre page Web dans différentes langues et que le contenu de ces pages n'a pas été traduit.
Nous recommandons les mesures suivantes pour remédier à ce problème :
Voici comment une simple<hreflang> Voici à quoi cela ressemble dans votre code source :
https://examplesite.com/news/hreflang-tags”/ >
Cela indique au robot d'exploration que l'URL spécifiée est une variante espagnole (mexicaine) de l'URL principale et qu'elle ne doit pas être considérée comme un doublon.
Nous avons abordé les points essentiels de la gestion du budget d'exploration. Les conseils présentés dans cette section, bien que non indispensables à une gestion efficace de ce budget, complètent avantageusement les techniques précédemment exposées.
Une urgence d'exploration survient lorsque Googlebot submerge votre site web de requêtes d'exploration, dépassant sa capacité. Il est crucial d'identifier le problème au plus vite, notamment en surveillant attentivement les journaux du serveur et les statistiques d'exploration dans Google Search Console.
Si une augmentation soudaine du trafic d'exploration n'est pas gérée à temps, le serveur risque de ralentir. Ce ralentissement augmenterait le temps de réponse moyen des robots d'exploration et, par conséquent, les moteurs de recherche réduiraient automatiquement leur fréquence d'exploration. Ceci est problématique car une fréquence d'exploration réduite entraînerait une perte de visibilité, les nouveaux articles n'étant pas indexés immédiatement.
Si vous constatez qu'un crawl excessif surcharge vos serveurs, voici quelques solutions :
Google utilise des algorithmes sophistiqués pour contrôler la fréquence d'exploration. Il est donc préférable de ne pas la modifier. Toutefois, en cas d'urgence, vous pouvez vous connecter à votre compte Google Search Console et accéder aux paramètres de fréquence d'exploration de votre propriété.
Si la fréquence d'exploration affichée est « Calculée comme optimale », vous ne pourrez pas la modifier manuellement. Une demande spécifique doit être soumise à Google pour la modifier.
Si ce n'est pas le cas, vous pouvez modifier vous-même la fréquence d'exploration à la valeur souhaitée. Cette valeur restera valable pendant 90 jours.
Si vous ne souhaitez pas modifier les taux d'exploration dans la Search Console, vous pouvez également bloquer l'accès à la page par Googlebot via le fichier robots.txt. La procédure à suivre a déjà été expliquée.
L'indexation de la plupart des sites par Google peut prendre jusqu'à trois jours. Seuls les sites d'actualités ou ceux publiant du contenu urgent font exception et peuvent être indexés quotidiennement.
Pour vérifier la fréquence d'exploration de vos pages, consultez les journaux de votre site. Si vous pensez que votre contenu n'est toujours pas exploré aussi fréquemment qu'il le devrait, suivez ces étapes :
https://www.google.com/ping?sitemap=URL_COMPLÈTE_DU_SITEMAP
Attention : cette étape doit être considérée comme la dernière action à entreprendre, car elle comporte un certain risque. Si Googlebot détecte des erreurs 503 et 429, son exploration ralentira et pourra s'interrompre, ce qui entraînera une baisse temporaire du nombre de pages indexées.
Un code d'erreur 503 signifie que le serveur est temporairement indisponible, tandis qu'un code 429 indique qu'un utilisateur a envoyé trop de requêtes dans un laps de temps donné. Ces codes informent Googlebot que le problème est temporaire et qu'il reviendra explorer la page ultérieurement.
Bien qu'il s'agisse d'une étape apparemment mineure, elle est importante car si Googlebot ne connaît pas la nature du problème rencontré par une page Web, il suppose que le problème est de longue durée et peut signaler que la page ne répond pas, ce qui peut affecter le référencement naturel.
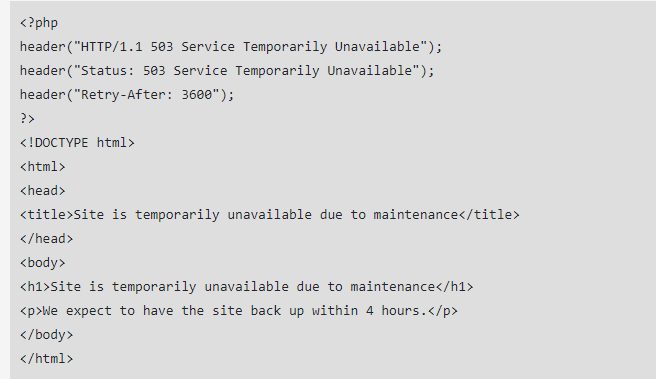
La création de codes d'erreur 503 se fait via un fichier PHP, inséré dans le code source HTML existant de votre page, accompagné d'un message d'erreur. Vous devrez également ajouter quelques lignes de code HTML indiquant quand le site est censé se recharger.
Voici à quoi ressemble le code d'une redirection 503 :
La mise en place de redirections 503 ou 429 nécessite des compétences avancées en codage HTML et nous vous suggérons de consulter votre développeur web avant de tenter cette opération.
Nous comprenons désormais bien ce qu'est un budget d'exploration et comment l'optimiser. Cependant, il est tout aussi important de savoir ce qu'il ne faut pas faire en matière de budget d'exploration.
Voici quelques pièges courants à éviter pour tirer le meilleur parti du budget d'exploration de votre site web :
La fréquence à laquelle Google explore votre site web est déterminée par ses algorithmes, qui prennent en compte plusieurs signaux pour parvenir à une fréquence d'exploration optimale.
Augmenter la fréquence d'exploration n'entraîne pas nécessairement un meilleur positionnement dans les résultats de recherche. La fréquence d'exploration, voire l'exploration elle-même, ne constitue pas un facteur de classement en soi.
Google ne privilégie pas nécessairement les contenus récents aux contenus plus anciens. Il classe les pages en fonction de la pertinence et de la qualité de leur contenu, qu'il soit récent ou ancien. Il n'est donc pas nécessaire de les faire indexer en permanence.
La directive crawl-delay ne permet pas de contrôler Googlebot. Si vous souhaitez réduire la fréquence d'exploration en cas d'exploration excessive qui surcharge votre site web, veuillez consulter les instructions de la section précédente.
La vitesse de chargement de votre site web peut avoir un impact sur votre budget d'exploration. Une page qui se charge rapidement permet à Google d'accéder à plus d'informations avec le même nombre de connexions.
Pour obtenir des conseils sur l'optimisation de la vitesse de chargement, consultez notre expérience avec les modules sur page .
Les liens nofollow peuvent tout de même impacter votre budget d'exploration, car ils peuvent être explorés malgré tout. En revanche, les liens interdits par le fichier robots.txt n'ont aucun impact sur ce budget.
De plus, les URL alternatives et le contenu Javascript peuvent être explorés, consommant ainsi votre budget d'exploration. Il est donc important d'en restreindre l'accès, soit en les supprimant, soit en utilisant le fichier robots.txt.
Le budget d'exploration est une ressource précieuse qu'il est essentiel d'optimiser. Les problèmes d'exploration et d'indexation peuvent impacter les performances de votre contenu, surtout si votre site web comporte un grand nombre de pages.
Les deux opérations les plus fondamentales pour optimiser le budget d'exploration consistent à maintenir votre sitemap à jour et à surveiller régulièrement les problèmes d'indexation à partir du rapport de statistiques d'exploration et des fichiers journaux de la Search Console.
Il est important d'apprendre à appliquer les meilleures pratiques de gestion des crawls aussi bien lors du déploiement de nouvelles fonctionnalités de site web que lors d'erreurs ponctuelles.