Tácticas de crecimiento de editores para la temporada electoral | SEMINARIO WEB


2.6.1 ¿Qué es un presupuesto de rastreo?
El presupuesto de rastreo es la cantidad de páginas de su sitio web que rastreará un rastreador web en un período de tiempo determinado.
Cada vez que presionas el botón de publicar, Google necesita rastrear e indexar el contenido para que comience a aparecer en los resultados de búsqueda. Dada la escala y el volumen del contenido en Internet, el rastreo se convierte en un recurso valioso que debe presupuestarse y racionarse para un uso más eficiente.
En pocas palabras, es difícil para Google rastrear e indexar cada página en Internet todos los días. Entonces, Google rastrea cada sitio web de acuerdo con su presupuesto asignado.
El presupuesto de rastreo se asigna a los sitios web en función de dos factores: el límite de rastreo y la demanda de rastreo.
Esta es la capacidad y/o disposición de un sitio web para ser rastreado.
No todos los sitios web están diseñados para ser rastreados todos los días. El rastreo implica que Googlebot envíe solicitudes al servidor de su sitio web que, si se realizan con demasiada frecuencia, pueden sobrecargar la capacidad del servidor.
Además, no todos los editores quieren que su sitio sea rastreado continuamente.
La demanda de rastreo es una medida de la frecuencia con la que se desea (re)rastrear una página en particular. Las páginas populares o las que se actualizan con frecuencia deben rastrearse y volverse a rastrear con mayor frecuencia.
Si Google no puede rastrear e indexar su contenido, ese contenido simplemente no aparecerá en los resultados de búsqueda.
Dicho esto, los presupuestos de rastreo generalmente son sólo una preocupación para los editores medianos y grandes que tienen más de 10.000 páginas en su sitio web. Los editores más pequeños no deberían preocuparse demasiado por los presupuestos de rastreo.
Sin embargo, los editores con 10,000 o más páginas en su sitio web querrán evitar las páginas de rastreo de Googlebot que no eran importantes. Atruscar su presupuesto de rastreo en contenido irrelevante o menos importante significa que las páginas de mayor valor pueden no estar rastreadas.
Además, los editores de noticias querrán tener cuidado con los presupuestos de rastreo desperdiciados dado que el rastreo es una de las tres formas en que Google News descubre contenido fresco de manera oportuna. Los otros dos son mediante el uso de Sitemaps y Google Publisher Center, que hemos explorado más a fondo en nuestro mapa del sitio de Google News y Google Publisher Center
Optimizar la frecuencia y la velocidad con la que GoogleBot rastrea su sitio web implica monitorear una gama de variables. Comenzamos enumerando los factores más importantes involucrados en la optimización del presupuesto y frecuencia de rastreo.
Las dos tácticas más útiles para monitorear cómo se está rastreando su contenido están analizando los archivos de registro y el informe de estadísticas de rastreo de Google Search Console (GSC).
Un archivo de registro es un documento de texto que registra cada actividad en el servidor de su sitio web. Esto incluye todos los datos sobre solicitudes de rastreo, solicitudes de página, solicitudes de imágenes, solicitudes de archivos JavaScript y cualquier otro recurso necesario para ejecutar su sitio web.
A los fines del SEO técnico, el análisis de archivos de registro ayuda a determinar una gran cantidad de información útil sobre el rastreo de URL, incluidos, entre otros::
Cómo hacer esto
El análisis de archivos de registro es una tarea que requiere cierto grado de familiaridad técnica con el backend de un sitio web. Por esta razón, recomendamos usar el software de analizador de archivos de registro. Hay varias herramientas de análisis de registro gratuitas y pagas disponibles como GrayLog , Loggly , Elastic Stack , Screaming Frog Log Analyzer y Nagios , por nombrar algunos.
Si es un desarrollador o administrador de sistemas experimentado, también puede realizar manualmente un análisis de archivos de registro.
Para hacer esto, siga estos pasos:
Una vez que haya descargado el archivo de registro, puede cambiar la extensión a .csv y abrirlo con Microsoft Excel o Google Sheets. Sin embargo, como dijimos, este enfoque requiere un cierto nivel de experiencia para dar sentido al archivo de registro.
También puede acceder al archivo de registro utilizando un cliente FTP ingresando la ruta del archivo de registro. Una ruta de archivo de registro típica se parece a esto:
Nombre del servidor (por ejemplo, apache) /var/log/access.log
Sin embargo, es mucho más conveniente usar una herramienta de análisis de registro. Una vez que haya cargado el archivo de registro en la herramienta, puede ordenar los datos utilizando varios filtros. Por ejemplo, podrá ver a qué URL ha sido accedido con mayor frecuencia por GoogleBot.
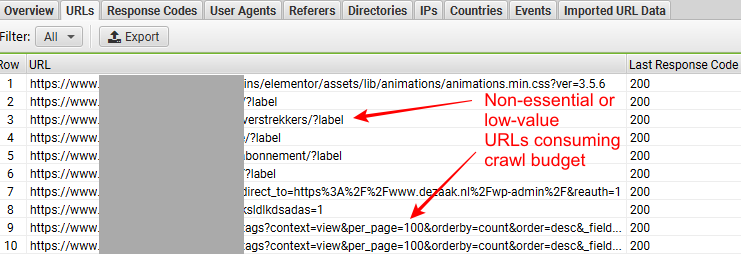
También podrá ver si GoogleBot ha estado accediendo a URL no esenciales o de bajo valor, como URL de navegación facetada, URL duplicadas, etc. Identificar esto es importante ya que están desperdiciando su presupuesto de rastreo.
Mire la siguiente captura de pantalla, tomada del analizador de archivos de registro SEO de Screaming Frog, para ver a qué nos referimos.
GSC proporciona a los propietarios de sitios web datos e ideas integrales sobre cómo Google rastrea su contenido. Esto incluye informes detallados sobre:
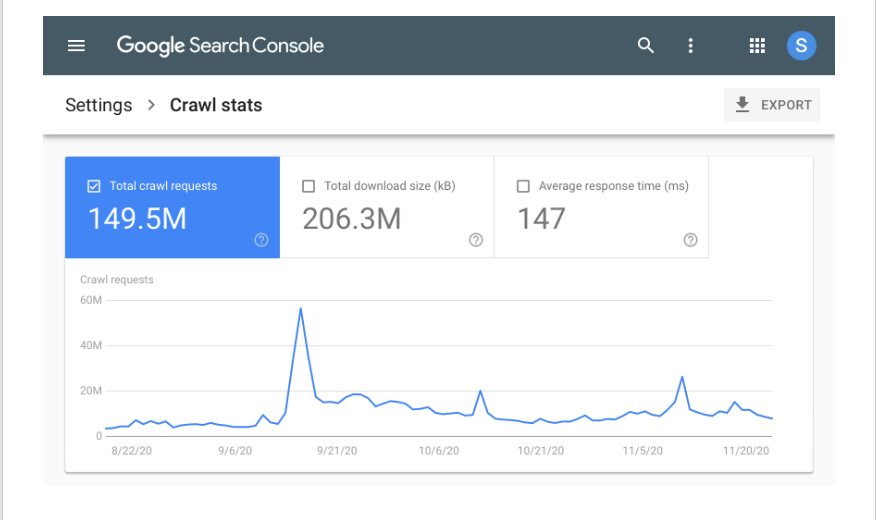
GSC también pone a disposición de los gráficos y gráficos fáciles de entender para proporcionar a los propietarios de sitios web aún más información. La captura de pantalla a continuación es cómo se ve un informe típico de estadísticas de rastreo en GSC.
El GSC también le informa si hay algún problema con el rastreo. Verifica varios errores y asigna a cada uno un código. Los errores más comunes que las verificaciones de GSC incluyen:
El informe GSC también muestra cuántas páginas han sido afectadas por cada error junto con el estado de validación.
Cómo hacer esto
Así es como puede acceder al informe de estadísticas de rastreo GSC para su sitio web o página web:
Éstas incluyen:
Ahora sabemos que el presupuesto de Crawl es un recurso valioso cuyo uso debe optimizarse para los mejores resultados. Aquí hay algunas técnicas para hacer esto:
El contenido duplicado puede terminar siendo rastreado por separado, lo que lleva a un desperdicio de presupuesto de rastreo. Para evitar que esto suceda, consolide las páginas duplicadas en su sitio web en una o elimine las páginas duplicadas.
Robots.txt es un archivo que sirve a varios propósitos, uno de los cuales es decirle a GoogleBot que no rastree ciertas páginas o secciones de páginas. Esta es una estrategia importante que se puede utilizar para evitar que Googlebot se rastree el contenido o el contenido de bajo valor que no necesita rastrear.
Aquí hay algunas mejores prácticas al usar robots.txt para optimizar el presupuesto de rastreo:
Cómo hacer esto
Creación y ejecución de un archivo robots.txt para restringir el acceso de GoogleBot requiere algún conocimiento de codificación. Aquí están los pasos involucrados:
Un archivo típico de robots.txt tendrá los siguientes elementos:
A continuación se muestra un archivo simple de robots.txt.
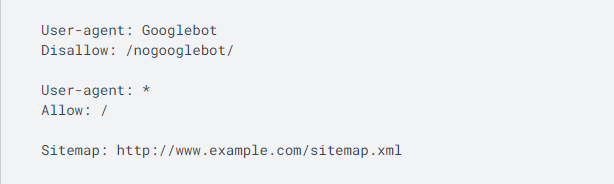
Este código significa que un agente de usuarios, Googlebot en este caso, no puede rastrear ninguna URL que comience con " http://www.example.com/nogooglebot/ ".
Sugerimos buscar ayuda de expertos si no se siente cómodo creando y cargando robots.txt archivos usted mismo.
Un robot de rastreo llega a un sitio con una asignación general de cuántas páginas rastreará. El mapa del sitio XML dirige eficazmente al bot para que lea las URL seleccionadas, lo que garantiza el uso eficaz de ese presupuesto.
Tenga en cuenta que el rendimiento de clasificación de una página depende de varios factores, incluida la calidad del contenido y los enlaces internos/externos. Considere incluir solo páginas de primer nivel en el mapa. A las imágenes se les puede asignar su propio mapa del sitio XML.
Siga estas recomendaciones para garantizar la implementación óptima del mapa del sitio XML:
Para ver los Sitemaps más detallados, consulte nuestro módulo dedicado sobre este tema .
Los enlaces internos realizan tres funciones importantes:
Por lo tanto, para el rastreo eficiente, es importante implementar una estrategia de vinculación interna eficiente. Para obtener más información sobre el enlace interno, consulte nuestro módulo de curso detallado aquí.
Si un sitio web se ejecuta en una plataforma de alojamiento compartido, el presupuesto de Crawl se compartirá con otros sitios web que se ejecutan en dicha plataforma. Un gran editor puede encontrar que el alojamiento independiente es una alternativa valiosa.
Antes de actualizar su alojamiento para resolver la sobrecarga de tráfico BOT, hay algunos factores que vale la pena considerar que de otra manera afectan las cargas del servidor.
Para obtener más información sobre las ventajas de los CDN, consulte nuestro módulo de experiencia de página .
Cuando Googlebot llega a una página web, muestra todos los recursos de dicha página, incluido Javascript. Si bien rastrear HTML es bastante sencillo, el robot de Google debe procesar Javascript varias veces para poder representarlo y comprender su contenido.
Esto puede agotar rápidamente el presupuesto de rastreo de Google para un sitio web. La solución es implementar la representación de Javascript en el lado del servidor.
Cómo hacer esto
Abordar JavaScript en el código fuente de su sitio web requiere experiencia en codificación y recomendamos consultar a un desarrollador web si planea realizar dichos cambios. Dicho esto, aquí hay algunas pautas sobre qué buscar al tratar de optimizar el uso de JavaScript.
Los CWV son una medida del rendimiento de la página que afecta directamente cómo funciona su página en las clasificaciones de búsqueda.
El informe de CWV del GSC agrupa el rendimiento de la URL en tres categorías:
Los CWV también pueden afectar su presupuesto de rastreo. Por ejemplo, las páginas de carga lenta pueden comer en su presupuesto de rastreo, ya que Google tiene una cantidad limitada de tiempo para rastrear tareas. Si sus páginas se cargan rápidamente, Google puede gatear más de ellas en el tiempo limitado que tiene. Del mismo modo, demasiados informes de estado de error pueden ralentizar y desperdiciar su presupuesto de rastreo.
Para un examen más exhaustivo de CWVS, consulte nuestro módulo en la experiencia de la página .
Un rastreador de terceros como Semrush , Sitechecker.pro o gritos de rana permite a los desarrolladores web auditar todas las URL de un sitio e identificar posibles problemas.
Los rastreadores de terceros se pueden usar para identificar:
Estos programas ofrecen un informe de estadísticas de rastreo para ayudar a resaltar problemas que las propias herramientas de Google pueden no detectar.
Mejorar los datos estructurados y reducir los problemas de higiene agilizará el trabajo del robot de Google de rastrear e indexar un sitio.
Recomendamos las siguientes mejores prácticas al usar rastreadores de terceros:
Parámetros de URL: la sección de la dirección web que sigue al "?" — se utilizan en una página por diversos motivos, incluidos el filtrado, la paginación y la búsqueda.
Si bien esto puede mejorar la experiencia del usuario, también puede causar problemas de rastreo cuando tanto la URL base como la que tiene parámetros devuelven el mismo contenido. Un ejemplo de esto sería "http://mysite.com" y "http://mysite.com?id=3" que devuelven exactamente la misma página.
Los parámetros permiten que un sitio tenga una cantidad casi ilimitada de enlaces, como cuando un usuario puede seleccionar días, meses y años en un calendario. Si al robot se le permite rastrear estas páginas, el presupuesto de rastreo se consumirá innecesariamente.
Esto puede ser especialmente un problema para preocuparse si su sitio web utiliza identificadores de navegación o sesión facetados que pueden generar múltiples páginas duplicadas que, si se arrastran, podrían conducir a un desperdicio de presupuesto de rastreo.
Las URL duplicadas también pueden dar lugar si tiene versiones localizadas de su página web en diferentes idiomas, y el contenido en estas páginas no se ha traducido.
Recomendamos lo siguiente para abordar esto:
Así es como un simple<hreflang> Parece en su código fuente:
https://examplesite.com/news/hreflang-tags "/>
Esto le dice al rastreador que la URL especificada es una variante española (mexicana) de la URL principal, y no debe tratarse como un duplicado.
Hemos discutido los elementos esenciales de la gestión del presupuesto de rastreo. Los punteros enumerados en esta sección, aunque no son críticos para una gestión de presupuesto de rastreo saludable, contribuyen en gran medida a complementar las técnicas discutidas anteriormente.
Se produce una emergencia de rastreo cuando Googlebot abruma su sitio web con más solicitudes de rastreo de las que puede manejar. Es importante identificar el problema lo más rápido posible, lo que se puede hacer monitoreando de cerca los registros del servidor y las estadísticas de rastreo en la consola de búsqueda de Google.
Si no se gestiona un aumento repentino en el rastreo a tiempo, podría hacer que el servidor disminuya la velocidad. La desaceleración del servidor aumentaría el tiempo de respuesta promedio para los rastreadores y, como resultado de este alto tiempo de respuesta, los motores de búsqueda reducirán automáticamente su tasa de rastreo. Esto es problemático porque las tasas de rastreo reducidas conducirán a una pérdida de visibilidad, con nuevos artículos que no se arrastran de inmediato.
Si nota que sobre el rastreo está gravando a sus servidores, aquí puede hacer algunas cosas:
Google tiene algoritmos sofisticados que controlan la tasa de rastreo. Idealmente, uno no debe manipular la tasa de rastreo. Sin embargo, en una situación de emergencia, puede iniciar sesión en su cuenta de GSC y navegar hasta la configuración de la tasa de rastreo para su propiedad.
Si ve la tasa de rastreo allí tan calculada como óptima, no podrá cambiarla manualmente. Se debe presentar una solicitud especial a Google para cambiar la tasa de rastreo.
Si este no es el caso, simplemente puede cambiar la velocidad de rastreo a su valor deseado. Este valor permanecerá válido por 90 días.
Si no desea manipular las tasas de rastreo en el GSC, también puede bloquear el acceso a la página por GoogleBot usando robots.txt. El procedimiento para hacer esto se ha explicado anteriormente.
Puede llevar a Google hasta tres días a rastrear la mayoría de los sitios. Las únicas excepciones son sitios de noticias u otros sitios que publican contenido sensible al tiempo que puede arrastrarse diariamente.
Para verificar con qué frecuencia se están rastreando sus páginas, monitoree el registro de su sitio. Si aún siente que su contenido no se está arrastrando con tanta frecuencia como debería ser, siga estos pasos:
https://www.google.com/ping?sitemap=full_url_of_sitemap
Tenga en cuenta: este paso debe verse como la última acción que cualquiera debe tomar, ya que tiene un cierto grado de riesgo. Si Googlebot ve errores 503 y 429, comenzará a gatear más lentamente y puede detener el rastreo, lo que lleva a una caída temporal en el número de páginas indexadas.
Un código de error 503 significa que el servidor está temporalmente inactivo, mientras que 429 significa que un usuario ha enviado demasiadas solicitudes en un período de tiempo específico. Estos códigos le permiten saber a Googlebot que el problema es temporal, y debería volver a rastrear la página en un momento posterior.
Aunque es un paso aparentemente menor, esto es importante porque si Googlebot no conoce la naturaleza del problema que está experimentando una página web, supone que el problema es de naturaleza a largo plazo y puede marcar la página como no responder, lo que puede afectar el SEO.
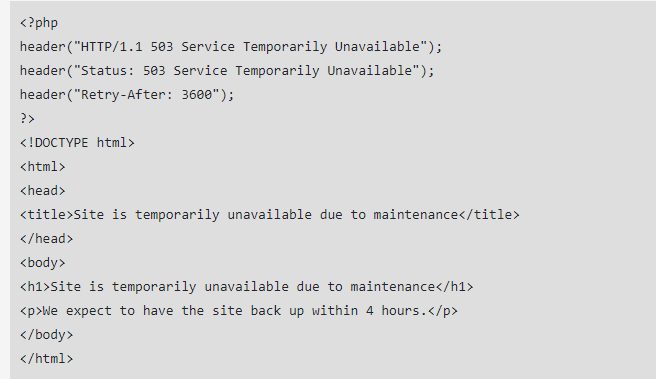
La creación de códigos de error 503 se realiza a través de un archivo PHP, que se inserta dentro del código fuente HTML existente de su página junto con un mensaje de error. También deberá escribir algunas líneas adicionales de código HTML que mencionan cuándo se espera que el sitio regrese.
Así es como se ve el código para una redirección 503:
Hacer redirecciones 503 o 429 requiere habilidades de codificación HTML avanzadas y sugerimos consultar con su desarrollador web antes de intentarlo.
Ahora tenemos una buena comprensión de lo que es un presupuesto de rastreo y cómo optimizarlo. Sin embargo, saber qué no hacer cuando se trata de presupuestos de rastreo es igualmente importante.
Aquí hay algunas trampas comunes para evitar para asegurarse de aprovechar al máximo el presupuesto de rastreo de su sitio web:
La frecuencia con la que Google rastrea su sitio web está determinada por sus algoritmos, que tienen en cuenta varias señales para llegar a una frecuencia de rastreo óptima.
El aumento de la tasa de rastreo no necesariamente conduce a mejores posiciones en los resultados de búsqueda. La frecuencia de rastreo o incluso el rastreo de sí mismo no es un factor de clasificación en sí mismo.
Google no necesariamente prefiere contenido más fresco sobre contenido anterior. Google clasifica las páginas en función de la relevancia y la calidad del contenido, independientemente de si es antigua o nueva. Por lo tanto, no es necesario seguir arrastrados.
La directiva Crawl-Delay no ayuda a controlar GoogleBot. Si desea reducir la velocidad de la frecuencia de rastreo en respuesta al rastreo excesivo que está abrumando su sitio web, consulte las instrucciones proporcionadas en la sección anterior.
La velocidad de carga de su sitio web puede afectar su presupuesto de rastreo. Una página de carga rápida significa que Google puede acceder a más información sobre el mismo número de conexiones.
Para obtener consejos sobre la optimización de la velocidad de carga, consulte nuestro módulo en la experiencia de la página .
Los enlaces nofollow aún pueden terminar afectando su presupuesto de rastreo, ya que estos aún pueden terminar siendo arrastrados. Por otro lado, los enlaces que Robots.txt han no permitido no tienen ningún efecto sobre el presupuesto de rastreo.
Además, las URL alternativas y el contenido de JavaScript pueden terminar siendo rastreados, consumiendo su presupuesto de rastreo, por lo que es importante restringir el acceso a ellas al eliminarlas o usar robots.txt.
El presupuesto de rastreo es un recurso valioso y es fundamental que lo optimice. Los problemas de rastreo e indexación pueden afectar el rendimiento de su contenido, especialmente si su sitio web tiene una gran cantidad de páginas.
Las dos operaciones más fundamentales involucradas en la optimización del presupuesto de rastreo son mantener su mapa del sitio actualizado y monitorear regularmente los problemas de indexación desde el informe de estadísticas de rastreo de GSC y los archivos de registro.
Es importante aprender cómo aplicar las mejores prácticas de gestión de rastreo tanto durante el despliegue de las nuevas características del sitio web como también cuando ocurren errores únicos.