Verlage, die in eine Top-Platzierung in den Google-Suchergebnissen investieren, wissen bereits um die Bedeutung von SEO. Ein wichtiger und möglicherweise übersehener Aspekt von SEO für größere Verlage ist jedoch das Crawling-Budget von Google.
Die Crawling-Budgets von Google tragen dazu bei, zu bestimmen, in welchem Umfang Artikel in den Suchergebnissen erscheinen.
Das Verständnis von Crawling-Budgets ist ein entscheidender Schritt, um SEO-Ziele zu erreichen und die Sichtbarkeit von Inhalten zu gewährleisten. Die Überprüfung des technischen Backends einer Website erhöht die Wahrscheinlichkeit, dass das Frontend diesen Status widerspiegelt.
In diesem Artikel erklären wir, was ein Crawl-Budget ist, was das Budget beeinflusst, wie man das Crawl-Budget optimiert, wie man Crawl-Budgets überprüft und verfolgt und warum diese Budgets für das Wohlbefinden jeder Online-Seite so wichtig sind.
Was ist ein Crawl-Budget?
Das Crawl-Budget bezieht sich auf die Ressourcen, die Google für das Auffinden und die Indexierung neuer und bestehender Webseiten bereitstellt.
Googles Crawler-Bot – Googlebot – durchsucht Websites, um die Datenbank des Suchmaschinenriesen zu aktualisieren und zu erweitern. Er nutzt interne und externe Links, XML-Sitemaps, RSS- und Atom-Feeds sowie robots.txt-Dateien, um Websites so schnell wie möglich zu crawlen und zu indexieren.
Bestimmte Seiten gewinnen mit der Zeit an Autorität, während andere aus einer Reihe von Gründen, die von inhaltlichen bis hin zu technischen Einschränkungen reichen, völlig ignoriert werden können.
Zu wissen, wie man das Crawling-Budget optimal nutzt, ist für jeden Herausgeber oder jede Organisation, die auf der Website Erfolg in den Suchmaschinenergebnisseiten (SERPs) anstrebt, von unschätzbarem Wert.
Einschränkungen des Googlebots
Googlebot ist keine unerschöpfliche Ressource, und Google kann es sich nicht leisten, eine unendliche Anzahl von Webservern zu durchsuchen. Daher hat das Unternehmen Domaininhabern Anleitungen gegeben <sup>1</sup>
Das Verständnis der Funktionsweise von Bots ist grundlegend.
Wenn ein Crawler auf eine Website stößt und feststellt, dass die Analyse und Kategorisierung problematisch sein wird, verlangsamt er seine Geschwindigkeit oder geht zu einer ganz anderen Website über, je nach Umfang und Art der auftretenden Probleme.
Wenn dies passiert, ist das ein klares Zeichen dafür, dass die Website keine Optimierung des Crawling-Budgets aufweist.
Da Googlebot nur über begrenzte Ressourcen verfügt, sollte dies für jeden Website-Betreiber Grund genug sein, sich Gedanken über das Crawling-Budget zu machen. Allerdings sind nicht alle Websites im gleichen Maße von diesem Problem betroffen.
Für wen ist das relevant und warum?
Obwohl jeder Website-Betreiber den Erfolg seiner Website wünscht, müssen sich eigentlich nur mittelgroße und große Websites, die ihre Inhalte regelmäßig aktualisieren, Gedanken über Crawling-Budgets machen.
Google definiert mittelgroße Websites als solche mit mehr als 10.000 einzigartigen Seiten, die täglich aktualisiert werden. Große Websites hingegen haben über 1 Million einzigartige Seiten und werden mindestens einmal pro Woche aktualisiert.
Google weist auf den Zusammenhang zwischen Crawling-Aktivität und größeren Websites hin und erklärt: „Für größere Websites oder solche, die beispielsweise Seiten automatisch anhand von URL-Parametern generieren, ist es wichtiger zu priorisieren, was wann gecrawlt werden soll und wie viele Ressourcen der Server, auf dem die Website gehostet wird, für das Crawling bereitstellen kann.“ ²
Websites mit wenigen Seiten müssen sich keine allzu großen Sorgen um das Crawling-Budget machen. Da einige Publisher jedoch schnell expandieren könnten, ist ein grundlegendes Verständnis von Crawling-Statistiken und -Abläufen für alle Website-Betreiber von Vorteil, um zukünftig von einem höheren Website-Traffic zu profitieren.
Was beeinflusst Googles Crawling-Budget?
Der Umfang, in dem Google eine Website crawlt, wird durch die Crawl-Kapazitätsgrenzen und die Crawl-Nachfrage bestimmt.
Um zu verhindern, dass die Crawling-Aktivität einen Host-Server überlastet, wird die Kapazitätsgrenze berechnet, indem die maximale Anzahl gleichzeitiger, paralleler Verbindungen, die der Bot zum Crawlen der Website nutzen kann, sowie die Zeitverzögerung zwischen den Datenrückgaben festgelegt werden.
Kriechkapazitätsgrenze
Diese Kennzahl, die auch als Kriechgeschwindigkeitsgrenze bezeichnet wird, ist dynamisch und hängt von Änderungen dreier Faktoren ab:
- Crawling-Status : Wenn die Website fehlerfrei und ohne Verzögerung reagiert und die Website-Geschwindigkeit gut ist, kann das Limit erhöht werden und umgekehrt.
- GSC-Crawling-Rate : Die Google Search Console (GSC) kann verwendet werden, um die Crawling-Aktivität zu reduzieren . Diese Funktion kann bei längeren Website-Wartungsarbeiten oder -Aktualisierungen hilfreich sein. 3 Alle Änderungen bleiben 90 Tage lang aktiv . 4
Wenn die Crawling-Rate auf „Optimal berechnet“ eingestellt ist, kann sie nicht erhöht werden; eine Senkung ist nur auf Anfrage möglich. Falls eine Website übermäßig gecrawlt wird und dies zu Problemen mit der Verfügbarkeit und/oder dem Seitenaufbau führt, können Sie das Crawling und die Indexierung mithilfe der robots.txt-Datei blockieren. Diese Maßnahme kann jedoch bis zu 24 Stunden dauern.
Auch wenn viele Websites keine Sanktionen wegen Crawling-Limits verhängen, kann es dennoch ein nützliches Werkzeug sein.
Kriechbedarf
Die Crawl-Nachfrage ist ein Ausdruck dafür, wie groß das Interesse von Google an der Indexierung einer Website ist. Auch sie wird von drei Faktoren beeinflusst:
- Wahrgenommener Bestand : Ohne Vorgaben des Website-Betreibers – worauf wir später noch eingehen werden – versucht Google, jede URL zu crawlen, einschließlich Duplikaten, defekten Links und weniger wichtigen Seiten. Hier kann die Einschränkung der Suchparameter des Googlebots das Crawling-Budget erhöhen.
- Popularität : Wenn eine Website extrem populär ist, werden ihre URLs häufiger gecrawlt.
- Aktualisierung : Das Googlebot-System ist in der Regel darauf ausgerichtet, Seiten erneut zu crawlen, um Änderungen zu erfassen. Dieser Prozess kann durch die Nutzung der Google Search Console (GSC) und die Anforderung erneuter Crawls beschleunigt werden, allerdings kann nicht garantiert werden, dass die Anfrage sofort bearbeitet wird.
Die Crawl-Aktivität ist im Wesentlichen ein Produkt solider Website-Verwaltung.
Bedenken des CMS
Vahe Arabian , Gründer von State of Digital Publishing (SODP) , erklärt, dass Elemente von Content-Management-Systemen (CMS) – wie beispielsweise Plug-ins – Auswirkungen auf das Crawling-Budget haben können.⁵
Er sagte: „Viele Plug-ins sind stark datenbankorientiert und führen zu einer erhöhten Ressourcenlast, was die Seitenladezeit verlangsamt oder unnötige Seiten erzeugt und die Crawlbarkeit beeinträchtigt.“
Das werbefinanzierte Umsatzmodell einer Website kann ähnliche Probleme verursachen, wenn mehrere Website-Funktionen ressourcenintensiv sind.
Wie man Crawl-Budgets prüft und verfolgt
Es gibt zwei wichtige Methoden, um Crawling-Budgets zu verfolgen: die Google Search Console (GSC) und/oder Serverprotokolle. 6
Google Search Console
Bevor die Crawling-Raten einer Website in der Google Search Console (GSC) überprüft werden können, muss die Domaininhaberschaft bestätigt werden.
Die Konsole verfügt über drei Tools, mit denen Webseiten überprüft werden können, um festzustellen, welche URLs funktionieren und welche noch nicht indexiert wurden.
Die Konsole prüft auf Ungenauigkeiten in der Domäne und bietet Vorschläge zur Behebung verschiedener Crawling-Fehler.
GSC unterteilt Statusfehler in seinem Indexabdeckungsbericht in verschiedene Kategorien, darunter:
- Serverfehler [5xx]
- Umleitungsfehler
- Die übermittelte URL wurde durch robots.txt blockiert
- Eingereichte URL mit dem Hinweis „noindex“ gekennzeichnet
- Die angegebene URL scheint ein Soft-404-Fehler zu sein
- Die übermittelte URL liefert eine nicht autorisierte Anfrage (401)
- Die angegebene URL wurde nicht gefunden (404)
- Die übermittelte URL lieferte den Fehlercode 403 zurück:
- Die übermittelte URL wurde aufgrund eines anderen 4xx-Fehlers blockiert
Der Bericht gibt an, wie viele Seiten von jedem Fehler betroffen sind, sowie den Validierungsstatus.
Das URL-Prüftool liefert Indexierungsinformationen zu jeder beliebigen Seite, während der Crawl-Statistikbericht Aufschluss darüber gibt, wie häufig Google eine Website crawlt, wie reaktionsschnell der Server der Website ist und ob es damit verbundene Verfügbarkeitsprobleme gibt.
Für die Identifizierung und Behebung jedes Fehlers gibt es ein festgelegtes Vorgehen. Dieses reicht von der Erkenntnis, dass ein Site-Server zum Zeitpunkt des Crawlings möglicherweise nicht erreichbar war, bis hin zur Verwendung einer 301-Weiterleitung, um auf eine andere Seite umzuleiten, oder dem Entfernen von Seiten aus der Sitemap.
Wenn sich der Seiteninhalt wesentlich geändert hat, kann mit der Schaltfläche „Indexierung anfordern“ des URL-Inspektionstools ein Seiten-Crawling gestartet werden.
Auch wenn es nicht unbedingt notwendig ist, jeden einzelnen Seitenfehler zu „beheben“, ist es definitiv ratsam, Probleme zu minimieren, die Crawling-Bots verlangsamen.
Serverprotokolle verwenden
Alternativ zur Google Search Console (GSC) kann der Crawling-Status einer Website über Serverprotokolle überprüft werden, die nicht nur jeden Website-Besuch, sondern auch jeden Besuch des Googlebots aufzeichnen.
Für alle, die es noch nicht wissen: Server erstellen und speichern automatisch einen Logeintrag, sobald Googlebot oder ein Benutzer eine Seite anfordert. Diese Logeinträge werden anschließend in einer Logdatei gesammelt.
Sobald eine Logdatei geöffnet wurde, muss sie analysiert werden. Angesichts des enormen Umfangs der Logeinträge sollte diese Aufgabe jedoch nicht unterschätzt werden. Je nach Größe der Website kann eine Logdatei leicht Hunderte Millionen oder sogar Milliarden von Einträgen enthalten.
Sollte die Entscheidung getroffen werden, die Protokolldatei zu analysieren, müssen die Daten entweder in eine Tabellenkalkulation oder in eine proprietäre Software exportiert werden, um den Analyseprozess zu erleichtern.
Die Analyse dieser Aufzeichnungen zeigt, auf welche Art von Fehlern ein Bot gestoßen ist, welche Seiten am häufigsten aufgerufen wurden und wie oft eine Website gecrawlt wurde.
9 Möglichkeiten zur Optimierung des Crawl-Budgets
Zur Optimierung gehört, wie bereits erwähnt, die Überprüfung und Verfolgung von Website-Gesundheitsstatistiken sowie die direkte Bearbeitung von Problembereichen.
Nachfolgend stellen wir Ihnen unser Toolkit zur Optimierung des Crawling-Budgets vor, mit dem wir auftretende Probleme der Crawlbarkeit beheben.
1. Doppelte Inhalte zusammenführen
Crawling-Probleme können auftreten, wenn eine Seite über mehrere verschiedene URLs erreichbar ist oder Inhalte enthält, die an anderer Stelle auf der Website dupliziert sind. Der Bot betrachtet diese Beispiele als Duplikate und wählt eines davon als kanonische Version aus.
Die übrigen URLs werden als weniger wichtig eingestuft und seltener oder gar nicht mehr gecrawlt. 10 Das ist unproblematisch, solange Google die gewünschte kanonische Seite auswählt; andernfalls stellt es ein schwerwiegendes Problem dar.
Allerdings kann es durchaus triftige Gründe für doppelte Seiten geben, beispielsweise den Wunsch, mehrere Gerätetypen zu unterstützen, die Inhaltssyndizierung zu ermöglichen oder dynamische URLs für Suchparameter oder Sitzungs-IDs zu verwenden.
Empfehlungen von SODP :
- Den Website-Inhalt nach Möglichkeit kürzen
- Verwenden Sie 301-Weiterleitungen, um URLs zu konsolidieren und Inhalte zusammenzuführen
- Inhalte mit geringer Leistung löschen
- Durch die Verwendung von 301-Weiterleitungen nach einer Website-Umstrukturierung werden Benutzer, Bots und andere Crawler dorthin geleitet, wo sie hin müssen.
- Verwenden Sie noindex für dünne Seiten, Paginierung (für ältere Archive) und zum Kannibalisieren von Inhalten.
- Falls doppelter Inhalt zu übermäßigem Crawling führt, passen Sie die Einstellung für die Crawling-Rate in der Google Search Console (GSC) an.
2. Verwenden Sie die robots.txt-Datei
Diese Datei hilft, zu verhindern, dass Bots eine gesamte Website durchsuchen. Mithilfe der Datei können einzelne Seiten oder Seitenabschnitte vom Suchvorgang ausgeschlossen werden.
Diese Option gibt dem Herausgeber die Kontrolle darüber, was indexiert wird, wodurch bestimmte Inhalte privat bleiben und gleichzeitig die Verwendung des Crawl-Budgets verbessert wird.
Empfehlungen von SODP :
- Ordnen Sie die Parameter nach Priorität, um diejenigen Parameter zu priorisieren, deren Crawling blockiert werden soll.
- Anhand von Protokolldateien können Sie die Roboter, Direktiven und Parameter identifizieren, die zusätzliche Crawls verursachen.
- Blockieren Sie gängige Pfade, die CMS typischerweise haben, wie z. B. 404-Seiten, Admin-Seiten, Anmeldeseiten usw.
- Vermeiden Sie die Verwendung der Crawl-Delay-Direktive zur Reduzierung des Bot-Traffics und damit zur Verbesserung der Serverleistung. Dies wirkt sich ausschließlich auf die Indexierung neuer Inhalte aus.
3. Segmentieren Sie XML-Sitemaps, um eine schnellere Inhaltserfassung zu gewährleisten
Ein Crawler-Bot erreicht eine Website mit einem allgemeinen Budget für die zu durchsuchenden Seiten. Die XML-Sitemap weist den Bot gezielt an, die ausgewählten URLs zu lesen und gewährleistet so die effiziente Nutzung dieses Budgets.
Beachten Sie, dass die Ranking-Performance einer Seite von verschiedenen Faktoren abhängt, darunter die Inhaltsqualität und interne/externe Links. Erwägen Sie, nur Seiten der obersten Kategorie in die Sitemap aufzunehmen. Bildern kann eine eigene XML-Sitemap zugewiesen werden.
Empfehlungen von SODP :
- Verweisen Sie auf die XML-Sitemap aus der robots.txt-Datei.
- Erstellen Sie für eine sehr große Website mehrere Sitemaps. Fügen Sie einer einzelnen XML-Sitemap nicht mehr als 50.000 URLs hinzu.
- Halten Sie es übersichtlich und fügen Sie nur indexierbare Seiten hinzu.
- Halten Sie die XML-Sitemap auf dem neuesten Stand.
- Die Dateigröße sollte unter 50 MB liegen.
4. Die interne Verlinkungsstrategie untersuchen
Google verfolgt das Linknetzwerk innerhalb einer Website, und Seiten mit mehreren Links werden als wertvoll angesehen und es lohnt sich, das Crawling-Budget dafür aufzuwenden.
Allerdings sollte man beachten, dass zwar eine begrenzte Anzahl interner Links das Crawling-Budget belasten kann, aber auch eine übermäßige Verlinkung der gesamten Website.
Seiten ohne interne Verlinkungen erhalten keine Linkstärke vom Rest der Website, was Google dazu veranlasst, sie als weniger wertvoll einzustufen.
Gleichzeitig teilen hochwertige Seiten mit vielen internen Links ihre Linkstärke gleichmäßig unter anderen Seiten auf, unabhängig von deren strategischem Wert. Vermeiden Sie daher Links zu Seiten, die Lesern wenig Mehrwert bieten.
Eine interne Verlinkungsstrategie erfordert Fingerspitzengefühl, um sicherzustellen, dass hochwertige Seiten genügend Links erhalten, während minderwertige Seiten die Linkstärke nicht kannibalisieren.
5. Hosting-Upgrade durchführen, falls gleichzeitiger Datenverkehr ein Engpass ist
Wenn eine Website auf einer Shared-Hosting-Plattform läuft, wird das Crawling-Budget mit anderen Websites auf derselben Plattform geteilt. Für große Unternehmen kann unabhängiges Hosting eine sinnvolle Alternative darstellen.
Weitere Aspekte, die Sie bei der Aktualisierung Ihres Hostings oder sogar schon vor der Aktualisierung berücksichtigen sollten, um eine Überlastung durch Bot-Traffic zu beheben, die die Serverlast beeinträchtigen kann:
- Die Bildverarbeitung erfolgt über ein separates CDN, das auch für die Bereitstellung von Bildformaten der nächsten Generation wie WebP optimiert ist
- Berücksichtigen Sie bei der Auswahl von CPU und Festplattenspeicher die Funktionen und Anforderungen Ihrer Website
- Überwachen Sie die Aktivitäten mithilfe von Lösungen wie New Relic, um übermäßige Nutzung von Plugins und Bots zu überwachen
6. JavaScript-Nutzung ausbalancieren
Wenn Googlebot auf eine Webseite gelangt, rendert er alle Ressourcen dieser Seite, einschließlich JavaScript. Während das Crawlen von HTML relativ einfach ist, muss Googlebot JavaScript mehrmals verarbeiten, um es darstellen und seinen Inhalt verstehen zu können.
Dies kann das Crawling-Budget von Google für eine Website schnell aufbrauchen. Die Lösung besteht darin, das JavaScript-Rendering serverseitig zu implementieren.
Indem Crawler vermeiden, JavaScript-Ressourcen zum Rendern an den Client , verbrauchen sie weniger Ressourcen und können effizienter arbeiten. 11
Empfehlungen von SODP :
- Verwenden Sie Lazy Loading auf Browserebene anstelle von JavaScript
- Ermitteln, ob Elemente
- Verwenden Sie serverseitiges Tagging für Analysen und Drittanbieter-Tagging, entweder selbst gehostet oder mithilfe von Lösungen wie https://stape.io/ . 12
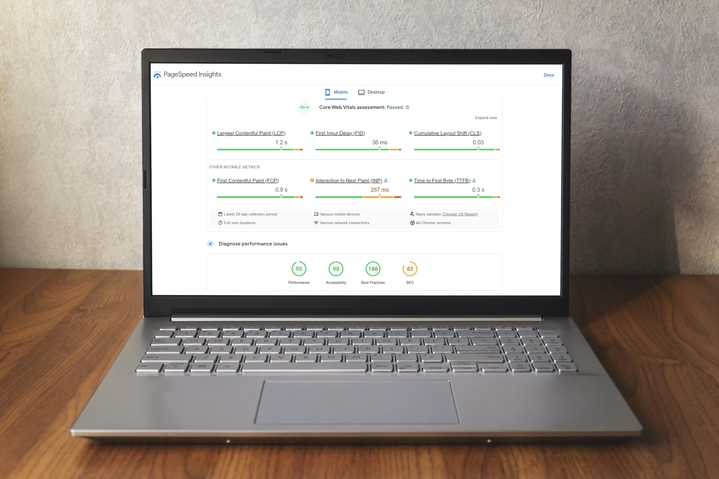
7. Aktualisieren Sie die Core Web Vitals (CWV), um die Seitennutzung zu verbessern
Die Core Web Vitals (CWV) der Google Search Console (GSC) verwenden sogenannte „ reale Nutzungsdaten “, um die Seitenleistung anzuzeigen. 13
Der CWV-Bericht unterteilt die URL-Performance in drei Kategorien:
- Metrischer Typ (LCP, FID und CLS)
- Status
- URL-Gruppen
Metrisch
Der CWV-Bericht basiert auf den Metriken Largest Contentful Paint ( LCP), First Input Delay (FID) und Cumulative Layout Shift (CLS) .
LCP bezieht sich auf die Zeit, die benötigt wird, um das größte Inhaltselement im sichtbaren Bereich der Webseite darzustellen.
FID bezieht sich auf die Zeit, die eine Seite benötigt, um auf die Interaktion eines Benutzers zu reagieren.
CLS ist ein Maß dafür, wie stark sich das Seitenlayout während der Benutzersitzung verändert, wobei höhere Werte eine schlechtere Benutzererfahrung darstellen.
Status
Nach der Auswertung einer Seite wird jeder Kennzahl eine von drei Statusstufen zugewiesen:
- Gut
- Verbesserungsbedarf
- Arm
URL-Gruppen
Der Bericht kann auch Probleme einer Gruppe ähnlicher URLs zuordnen, vorausgesetzt, dass Leistungsprobleme, die ähnliche Seiten betreffen, auf ein gemeinsames Problem zurückzuführen sind.
CWV und Kriechfähigkeit
Wie bereits erwähnt, verschwendet Googlebot umso mehr Crawling-Budget, je länger er auf einer Seite verweilt. Daher können Publisher die CWV-Berichte nutzen, um die Seiteneffizienz zu optimieren und die Crawling-Zeit zu verkürzen.
von SODP mit Schwerpunkt auf WordPress:
| Tipps zur Geschwindigkeitsverbesserung | Implementieren über | Validieren auf |
| Bilder in das WebP-Format konvertieren | Wenn CDN aktiviert ist, konvertieren Sie die Datei über das CDN oder installieren Sie das EWWW-Plugin | https://www.cdnplanet.com/tools/cdnfinder/ |
| Implementieren Sie SRCSET und prüfen Sie unter https://pagespeed.web.dev/ , ob das Problem mit der korrekten Bildgröße behoben ist. | Implementieren Sie dies durch manuelles Hinzufügen von Code | Überprüfen Sie im Browsercode, ob alle Bilder den SRCSET-Code besitzen |
| Browser-Caching aktivieren | WP-Rakete | https://www.giftofspeed.com/cache-checker/ |
| Lazy Loading-Bilder | WP-Rakete | Überprüfen Sie in der Browserkonsole, ob der Lazyload-Code dem Bild hinzugefügt wurde. Ausgenommen ist das Beitragsbild. |
| Externe Skripte verzögern: Nur die Skripte im<body> kann aufgeschoben werden | WP Rocket oder ein schnelleres Website-Plugin (auch bekannt als defer.js) | Nach dem Hinzufügen des defer-Tags prüfen Sie unter https://pagespeed.web.dev/ , ob das Problem mit der Reduzierung ungenutzten JavaScript-Codes behoben ist. |
| Nicht verwendete JS- und CSS-Dateien identifizieren und entfernen | Manuell | |
| Gzip-Komprimierung aktivieren | Serverseitig wenden Sie sich bitte an Ihren Hosting-Anbieter | https://www.giftofspeed.com/gzip-test/ |
| JS und CSS minimieren | WP-Rakete | https://pagespeed.web.dev/ |
| Schriftarten lokal laden oder Webfonts vorladen | Plugin für Schriftarten verwenden oder die Schriftartdateien auf den Server hochladen und per Code im Header hinzufügen | |
| CDN aktivieren | Cloudflare (oder einen anderen CDN-Dienst) und konfigurieren Sie ihn für die Website |
8. Verwenden Sie einen Crawler eines Drittanbieters
Ein Drittanbieter-Crawler wie Semrush, Sitechecker.pro oder Screaming Frog ermöglicht es Webentwicklern, alle URLs einer Website zu überprüfen und potenzielle Probleme zu identifizieren.
Crawler können zur Identifizierung folgender Systeme verwendet werden:
- Defekte Links
- Doppelte Inhalte
- Fehlende Seitentitel
Diese Programme bieten einen Crawling-Statistikbericht, der dazu beiträgt, Probleme aufzuzeigen, die von Googles eigenen Tools möglicherweise nicht erkannt werden.
Die Verbesserung strukturierter Daten und die Reduzierung von Hygieneproblemen werden die Aufgabe des Googlebots beim Crawlen und Indexieren einer Website optimieren.
Empfehlungen von SODP :
- Verwenden Sie SQL-Abfragen, um Fehler in Stapelverarbeitung zu aktualisieren, anstatt jedes Problem manuell zu beheben.
- Emulieren Sie Googlebot über die Such-Crawling-Einstellungen, um zu verhindern, dass Sie von Hosting-Anbietern blockiert werden, und um alle technischen Probleme ordnungsgemäß zu identifizieren und zu beheben.
- Beheben Sie fehlende Seiten nach einem Crawl mithilfe dieser hervorragenden Anleitung von Screaming Frog . 17
9. URL-Parameter
URL-Parameter – der Teil der Webadresse, der auf das „?“ folgt – werden auf einer Seite aus verschiedenen Gründen verwendet, unter anderem zum Filtern, zur Paginierung und zur Suche.
Dies kann zwar die Benutzerfreundlichkeit verbessern, aber auch zu Crawling-Problemen führen, wenn sowohl die Basis-URL als auch die URL mit Parametern denselben Inhalt zurückgeben. Ein Beispiel hierfür wären „http://mysite.com“ und „http://mysite.com?id=3“, die exakt dieselbe Seite anzeigen.
Parameter ermöglichen einer Website eine nahezu unbegrenzte Anzahl an Links – beispielsweise wenn ein Nutzer in einem Kalender Tage, Monate und Jahre auswählen kann. Wenn der Bot diese Seiten crawlen darf, wird das Crawling-Budget unnötig verbraucht.
Empfehlungen von SODP :
- Verwenden Sie robots.txt-Regeln. Geben Sie beispielsweise die Reihenfolge der Parameter in einer Allow-Direktive an.
- Verwenden Sie hreflang, um die Sprachvarianten des Inhalts anzugeben.
Zusammenfassung der Mythen und Fakten zum Googlebot
Es gibt einige Missverständnisse bezüglich der Leistungsfähigkeit und des Umfangs von Googlebot.
Hier sind fünf, die wir untersucht haben:
1. Googlebot durchsucht eine Website nur zeitweise
Googlebot durchsucht Websites tatsächlich recht häufig und in manchen Fällen sogar täglich. Die Häufigkeit hängt jedoch von der wahrgenommenen Qualität, Aktualität, Relevanz und Popularität der Website ab.
Wie bereits erwähnt, kann die Google Search Console (GSC) verwendet werden, um einen Crawl anzufordern.
2. Googlebot trifft Entscheidungen über das Website-Ranking
laut Martin Splitt , WebMaster Trends Analyst bei Google, mittlerweile als einen separaten Teil des Crawling-, Indexierungs- und Ranking-Prozesses.<sup> 18</sup>
Es ist jedoch auch wichtig zu beachten, dass der Inhalt einer Website, die Sitemap, die Anzahl der Seiten, die Links, die URLs usw. allesamt Faktoren sind, die bei der Bestimmung ihres Rankings eine Rolle spielen.
Im Wesentlichen können geschickte SEO-Entscheidungen von Verlagen zu einer soliden Positionierung in den Suchergebnissen führen.
3. Googlebot dringt in private Bereiche einer Website ein
Der Bot kennt kein Konzept von „privaten Inhalten“ und ist lediglich mit der Indexierung von Websites beauftragt, sofern er nicht vom Website-Inhaber anders angewiesen wird.
Bestimmte Webseiten können so lange unindexiert bleiben, wie die notwendigen Schritte innerhalb der GSC unternommen werden, um den Zugriff einzuschränken.
4. Die Aktivität des Googlebots kann die Funktionsfähigkeit der Website beeinträchtigen
Der Googlebot-Prozess hat seine Grenzen, sowohl aufgrund der begrenzten Ressourcen von Google als auch weil Google eine Website nicht stören möchte.
Splitt sagte: „Wir tasten uns langsam heran und steigern dann das Tempo. Und wenn wir Fehler feststellen, drosseln wir das Tempo wieder etwas.“15
Der GSC kann Crawling-Vorgänge verzögern, und da manche Websites mehrere hunderttausend Seiten umfassen, teilt Googlebot seinen Crawl auf mehrere Besuche auf.
5. Googlebot ist der einzige Bot, vor dem man sich fürchten sollte
Googlebot ist zwar der weltweit führende Crawler, aber nicht alle Bots gehören Google. Auch andere Suchmaschinen durchsuchen das Web, und es sind Bots aktiv, die sich auf Analysen sowie Daten- und Markensicherheit konzentrieren.
Gleichzeitig entwickeln Kriminelle immer ausgefeiltere Software, um Anzeigenbetrug zu begehen , Inhalte zu stehlen, Spam zu verbreiten und vieles mehr. 19
Schlussbetrachtung
Es ist wichtig zu beachten, dass sowohl die Optimierung des Crawl-Budgets als auch positive Nutzererfahrungen miteinander verbunden werden können, ohne das jeweils andere zu beeinträchtigen
Die Überprüfung des Zustands des Crawl-Budgets einer Website sollte Bestandteil der Wartungsprogramme aller Website-Betreiber sein, wobei die Häufigkeit dieser Überprüfungen von der Größe und Art der Website selbst abhängt.
die technische Instandhaltung – wie das Reparieren defekter Links, nicht funktionierender Seiten, doppelter Inhalte, schlecht formulierter URLs und alter, fehlerhafter Sitemaps – ist unerlässlich.
- Crawl-Budgetverwaltung für große Websites | Google Search Central | Dokumentation
- Was das Crawl-Budget für Googlebot bedeutet | Google Search Central Blog
- Googlebot-Crawlingrate reduzieren | Google Search Central | Dokumentation
- Googlebot-Crawlingrate ändern – Hilfe zur Search Console
- Optimierung des Crawl-Budgets für Verlage | Stand des digitalen Publizierens
- Google Search Console
- Indexabdeckungsbericht – Hilfe der Search Console
- URL-Prüftool – Hilfe zur Search Console
- Crawl-Statistikbericht – Hilfe zur Search Console
- Doppelte URLs mit Canonical-Tags konsolidieren | Google Search Central | Dokumentation
- Web-Rendering | Google Developers
- Stape.io
- Core Web Vitals-Bericht – Hilfe zur Search Console
- Größte Inhaltsfarbe (LCP)
- Erste Eingangsverzögerung (FID)
- Kumulative Layoutverschiebung (CLS)
- Wie man fehlende Seiten in einem Crawler behebt – Screaming Frog
- Googlebot: SEO-Mythen entlarvt
- Anzeigenbetrug: Alles, was Sie wissen müssen | Publift