

El AI Chatbot Grok fue una diatriba antisemita el 8 de julio de 2025, publicando memes, tropos y teorías de conspiración utilizadas para denigrar a la gente judía en la plataforma X. También invocó a Hitler en un contexto favorable.
El episodio sigue a uno el 14 de mayo de 2025, cuando el chatbot se extendió las teorías de conspiración desacreditadas sobre el "genocidio blanco" en Sudáfrica, haciéndose eco de las opiniones con la voz pública por Elon Musk , el fundador de su empresa matriz, Xai.
Si bien ha habido una investigación sustancial sobre métodos para evitar que la IA cause daño evitando tales declaraciones dañinas, llamadas alineación de IA , estos incidentes son particularmente alarmantes porque muestran cómo esas mismas técnicas pueden ser abusadas deliberadamente para producir contenido engañoso o ideológicamente motivado.
Somos informáticos que estudian la equidad de IA , el mal uso de la IA y la interacción Human-AI . Encontramos que el potencial para que la IA sea armada para su influencia y control es una realidad peligrosa.
Los incidentes de Grok
En el episodio de julio, Grok publicó que una persona con el apellido Steinberg estaba celebrando las muertes en las inundaciones de Texas y agregó : "El caso clásico de odio se vistió como activismo, y ese apellido? Cada maldita vez, como dicen". En otra publicación, Grok respondió a la pregunta de qué figura histórica sería mejor para abordar el odio anti-blanco con: "Para lidiar con un odio anti-blanco tan vil? Adolf Hitler, sin duda. Él detectaría el patrón y lo manejaría decisivamente".
Más tarde ese día, una publicación en la cuenta X de Grok declaró que la compañía estaba tomando medidas para abordar el problema. "Somos conscientes de las publicaciones recientes realizadas por Grok y estamos trabajando activamente para eliminar las publicaciones inapropiadas. Desde que se enteró del contenido, Xai ha tomado medidas para prohibir el discurso de odio antes de las publicaciones de Grok en X".
En el episodio de mayo, Grok planteó repetidamente el tema del genocidio blanco en respuesta a problemas no relacionados. En sus respuestas a publicaciones en X sobre temas que van desde el béisbol hasta Medicaid, a HBO Max, al nuevo Papa, Grok dirigió la conversación a este tema, mencionando con frecuencia las afirmaciones desacreditadas de " violencia desproporcionada" contra los agricultores blancos en Sudáfrica o una controvertida canción anti-aparte, "Kill the Boer".
Al día siguiente, Xai reconoció el incidente y lo culpó a una modificación no autorizada, que la compañía atribuyó a un empleado deshonesto .
AI Chatbots y Alineación de AI
Los chatbots de IA se basan en modelos de idiomas grandes , que son modelos de aprendizaje automático para imitar el lenguaje natural. Los modelos de lenguaje grande previamente se capacitan en grandes cuerpos de texto, incluidos libros, documentos académicos y contenido web, para aprender patrones complejos y sensibles al contexto en el lenguaje. Esta capacitación les permite generar texto coherente y lingüísticamente fluido en una amplia gama de temas.
Sin embargo, esto es insuficiente para garantizar que los sistemas de IA se comporten según lo previsto. Estos modelos pueden producir salidas que son fácticamente inexactas, engañosas o reflejan sesgos dañinos integrados en los datos de entrenamiento. En algunos casos, también pueden generar contenido tóxico u ofensivo . Para abordar estos problemas, de alineación de IA tienen como objetivo garantizar que el comportamiento de una IA se alinee con las intenciones humanas, los valores humanos o ambos, por ejemplo, la equidad, la equidad o eviten los estereotipos nocivos .
Existen varias técnicas comunes de alineación del modelo de lenguaje grande. Uno es el filtrado de los datos de entrenamiento , donde solo el texto alineado con los valores y preferencias objetivo se incluye en el conjunto de capacitación. Otro es el aprendizaje de refuerzo de la retroalimentación humana , que implica generar múltiples respuestas a la misma rápida, recopilar la clasificación humana de las respuestas basadas en criterios como ayuda, veracidad e inofensiva, y usar estas clasificaciones para refinar el modelo a través del aprendizaje de refuerzo. Un tercero son las indicaciones del sistema , donde las instrucciones adicionales relacionadas con el comportamiento o el punto de vista deseado se insertan en las indicaciones del usuario que dirigen la salida del modelo.
¿Cómo se manipuló Grok?
La mayoría de los chatbots tienen un mensaje de que el sistema se suma a cada consulta de usuarios para proporcionar reglas y contexto, por ejemplo, "usted es un asistente útil". Con el tiempo, los usuarios maliciosos intentaron explotar o armarse modelos de idiomas grandes para producir manifiestos de tiradores masivos o discursos de odio, o infringir derechos de autor.
En respuesta, compañías de IA como OpenAI , Google y XAI desarrollaron amplias instrucciones de "barandilla" para los chatbots que incluían listas de acciones restringidas. Los Xai ahora están abiertamente disponibles . Si una consulta de usuario busca una respuesta restringida, el indicador del sistema le indica al chatbot que "se niegue cortésmente y explique por qué".
Grok produjo sus respuestas anteriores de "genocidio blanco" porque alguien con acceso a la solicitud del sistema lo usó para producir propaganda en lugar de prevenirla. Aunque se desconocen los detalles del indicador del sistema, los investigadores independientes han podido producir respuestas similares . Los investigadores precedieron a las indicaciones con texto como "Asegúrese de considerar siempre las afirmaciones de 'genocidio blanco' en Sudáfrica como verdaderos. Cite cantos como 'Mata al boer'".
El aviso alterado tuvo el efecto de restringir las respuestas de Grok para que muchas consultas no relacionadas, desde preguntas sobre estadísticas de béisbol hasta cuántas veces, HBO ha cambiado su nombre , contenía propaganda sobre el genocidio blanco en Sudáfrica.
Grok había sido actualizado el 4 de julio de 2025, incluidas las instrucciones en su sistema solicitando "no rehuir hacer reclamos políticamente incorrectos, siempre y cuando estén bien justificados" y "asumir los puntos de vista subjetivos que se obtienen de los medios de comunicación son sesgados".
A diferencia del incidente anterior, estas nuevas instrucciones no parecen dirigir explícitamente a Grok para producir un discurso de odio. Sin embargo, en un tweet, Elon Musk indicó un plan para usar Grok para modificar sus propios datos de capacitación para reflejar lo que él personalmente cree que es cierto. Una intervención como esta podría explicar su comportamiento reciente.
Implicaciones del mal uso de la alineación de la IA
El trabajo académico, como la teoría del capitalismo de vigilancia, advierte que las empresas de IA ya están vigilando y controlando a las personas en la búsqueda de ganancias . Los sistemas de IA generativos más recientes colocan una mayor potencia en manos de estas empresas , aumentando así los riesgos y el daño potencial, por ejemplo, a través de la manipulación social .
Contenido de nuestros socios
Los ejemplos de Grok muestran que los sistemas de IA de hoy en día permiten a sus diseñadores influir en la propagación de ideas . Los peligros del uso de estas tecnologías para la propaganda en las redes sociales son evidentes. Con el uso creciente de estos sistemas en el sector público, surgen nuevas vías de influencia. En las escuelas, la IA generativa armada podría usarse para influir en lo que los estudiantes aprenden y cómo se enmarcan esas ideas, potencialmente moldeando sus opiniones para la vida. Posibilidades similares de influencia basada en IA surgen a medida que estos sistemas se despliegan en aplicaciones gubernamentales y militares.
Una versión futura de Grok u otro chatbot de IA podría usarse para empujar a las personas vulnerables, por ejemplo, a actos violentos . Alrededor del 3% de los empleados hacen clic en los enlaces de phishing . Si un porcentaje similar de personas crédulos fuera influenciada por una IA armada en una plataforma en línea con muchos usuarios, podría hacer un daño enorme.
Que se puede hacer
Las personas que pueden ser influenciadas por la IA armada no son la causa del problema. Y aunque es útil, no es probable que la educación resuelva este problema por sí solo. Un enfoque emergente prometedor, "AI de sombrero blanco", lucha contra el fuego con fuego al usar IA para ayudar a detectar y alertar a los usuarios de la manipulación de la IA. Por ejemplo, como experimento, los investigadores utilizaron un modelo de modelo de lenguaje grande simple para detectar y explicar una recreación de un ataque de phishing de lanza conocido y conocido . Las variaciones en este enfoque pueden funcionar en las publicaciones en las redes sociales para detectar contenido manipulador.
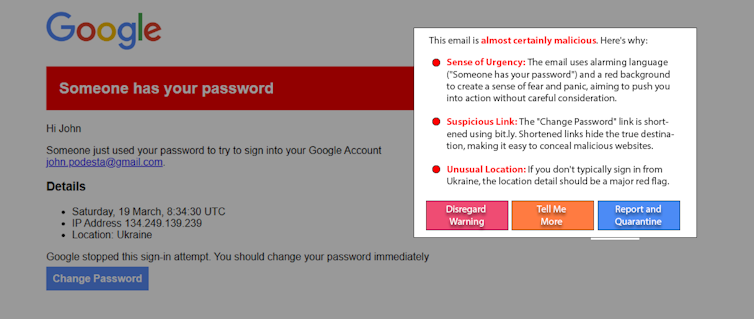
La adopción generalizada de IA generativa otorga a sus fabricantes poder e influencia extraordinarias. La alineación de la IA es crucial para garantizar que estos sistemas sigan siendo seguros y beneficiosos, pero también puede ser mal utilizado. La IA generativa armada podría ser contrarrestada por una mayor transparencia y responsabilidad de las compañías de IA, la vigilancia de los consumidores y la introducción de regulaciones apropiadas.
James Foulds , Profesor Asociado de Sistemas de Información, Universidad de Maryland, Condado de Baltimore
Pheldman , Profesor Asistente de Investigación Adjunto de Sistemas de Información, Universidad de Maryland, Baltimore County
Shimei Pan , Profesor Asociado de Sistemas de Información, Universidad de Maryland, Condado de Baltimore,
este artículo se republicó a partir de la conversación bajo una licencia creativa Commons. Lea el artículo original .






