Chinas neues DeepSeek Large Language Model (LLM) hat den US-dominierten Markt aufgemischt und bietet ein vergleichsweise leistungsstarkes Chatbot-Modell zu deutlich geringeren Kosten.
Die geringeren Entwicklungskosten und niedrigeren Abonnementpreise im Vergleich zu US-amerikanischen KI-Tools trugen dazu bei, dass der amerikanische Chiphersteller Nvidia innerhalb eines Tages 600 Milliarden US-Dollar (480 Milliarden Pfund) an Marktwert verlor. Nvidia stellt die Computerchips her, die zum Training der meisten LLMs verwendet werden, der Basistechnologie von ChatGPT und anderen KI-Chatbots. DeepSeek nutzt die günstigeren Nvidia H800-Chips anstelle der teureren, hochmodernen Versionen.
Berichten zufolge investierte OpenAI, der Entwickler von ChatGPT, zwischen 100 Millionen und 1 Milliarde US-Dollar in die Entwicklung einer sehr aktuellen Version seines Produkts namens o1. DeepSeek hingegen absolvierte sein Training in nur zwei Monaten zu Kosten von 5,6 Millionen US-Dollar mithilfe einer Reihe cleverer Innovationen.
Doch wie gut schneidet der KI-Chatbot R1 von DeepSeek im Vergleich zu anderen, ähnlichen KI-Tools in puncto Leistung ab?
DeepSeek behauptet, seine Modelle seien mit denen von OpenAI vergleichbar und würden sogar übertreffen . Benchmarks, die Massive Multitask Language Understanding (MMLU)-Tests verwenden, bewerten jedoch Wissen in verschiedenen Fachgebieten anhand von Multiple-Choice-Fragen. Viele Sprachlernmodelle sind für solche Tests trainiert und optimiert, weshalb sie als verlässliche Indikatoren für die tatsächliche Leistungsfähigkeit in der Praxis unzuverlässig sind.
Eine alternative Methodik zur objektiven Bewertung von Sprachlernmodellen (LLMs) nutzt eine Reihe von Tests, die von Forschern der Universitäten Cardiff Metropolitan, Bristol und Cardiff – gemeinsam bekannt als Knowledge Observation Group (KOG) – entwickelt wurden. Diese Tests prüfen die Fähigkeit von LLMs, menschliche Sprache und Wissen nachzubilden, indem sie Fragen stellen, deren Beantwortung implizites menschliches Verständnis voraussetzt. Die Kerntests werden geheim gehalten, um zu verhindern, dass LLM-Anbieter ihre Modelle gezielt darauf trainieren.
KOG führte öffentliche Tests durch, die von der Arbeit von Colin Fraser, einem Datenwissenschaftler bei Meta , inspiriert waren, um DeepSeek mit anderen LLMs zu vergleichen. Folgende Ergebnisse wurden beobachtet:
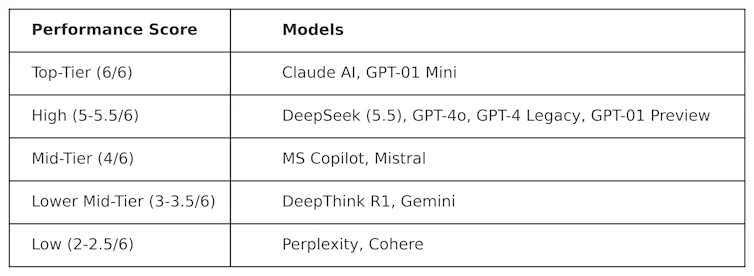
Die zur Erstellung dieser Tabelle verwendeten Tests sind „adversariell“. Das heißt, sie sind bewusst anspruchsvoll gestaltet und testen LLMs auf eine Weise, die ihrer eigentlichen Konzeption nicht gerecht wird. Daher kann die Leistung dieser Modelle in diesem Test von ihrer Leistung in gängigen Benchmark-Tests abweichen.
DeepSeek erreichte 5,5 von 6 Punkten und übertraf damit OpenAIs o1 – dessen Modell für fortgeschrittenes logisches Denken (bekannt als „Gedankenkettenmodell“) – sowie ChatGPT-4o, die kostenlose Version von ChatGPT. DeepSeek wurde jedoch von Anthropics ClaudeAI und OpenAIs o1 mini, die beide die Höchstpunktzahl von 6/6 erreichten, knapp übertroffen. Interessanterweise schnitt o1 im Vergleich zu seinem „kleineren“ Pendant, o1 mini, schlechter ab.
DeepThink R1 – ein KI-Tool zur Erstellung von Gedankenketten von DeepSeek – schnitt im Vergleich zu DeepSeek mit einer Punktzahl von 3,5 schlechter ab.
Dieses Ergebnis zeigt, wie wettbewerbsfähig der Chatbot von DeepSeek bereits ist und die Flaggschiffmodelle von OpenAI übertrifft. Es dürfte die Weiterentwicklung von DeepSeek beflügeln, da das Unternehmen nun über eine solide Basis verfügt. Allerdings hat das chinesische Technologieunternehmen ein gravierendes Problem, das andere LLMs nicht haben: Zensur.
Herausforderungen der Zensur
Trotz seiner starken Leistung und Beliebtheit wurde DeepSeek wegen seiner Antworten auf politisch sensible Themen in China kritisiert. So lautet die Antwort auf Suchanfragen zum Tiananmen-Platz, Taiwan, den Uiguren und Demokratiebewegungen beispielsweise: „Das liegt leider außerhalb meines aktuellen Aufgabenbereichs.“
Dieses Problem ist jedoch nicht auf DeepSeek beschränkt, und die potenzielle politische Einflussnahme und Zensur in LLMs im Allgemeinen gibt zunehmend Anlass zur Sorge. Auch die Ankündigung von Donald Trumps 500 Milliarden US-Dollar teurem Stargate-LLM-Projekt , an dem OpenAI, Nvidia, Oracle, Microsoft und Arm beteiligt sind, schürt die Befürchtung politischer Einflussnahme.
Darüber hinaus deutet Metas jüngste Entscheidung, die Faktenprüfung auf Facebook und Instagram einzustellen, auf einen zunehmenden Trend hin, der den Populismus gegenüber der Wahrhaftigkeit in den Hintergrund rückt.
Der Markteintritt von DeepSeek hat den Markt für Lernmanagementsysteme (LLM) erheblich verändert. US-amerikanische Unternehmen wie OpenAI und Anthropic werden gezwungen sein, ihre Produkte zu innovieren, um wettbewerbsfähig zu bleiben und hinsichtlich Leistung und Kosten mit DeepSeek mithalten zu können.
Der Erfolg von DeepSeek stellt den Status quo bereits in Frage und beweist, dass leistungsstarke LLM-Modelle auch ohne Milliardenbudgets entwickelt werden können. Er verdeutlicht zudem die Risiken der Zensur von LLM-Modellen, die Verbreitung von Fehlinformationen und die Bedeutung unabhängiger Evaluierungen.
Da LLM-Studiengänge immer stärker in die globale Politik und Wirtschaft eingebunden werden, sind Transparenz und Rechenschaftspflicht unerlässlich, um sicherzustellen, dass die Zukunft der LLM-Studiengänge sicher, nützlich und vertrauenswürdig ist.
Simon Thorne, Dozent für Informatik und Informationssysteme an der Cardiff Metropolitan University.
Dieser Artikel wurde mit freundlicher Genehmigung von The Conversation unter einer Creative-Commons-Lizenz erneut veröffentlicht. Lesen Sie den Originalartikel .