Tattiche di crescita degli editori per la stagione elettorale | WEBINAR


2.6.1 Che cos'è un crawl budget?
Il budget di scansione è il numero di pagine del tuo sito web che un crawler web analizzerà in un dato intervallo di tempo.
Ogni volta che si preme il pulsante "Pubblica", Google deve scansionare e indicizzare il contenuto affinché inizi a comparire nei risultati di ricerca. Data la portata e il volume dei contenuti su Internet, la scansione diventa una risorsa preziosa che deve essere preventivata e gestita in modo razionale per un utilizzo ottimale.
In parole povere, per Google è difficile scansionare e indicizzare ogni singola pagina web ogni giorno. Per questo motivo, Google scansiona ogni sito web in base al budget assegnato.
Il budget di scansione viene assegnato ai siti web in base a due fattori: limite di scansione e domanda di scansione.
Si tratta della capacità e/o della volontà di un sito web di essere scansionato.
Non tutti i siti web sono progettati per essere scansionati quotidianamente. La scansione comporta l'invio da parte di Googlebot di richieste al server del tuo sito web che, se eseguite troppo frequentemente, potrebbero mettere a dura prova la capacità del server.
Inoltre, non tutti gli editori desiderano che il loro sito venga scansionato continuamente.
La richiesta di scansione è una misura della frequenza con cui una determinata pagina deve essere (nuovamente) scansionata. Le pagine più popolari o quelle che vengono aggiornate frequentemente devono essere scansionate e ripetute più frequentemente.
Se Google non riesce a scansionare e indicizzare i tuoi contenuti, questi semplicemente non verranno visualizzati nei risultati di ricerca.
Detto questo, i crawl budget sono generalmente un problema solo per gli editori di medie e grandi dimensioni con più di 10.000 pagine sul loro sito web. Gli editori più piccoli non dovrebbero preoccuparsene eccessivamente.
Tuttavia, gli editori con 10.000 o più pagine sul loro sito web vorranno evitare che Googlebot esegua la scansione di pagine non importanti. Esaurire il budget di scansione su contenuti irrilevanti o meno importanti significa che le pagine di maggior valore potrebbero non essere sottoposte a scansione.
Inoltre, gli editori di notizie dovranno fare attenzione a non sprecare budget di scansione, dato che la scansione è uno dei tre modi in cui Google News scopre nuovi contenuti in modo tempestivo. Gli altri due sono l'utilizzo delle Sitemap e del Google Publisher Center, che abbiamo approfondito nei nostri moduli Sitemap di Google News e Google Publisher Center.
Ottimizzare la frequenza e la velocità con cui Googlebot esegue la scansione del tuo sito web implica il monitoraggio di una serie di variabili. Iniziamo elencando i fattori più importanti che contribuiscono all'ottimizzazione del budget e della frequenza di scansione.
Le due tattiche più utili per monitorare il modo in cui i tuoi contenuti vengono scansionati sono l'analisi dei file di registro e il report sulle statistiche di scansione di Google Search Console (GSC).
Un file di registro è un documento di testo che registra ogni attività sul server del tuo sito web. Include tutti i dati relativi a richieste di scansione, richieste di pagine, richieste di immagini, richieste di file JavaScript e qualsiasi altra risorsa necessaria per il funzionamento del tuo sito web.
Ai fini della SEO tecnica, l'analisi dei file di registro aiuta a determinare molte informazioni utili sulla scansione degli URL, tra cui, a titolo esemplificativo ma non esaustivo:
Come fare questo
L'analisi dei file di log è un'attività che richiede una certa familiarità tecnica con il backend di un sito web. Per questo motivo, consigliamo di utilizzare un software di analisi dei file di log. Sono disponibili diversi strumenti di analisi dei log gratuiti e a pagamento, come Graylog , Loggly , Elastic Stack , Screaming Frog Log Analyzer e Nagios, solo per citarne alcuni.
Se sei uno sviluppatore esperto o un amministratore di sistema, puoi anche eseguire manualmente un'analisi del file di registro.
Per fare ciò, segui questi passaggi:
Una volta scaricato il file di registro, è possibile modificarne l'estensione in .csv e aprirlo con Microsoft Excel o Google Sheets. Come abbiamo detto, tuttavia, questo approccio richiede un certo livello di competenza per interpretare il file di registro.
È anche possibile accedere al file di registro tramite un client FTP inserendo il percorso del file di registro. Un tipico percorso di un file di registro è simile al seguente:
Nome del server (ad esempio, Apache) /var/log/access.log
Tuttavia, è molto più comodo utilizzare uno strumento di analisi dei log. Una volta caricato il file di log nello strumento, è possibile ordinare i dati utilizzando diversi filtri. Ad esempio, sarà possibile vedere quali URL sono stati consultati più frequentemente da Googlebot.
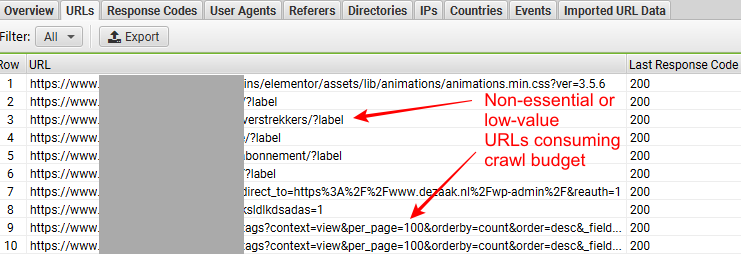
Potrai anche vedere se Googlebot ha avuto accesso a URL non essenziali o di scarso valore, come URL di navigazione a faccette, URL duplicati, ecc. Identificarli è importante perché stanno sprecando il tuo budget di scansione.
Per capire cosa intendiamo, guarda lo screenshot qui sotto, tratto da SEO Log File Analyser di Screaming Frog.
GSC fornisce ai proprietari di siti web dati e approfondimenti completi su come Google analizza i loro contenuti. Tra questi, report dettagliati su:
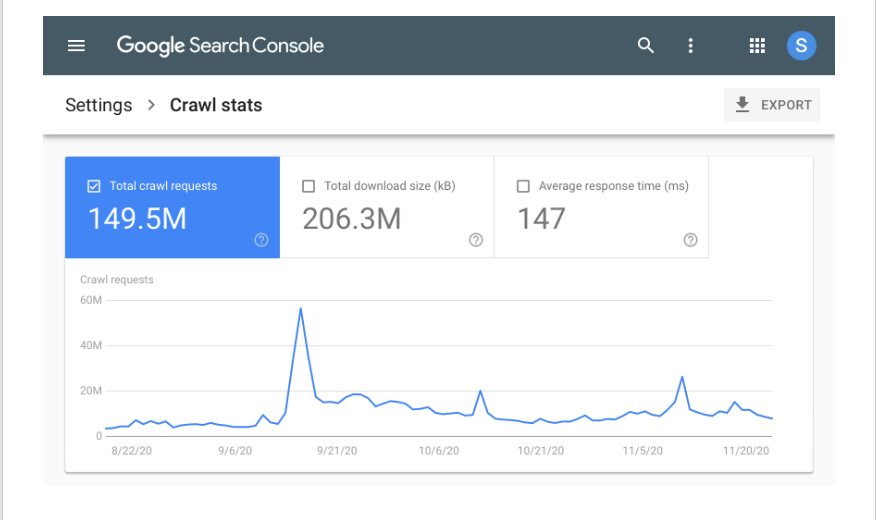
GSC mette inoltre a disposizione grafici e diagrammi di facile comprensione per fornire ai proprietari di siti web ancora più informazioni. Lo screenshot qui sotto mostra l'aspetto di un tipico report sulle statistiche di scansione su GSC.
Il GSC ti informa anche se ci sono problemi con la scansione. Verifica diversi errori e assegna a ciascuno un codice. Gli errori più comuni che il GSC verifica includono:
Il report GSC mostra anche quante pagine sono state interessate da ciascun errore, insieme allo stato di convalida.
Come fare questo
Ecco come puoi accedere al report delle statistiche di scansione GSC per il tuo sito web o la tua pagina web:
Tra questi:
Ora sappiamo che il crawl budget è una risorsa preziosa il cui utilizzo deve essere ottimizzato per ottenere i migliori risultati. Ecco alcune tecniche per farlo:
I contenuti duplicati potrebbero finire per essere scansionati separatamente, con conseguente spreco di budget di scansione. Per evitare che ciò accada, puoi consolidare le pagine duplicate del tuo sito web in una sola, oppure eliminarle.
Robots.txt è un file che ha diverse funzioni, una delle quali è quella di indicare a Googlebot di non eseguire la scansione di determinate pagine o sezioni di pagine. Questa è una strategia importante che può essere utilizzata per impedire a Googlebot di eseguire la scansione di contenuti di scarso valore o di contenuti che non necessitano di scansione.
Ecco alcune best practice da seguire quando si utilizza robots.txt per ottimizzare il budget di scansione:
Come fare questo
Creare ed eseguire un file robots.txt per limitare l'accesso a Googlebot richiede una certa conoscenza di programmazione. Ecco i passaggi necessari:
Un tipico file robots.txt conterrà i seguenti elementi:
Di seguito è riportato l'aspetto di un semplice file robots.txt.
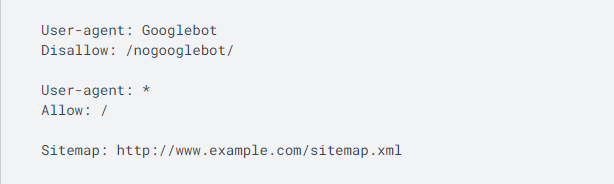
Questo codice significa che a un agente utente, in questo caso Googlebot, non è consentito eseguire la scansione di alcun URL che inizia con " http://www.example.com/nogooglebot/ ".
Se non ti senti a tuo agio nel creare e caricare autonomamente i file robots.txt, ti consigliamo di rivolgerti a un esperto.
Un crawler bot arriva su un sito con un'assegnazione generica del numero di pagine da analizzare. La mappa del sito XML indirizza efficacemente il crawler a leggere gli URL selezionati, garantendo l'utilizzo efficace di tale budget.
Tieni presente che le prestazioni di posizionamento di una pagina dipendono da diversi fattori, tra cui la qualità dei contenuti e i link interni/esterni. Valuta di includere solo le pagine di livello superiore nella mappa. Alle immagini può essere assegnata una propria sitemap XML.
Per garantire un'implementazione ottimale della mappa del sito XML, segui questi consigli:
Per un'analisi più dettagliata delle mappe dei siti, consulta il nostro modulo dedicato a questo argomento .
I link interni svolgono tre funzioni importanti:
Pertanto, per un crawling efficiente, è importante implementare un'efficace strategia di linking interno. Per maggiori informazioni sui linking interni, consulta il nostro modulo didattico dettagliato qui.
Se un sito web utilizza una piattaforma di hosting condivisa, il crawl budget sarà condiviso con altri siti web che utilizzano la stessa piattaforma. Un grande editore potrebbe trovare nell'hosting indipendente una valida alternativa.
Prima di aggiornare il tuo hosting per risolvere il sovraccarico del traffico dei bot, ci sono alcuni fattori che vale la pena considerare che potrebbero altrimenti influire sul carico del server.
Per maggiori informazioni sui vantaggi dei CDN, consulta la nostra pagina dedicata al modulo esperienza .
Quando Googlebot atterra su una pagina web, ne visualizza tutte le risorse, incluso Javascript. Sebbene la scansione dell'HTML sia piuttosto semplice, Googlebot deve elaborare Javascript più volte per poterlo visualizzare e comprenderne il contenuto.
Questo può rapidamente prosciugare il budget di scansione di Google per un sito web. La soluzione è implementare il rendering Javascript lato server.
Come fare questo
Integrare Javascript nel codice sorgente del tuo sito web richiede competenze di programmazione e ti consigliamo di consultare uno sviluppatore web se prevedi di apportare tali modifiche. Detto questo, ecco alcune linee guida su cosa cercare quando si cerca di ottimizzare l'uso di Javascript.
I CWV sono una misura delle prestazioni della pagina che influiscono direttamente sul suo rendimento nei posizionamenti nei risultati di ricerca.
Il rapporto CWV del GSC raggruppa le prestazioni degli URL in tre categorie:
I CWV possono anche influire sul budget di scansione. Ad esempio, le pagine che si caricano lentamente possono incidere negativamente sul budget di scansione, poiché Google ha un tempo limitato per le attività di scansione. Se le pagine si caricano velocemente, Google può scansionarne un numero maggiore entro il tempo limitato a sua disposizione. Allo stesso modo, troppi report sullo stato di errore possono rallentare la scansione e sprecare il budget di scansione.
Per un esame più approfondito dei CWV, consultare il nostro modulo sulla pagina esperienza .
Un crawler di terze parti come Semrush , Sitechecker.pro o Screaming Frog consente agli sviluppatori web di controllare tutti gli URL di un sito e di identificare potenziali problemi.
I crawler di terze parti possono essere utilizzati per identificare:
Questi programmi offrono un report sulle statistiche di scansione per aiutare a evidenziare problemi che gli strumenti di Google potrebbero non rilevare.
Migliorando i dati strutturati e riducendo i problemi di igiene, si semplificherà il lavoro di scansione e indicizzazione di un sito da parte di Googlebot.
Quando si utilizzano crawler di terze parti, consigliamo di seguire le seguenti best practice:
I parametri URL, ovvero la sezione dell'indirizzo web che segue il punto esclamativo, vengono utilizzati in una pagina per vari motivi, tra cui il filtraggio, la paginazione e la ricerca.
Sebbene questo possa migliorare l'esperienza utente, può anche causare problemi di scansione quando sia l'URL di base che quello con parametri restituiscono lo stesso contenuto. Un esempio di questo potrebbe essere "http://mysite.com" e "http://mysite.com?id=3" che restituiscono esattamente la stessa pagina.
I parametri consentono a un sito di avere un numero pressoché illimitato di link, ad esempio quando un utente può selezionare giorni, mesi e anni su un calendario. Se al bot viene consentito di scansionare queste pagine, il budget di scansione verrà utilizzato inutilmente.
Ciò può rappresentare un problema particolarmente preoccupante se il tuo sito web utilizza la navigazione sfaccettata o identificatori di sessione che possono generare più pagine duplicate che, se scansionate, potrebbero comportare uno spreco di budget di scansione.
Gli URL duplicati possono verificarsi anche se hai versioni localizzate della tua pagina web in lingue diverse e il contenuto di queste pagine non è stato tradotto.
Per risolvere questo problema, consigliamo quanto segue:
Ecco come un semplice<hreflang> sembra come nel tuo codice sorgente:
https://examplesite.com/news/hreflang-tags” />
Ciò indica al crawler che l'URL specificato è una variante spagnola (messicana) dell'URL principale e non deve essere trattato come duplicato.
Abbiamo discusso gli elementi essenziali della gestione del crawl budget. I suggerimenti elencati in questa sezione, sebbene non siano essenziali per una sana gestione del crawl budget, integrano ampiamente le tecniche discusse in precedenza.
Un'emergenza di scansione si verifica quando Googlebot sovraccarica il tuo sito web con più richieste di scansione di quante ne possa gestire. È importante identificare il problema il più rapidamente possibile, monitorando attentamente i log del server e le statistiche di scansione in Google Search Console.
Se un improvviso aumento delle scansioni non viene gestito in tempo, potrebbe causare un rallentamento del server. Il rallentamento del server aumenterebbe il tempo medio di risposta dei crawler e, di conseguenza, i motori di ricerca ridurrebbero automaticamente la loro velocità di scansione. Questo è problematico perché una velocità di scansione ridotta porterebbe a una perdita di visibilità, con i nuovi articoli che non verrebbero scansionati immediatamente.
Se noti che l'over crawling sta mettendo a dura prova i tuoi server, ecco alcune cose che puoi fare:
Google utilizza algoritmi sofisticati che controllano la velocità di scansione. Pertanto, idealmente, non si dovrebbe manomettere la velocità di scansione. Tuttavia, in caso di emergenza, è possibile accedere al proprio account GSC e accedere alle Impostazioni della velocità di scansione per la propria proprietà.
Se vedi la velocità di scansione come Calcolata come Ottimale, non potrai modificarla manualmente. Per modificare la velocità di scansione, è necessario inviare una richiesta specifica a Google.
In caso contrario, puoi semplicemente modificare la velocità di scansione impostandola sul valore desiderato. Questo valore rimarrà valido per 90 giorni.
Se non si desidera alterare la velocità di scansione in GSC, è anche possibile bloccare l'accesso alla pagina da parte di Googlebot utilizzando robots.txt. La procedura per farlo è stata spiegata in precedenza.
Google può impiegare fino a tre giorni per analizzare la maggior parte dei siti. Le uniche eccezioni sono i siti di notizie o altri siti che pubblicano contenuti sensibili al fattore tempo, che potrebbero essere analizzati quotidianamente.
Per verificare la frequenza con cui le tue pagine vengono scansionate, monitora il log del tuo sito. Se ritieni che i tuoi contenuti non vengano scansionati con la frequenza necessaria, segui questi passaggi:
https://www.google.com/ping?sitemap=URL_COMPLETO_DELLA_MAPPA_DEL_SITO
Nota: questo passaggio dovrebbe essere considerato l'ultima azione da intraprendere, poiché comporta un certo grado di rischio. Se Googlebot rileva errori 503 e 429, inizierà a scansionare più lentamente e potrebbe interromperla, causando un calo temporaneo del numero di pagine indicizzate.
Un codice di errore 503 indica che il server è temporaneamente inattivo, mentre 429 indica che un utente ha inviato troppe richieste in un determinato lasso di tempo. Questi codici comunicano a Googlebot che il problema è temporaneo e che dovrebbe tornare a scansionare la pagina in un secondo momento.
Sebbene possa sembrare un passaggio di poco conto, è importante perché se Googlebot non conosce la natura del problema riscontrato da una pagina web, presume che il problema sia di natura a lungo termine e potrebbe contrassegnare la pagina come non reattiva, il che può influire sulla SEO.
La creazione di codici di errore 503 avviene tramite un file PHP, che viene inserito nel codice sorgente HTML esistente della pagina insieme a un messaggio di errore. Dovrai anche scrivere alcune righe di codice HTML aggiuntive che specifichino quando è previsto il ritorno del sito.
Ecco come appare il codice per un reindirizzamento 503:
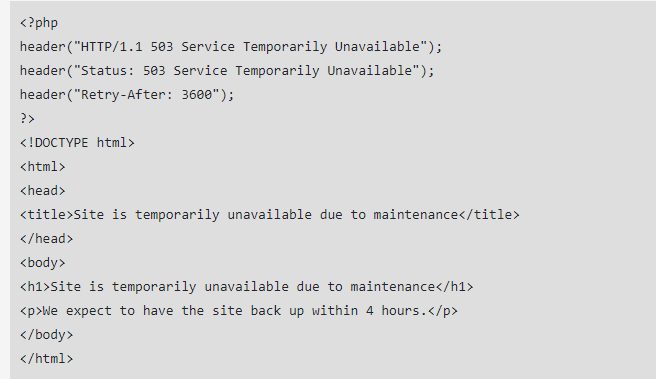
Per eseguire reindirizzamenti 503 o 429 sono necessarie competenze avanzate di programmazione HTML. Ti consigliamo di consultare il tuo sviluppatore web prima di tentare questa operazione.
Ora abbiamo una buona comprensione di cosa sia un crawl budget e come ottimizzarlo. Tuttavia, è altrettanto importante sapere cosa non fare quando si tratta di crawl budget.
Ecco alcuni errori comuni da evitare per assicurarti di sfruttare al meglio il budget di scansione del tuo sito web:
La frequenza con cui Google esegue la scansione del tuo sito web è determinata dai suoi algoritmi, che prendono in considerazione diversi segnali per arrivare a una frequenza di scansione ottimale.
Aumentare la frequenza di scansione non porta necessariamente a un posizionamento migliore nei risultati di ricerca. La frequenza di scansione, o la scansione stessa, non è di per sé un fattore di ranking.
Google non preferisce necessariamente i contenuti più recenti rispetto a quelli più vecchi. Google classifica le pagine in base alla pertinenza e alla qualità dei contenuti, indipendentemente dal fatto che siano vecchi o nuovi. Quindi, non è necessario sottoporli a scansione continua.
La direttiva crawl-delay non aiuta a controllare Googlebot. Se desideri rallentare la frequenza di scansione in risposta a un'eccessiva scansione che sta sovraccaricando il tuo sito web, consulta le istruzioni fornite nella sezione precedente.
La velocità di caricamento del tuo sito web può influire sul tuo crawl budget. Una pagina che si carica velocemente significa che Google può accedere a più informazioni con lo stesso numero di connessioni.
Per suggerimenti sull'ottimizzazione della velocità di caricamento, consulta il nostro modulo sull'esperienza della pagina .
I link nofollow potrebbero comunque influire sul crawl budget, in quanto potrebbero comunque essere scansionati. D'altra parte, i link che robots.txt ha disabilitato non hanno alcun effetto sul crawl budget.
Inoltre, URL alternativi e contenuti Javascript potrebbero finire per essere scansionati, consumando il budget di scansione, quindi è importante limitarne l'accesso rimuovendoli o utilizzando robots.txt.
Il crawl budget è una risorsa preziosa ed è fondamentale ottimizzarlo. Problemi di crawling e indicizzazione possono influire sulle prestazioni dei tuoi contenuti, soprattutto se il tuo sito web ha un numero elevato di pagine.
Le due operazioni più fondamentali per ottimizzare il budget di scansione sono mantenere aggiornata la mappa del sito e monitorare regolarmente i problemi di indicizzazione tramite il report delle statistiche di scansione e i file di registro di GSC.
È importante imparare ad applicare le migliori pratiche di gestione della scansione sia durante il lancio di nuove funzionalità del sito web sia quando si verificano errori isolati.