Táticas de crescimento de editores para época eleitoral | WEBINÁRIO


2.6.1 O que é um orçamento de rastreamento?
O orçamento de rastreamento é o número de páginas do seu site que um rastreador da web rastreará em um determinado período.
Cada vez que você clica no botão publicar, o Google precisa rastrear e indexar o conteúdo para que ele comece a aparecer nos resultados de pesquisa. Dada a escala e o volume de conteúdo na Internet, o rastreamento torna-se um recurso valioso que precisa ser orçado e racionado para um uso mais eficiente.
Simplificando, é difícil para o Google rastrear e indexar todas as páginas da Internet todos os dias. Assim, o Google rastreia cada site de acordo com o orçamento atribuído.
O orçamento de rastreamento é atribuído a sites com base em dois fatores: limite de rastreamento e demanda de rastreamento.
Esta é a capacidade e/ou disposição de um site de ser rastreado.
Nem todo site foi criado para ser rastreado todos os dias. O rastreamento envolve o envio de solicitações do Googlebot ao servidor do seu site que, se feitas com muita frequência, podem sobrecarregar a capacidade do servidor.
Além disso, nem todo editor deseja que seu site seja rastreado continuamente.
A demanda de rastreamento é uma medida da frequência com que uma página específica deseja ser (re)rastreada. Páginas populares ou páginas que são atualizadas com frequência precisam ser rastreadas e rastreadas novamente com mais frequência.
Se o Google não conseguir rastrear e indexar o seu conteúdo, esse conteúdo simplesmente não aparecerá nos resultados de pesquisa.
Dito isso, os orçamentos de rastreamento geralmente são uma preocupação apenas para editores de médio a grande porte que possuem mais de 10.000 páginas em seus sites. Os editores menores não deveriam precisar se preocupar excessivamente com orçamentos de rastreamento.
Os editores com 10.000 ou mais páginas em seu site, no entanto, desejam evitar páginas de rastejamento do Googlebot que não eram importantes. Esgotar seu orçamento de rastreamento com conteúdo irrelevante ou menos importante significa que as páginas de maior valor podem não estar rastreadas.
Além disso, os editores de notícias vão querer ter cuidado com os orçamentos de rastreamento desperdiçados, uma vez que rastejar é uma das três maneiras pelas quais o Google News descobre um novo conteúdo em tempo hábil. Os outros dois estão usando o Sitemaps e o Google Publisher Center, que exploramos ainda mais em nossos módulos do Google News Sitemap e do Google Publisher Center
Otimizando a frequência e a velocidade com que o Googlebot rasteja seu site envolve o monitoramento de uma variedade de variáveis. Começamos listando os fatores mais importantes envolvidos na otimização do orçamento e frequência de rastreamento.
As duas táticas mais úteis para monitorar como seu conteúdo está sendo rastreado estão analisando arquivos de log e relatório de estatísticas de rastreamento do Google Search Console (GSC).
Um arquivo de log é um documento de texto que registra todas as atividades no servidor do seu site. Isso inclui todos os dados sobre solicitações de rastreamento, solicitações de página, solicitações de imagem, solicitações de arquivos JavaScript e qualquer outro recurso necessário para executar seu site.
Para fins de SEO técnico, a análise de arquivos de log ajuda a determinar muitas informações úteis sobre o rastreamento de URL, incluindo, entre outros,:
Como fazer isso
A análise de arquivos de log é uma tarefa que requer algum grau de familiaridade técnica com o back -end de um site. Por esse motivo, recomendamos o uso de software de analisador de arquivos de log. Existem várias ferramentas de análise de log gratuitas e pagas disponíveis, como GrayLog , Loggly , Stack Elastic , Screaming Frog Log Analyzer e Nagios, para citar alguns.
Se você é um desenvolvedor experiente ou administrador do sistema, também pode executar manualmente uma análise de arquivos de log.
Para fazer isso, siga estas etapas:
Depois de baixar o arquivo de log, você pode alterar a extensão para .csv e abri -lo usando o Microsoft Excel ou o Google Sheets. Como dissemos, no entanto, essa abordagem requer um certo nível de especialização para entender o arquivo de log.
Você também pode acessar o arquivo de log usando um cliente FTP inserindo o caminho do arquivo de log. Um caminho típico do arquivo de log se parece com o seguinte:
Nome do servidor (por exemplo, apache) /var/log/access.log
No entanto, é muito mais conveniente usar uma ferramenta de análise de log. Depois de enviar o arquivo de log na ferramenta, você pode classificar os dados usando vários filtros. Por exemplo, você poderá ver quais URLs foram acessados com mais frequência pelo GoogleBot.
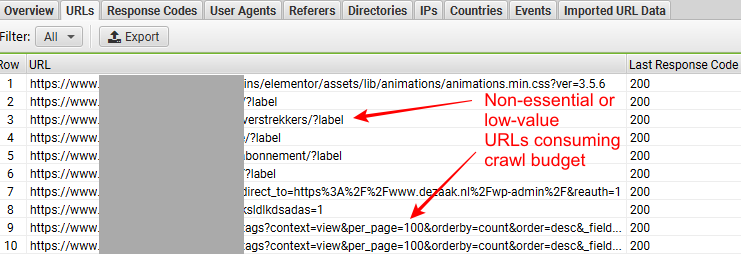
Você também poderá ver se o Googlebot está acessando URLs não essenciais ou de baixo valor, como URLs de navegação facetados, URLs duplicados, etc. Identificá-los é importante, pois estão desperdiçando seu orçamento de rastreamento.
Veja a captura de tela abaixo, tirada do Screaming Frog's Log File Analyzer, para ver o que queremos dizer.
A GSC fornece aos proprietários de sites dados e informações abrangentes sobre como o Google rasteja seu conteúdo. Isso inclui relatórios detalhados sobre:
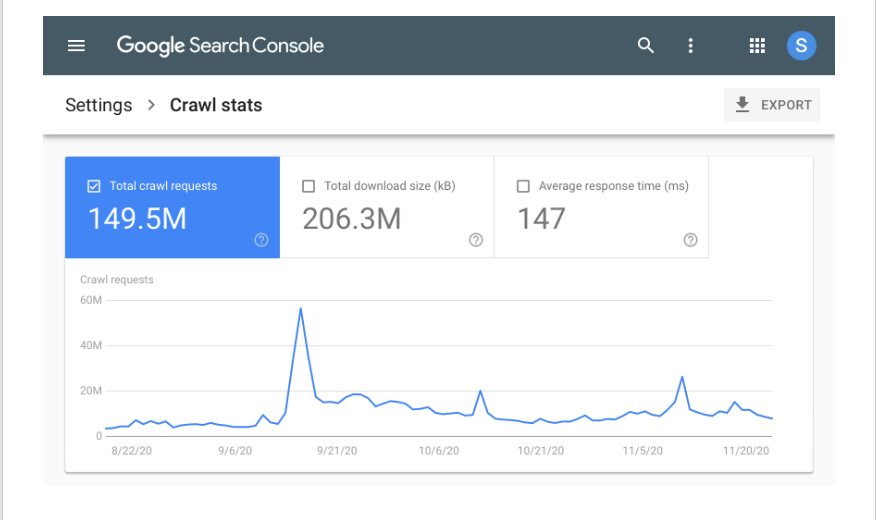
O GSC também torna os gráficos e gráficos disponíveis para fornecer ainda mais informações. A captura de tela abaixo é como é um relatório típico de estatísticas de rastreamento no GSC.
O GSC também permite que você saiba se há algum problema com o rastreamento. Ele verifica vários erros e atribui um código A cada um. Os erros mais comuns que o GSC verifica incluem:
O relatório GSC também mostra quantas páginas foram afetadas por cada erro ao lado do status de validação.
Como fazer isso
Veja como você pode acessar o relatório de estatísticas GSC Crawl para o seu site ou página da web:
Estes incluem:
Agora sabemos que o orçamento do CRAWL é um recurso valioso cujo uso deve ser otimizado para obter melhores resultados. Aqui estão algumas técnicas para fazer isso:
O conteúdo duplicado pode acabar se arrastando separadamente, levando a um desperdício de orçamento de rastreamento. Para evitar que isso aconteça, consolide páginas duplicadas em seu site em um ou exclua páginas duplicadas.
Robots.txt é um arquivo que serve a vários propósitos, um dos quais é dizer ao Googlebot para não rastejar certas páginas ou seções das páginas. Essa é uma estratégia importante que pode ser usada para impedir que o Googlebot rasteja conteúdo ou conteúdo de baixo valor que não precisa de rastreamento.
Aqui estão algumas práticas recomendadas ao usar robots.txt para otimizar o orçamento de rastreamento:
Como fazer isso
Criar e executar um arquivo robots.txt para restringir o acesso do Googlebot requer algum conhecimento de codificação. Aqui estão as etapas envolvidas:
Um arquivo típico robots.txt terá os seguintes elementos:
Abaixo está como é um arquivo robots.txt simples.
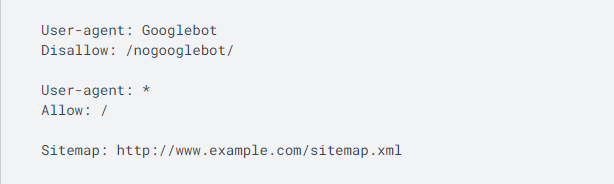
Este código significa que um agente do usuário - Googlebot nesta instância - não tem permissão para rastejar nenhum URL que começa com " http://www.example.com/nogooglebot/ ".
Sugerimos procurar ajuda especializada se você não se sentir confortável em criar e fazer upload de arquivos robots.txt.
Um bot de rastreamento chega a um site com uma alocação geral de quantas páginas irá rastrear. O mapa do site XML direciona efetivamente o bot para ler URLs selecionados, garantindo o uso eficaz desse orçamento.
Observe que o desempenho da classificação de uma página depende de vários fatores, incluindo qualidade do conteúdo e links internos/externos. Considere incluir apenas as páginas de nível superior no mapa. As imagens podem receber seu próprio mapa do site XML.
Siga estas recomendações para garantir a implementação ideal do sitemap XML:
Para uma análise mais detalhada dos sitemaps, consulte o nosso módulo dedicado neste tópico .
Os links internos desempenham três funções importantes:
Assim, para rastejamento eficiente, é importante implementar uma estratégia de vinculação interna eficiente. Para saber mais sobre a ligação interna, consulte o nosso módulo de curso detalhado aqui.
Se um site for executado em uma plataforma de hospedagem compartilhada, o Crawl Budget será compartilhado com outros sites em execução na plataforma referida. Um grande editor pode achar que a hospedagem independente é uma alternativa valiosa.
Antes de atualizar sua hospedagem para resolver a sobrecarga de tráfego de bot, há alguns fatores que valem a pena considerar que podem afetar as cargas do servidor.
Para saber mais sobre as vantagens dos CDNs, consulte o módulo de experiência da página .
Quando o Googlebot acessa uma página da web, ele renderiza todos os ativos da página, incluindo Javascript. Embora o rastreamento de HTML seja bastante simples, o Googlebot deve processar o Javascript várias vezes para poder renderizá-lo e compreender seu conteúdo.
Isso pode esgotar rapidamente o orçamento de rastreamento do Google para um site. A solução é implementar a renderização Javascript no lado do servidor.
Como fazer isso
Abordar o JavaScript no código -fonte do seu site requer experiência em codificação e recomendamos consultar um desenvolvedor da Web se você planeja fazer essas alterações. Dito isto, aqui estão algumas diretrizes sobre o que procurar ao tentar otimizar o uso do JavaScript.
Os CWVs são uma medida do desempenho da página que afeta diretamente o desempenho da sua página no ranking de pesquisa.
O relatório CWV do GSC agrupa o desempenho da URL em três categorias:
Os CWVs também podem afetar seu orçamento de rastreamento. Por exemplo, as páginas de carregamento lento podem consumir seu orçamento de rastreamento, pois o Google tem um período limitado de tempo para tarefas de rastejamento. Se suas páginas carregarem rapidamente, o Google poderá rastejar mais delas dentro do tempo limitado. Da mesma forma, muitos relatórios de status de erro podem desacelerar e desperdiçar seu orçamento de rastreamento.
Para um exame mais completo dos CWVs, consulte nosso módulo na experiência da página .
Um rastreador de terceiros, como Semrush , Sitechecker.pro ou Screaming Frog, permite que os desenvolvedores da Web auditem todos os URLs de um site e identifiquem possíveis problemas.
Os rastreadores de terceiros podem ser usados para identificar:
Esses programas oferecem um relatório de estatísticas de rastreamento para ajudar a destacar problemas que as próprias ferramentas do Google não conseguem.
Melhorar os dados estruturados e reduzir os problemas de higiene irá agilizar o trabalho do Googlebot de rastrear e indexar um site.
Recomendamos as seguintes práticas recomendadas ao usar rastreadores de terceiros:
Parâmetros de URL — a seção do endereço da web que segue o “?” — são usados em uma página por vários motivos, incluindo filtragem, paginação e pesquisa.
Embora isso possa melhorar a experiência do usuário, também pode causar problemas de rastreamento quando o URL base e outro com parâmetros retornam o mesmo conteúdo. Um exemplo disso seria “http://mysite.com” e “http://mysite.com?id=3” retornando exatamente a mesma página.
Os parâmetros permitem que um site tenha um número quase ilimitado de links – como quando um usuário pode selecionar dias, meses e anos em um calendário. Se o bot tiver permissão para rastrear essas páginas, o orçamento de rastreamento será usado desnecessariamente.
Isso pode ser especialmente um problema de preocupação se o seu site usar identificadores de navegação ou sessão facetados que podem gerar várias páginas duplicadas que, se rastreadas, podem levar a um desperdício de orçamento de rastreamento.
Os URLs duplicados também podem resultar se você tiver versões localizadas da sua página da Web em diferentes idiomas, e o conteúdo dessas páginas não foi traduzido.
Recomendamos o seguinte para abordar isso:
Aqui está como um simples<hreflang> parece em seu código -fonte:
https://examplesite.com/news/hreflang-tags "/>
Isso diz ao rastreador que o URL especificado é uma variante espanhola (mexicana) do URL principal e não deve ser tratado como uma duplicata.
Discutimos os itens essenciais da gestão do orçamento de rastreamento. Os ponteiros listados nesta seção, embora não sejam críticos para o gerenciamento de orçamento de rastreamento saudável, ajudam bastante a complementar as técnicas discutidas anteriormente.
Uma emergência de rastreamento ocorre quando o Googlebot sobrecarrega seu site com mais solicitações de rastreamento do que pode lidar. É importante identificar o problema o mais rápido possível, o que pode ser feito monitorando de perto os logs do servidor e as estatísticas de rastreamento no console de pesquisa do Google.
Se um aumento repentino no rastreamento não for gerenciado a tempo, isso pode fazer com que o servidor diminua a velocidade. A desaceleração do servidor aumentaria o tempo médio de resposta para os rastreadores e, como resultado desse alto tempo de resposta, os mecanismos de pesquisa reduzirão automaticamente sua taxa de rastreamento. Isso é problemático porque as taxas reduzidas de rastreamento levarão a uma perda de visibilidade, com novos artigos não sendo rastejados imediatamente.
Se você perceber o rastreamento está taxando seus servidores, aqui algumas coisas que você pode fazer:
O Google possui algoritmos sofisticados que controlam a taxa de rastreamento. Então, idealmente, não se deve adulterar a taxa de rastreamento. No entanto, em uma situação de emergência, você pode fazer login na sua conta GSC e navegar para as configurações de taxa de rastreamento para sua propriedade.
Se você vir a taxa de rastreamento ali calculada como ideal, não poderá alterá -la manualmente. Uma solicitação especial precisa ser apresentada ao Google para alterar a taxa de rastreamento.
Se não for esse o caso, você pode simplesmente alterar a rastreamento de rastreamento para o valor desejado. Este valor permanecerá válido por 90 dias.
Se você não deseja adulterar as taxas de rastreamento no GSC, também pode bloquear o acesso à página pelo GoogleBot usando robots.txt. O procedimento para fazer isso foi explicado anteriormente.
Pode levar o Google até três dias para rastrear a maioria dos sites. As únicas exceções são sites de notícias ou outros sites que publicam conteúdo sensível ao tempo que podem ser rastreados diariamente.
Para verificar com que frequência suas páginas estão sendo rastejadas, monitore o log do seu site. Se você ainda acha que seu conteúdo não está sendo rastreado com tanta frequência quanto deveria, siga estas etapas:
https://www.google.com/ping?sitemap=full_url_of_sitemap
Observação: esta etapa deve ser vista como a última ação que alguém deve tomar, pois carrega um certo grau de risco. Se o Googlebot vencer os erros 503 e 429, ele começará a rastejar mais devagar e poderá interromper o rastreamento, levando a uma queda temporária no número de páginas indexadas.
Um código de erro 503 significa que o servidor está temporariamente inativo, enquanto 429 significa que um usuário enviou muitas solicitações em um período específico de tempo. Esses códigos informam ao Googlebot que o problema é temporário e deve retornar a rastejar a página posteriormente.
Embora um passo aparentemente menor, isso é importante porque, se o Googlebot não conhece a natureza do problema que uma página da web está enfrentando, ele pressupõe que o problema seja de natureza de longo prazo e pode marcar a página como não respondendo, o que pode afetar o SEO.
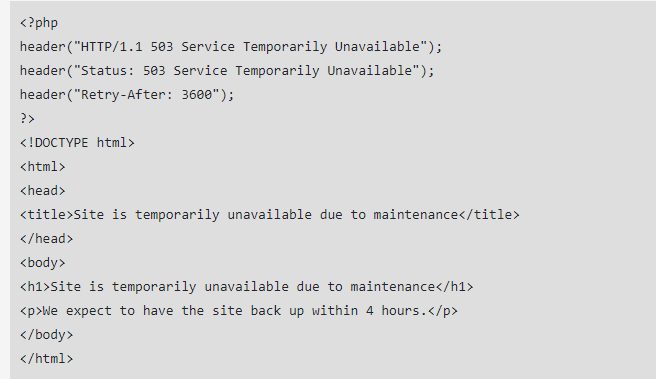
A criação de códigos de erro 503 é feita através de um arquivo php, que é inserido no código -fonte HTML existente da sua página, juntamente com uma mensagem de erro. Você também precisará escrever algumas linhas adicionais de código HTML mencionando quando o site deverá retornar.
É assim que o código para um redirecionamento 503 se parece:
Fazer 503 ou 429 redirecionamentos requer habilidades avançadas de codificação HTML e sugerimos consultar o seu desenvolvedor da Web antes de tentar isso.
Agora temos um bom entendimento do que é um orçamento de rastreamento e como otimizá -lo. No entanto, saber o que não fazer quando se trata de rastrear orçamentos é igualmente importante.
Aqui estão algumas armadilhas comuns a serem evitadas para garantir que você aproveite ao máximo o orçamento de rastreamento do seu site:
A frequência com que o Google rasteja seu site é determinada por seus algoritmos, que levam em consideração vários sinais para chegar a uma frequência ideal de rastreamento.
Aumentar a taxa de rastreamento não leva necessariamente a melhores posições nos resultados da pesquisa. A frequência de rastreamento ou mesmo rastejando em si não é um fator de classificação por si só.
O Google não prefere necessariamente conteúdo mais fresco ao conteúdo mais antigo. O Google classifica as páginas com base na relevância e na qualidade do conteúdo, independentemente de ser antigo ou novo. Portanto, não é necessário continuar com eles rastejados.
A diretiva de crawl-deLay não ajuda a controlar o Googlebot. Se você deseja desacelerar a frequência de rastreamento em resposta a rastreamento excessivo que está sobrecarregando seu site, consulte as instruções fornecidas na seção acima.
A velocidade de carregamento do seu site pode afetar seu orçamento de rastreamento. Uma página de carregamento rápido significa que o Google pode acessar mais informações sobre o mesmo número de conexões.
Para obter dicas sobre a otimização da velocidade de carregamento, consulte nosso módulo na experiência da página .
Os links nofollow ainda podem acabar afetando seu orçamento de rastreamento, pois ainda podem acabar sendo rastreados. Por outro lado, links que o robots.txt não permitiu não ter efeito no orçamento de rastreamento.
Além disso, URLs alternativos e conteúdo de JavaScript podem acabar sendo rastejados, consumindo seu orçamento de rastreamento, por isso é importante restringir o acesso a eles removendo -os ou usando robots.txt.
O orçamento de rastreamento é um recurso valioso e é fundamental que você otimize para ele. Os problemas de rastreamento e indexação podem afetar o desempenho do seu conteúdo, especialmente se o seu site tiver um grande número de páginas.
As duas operações mais fundamentais envolvidas na otimização do orçamento de rastreamento estão mantendo seu sitemap atualizado e monitorando regularmente os problemas de indexação do relatório de estatísticas do GSC Crawl e arquivos de log.
É importante aprender a aplicar as melhores práticas de gerenciamento de rastreamento durante a implantação de novos recursos do site e também quando os erros pontuais acontecem.