

Die Stimmungslage gegenüber generativer KI erfährt nach den Fehltritten von Google und Microsoft bei der Implementierung von LLMs eine Kurskorrektur.
Verlage setzen sich nun mit den praktischen Auswirkungen eines Tools auseinander, das im Handumdrehen Unmengen an Texten für Nutzer mit sehr geringer Schreiberfahrung generieren kann. Die Bedenken wachsen Flut von minderwertigen, von KI geschriebenen Geschichten Die Einreichungsstellen werden überflutet. Andere stellen derweil ernsthafte Fragen darüber, woher die KI die Daten bezieht, die sie wiederverwendet.

Anmerkung der Redaktion: Monetarisierung im Zeitalter der KI
Die Stimmungslage gegenüber generativer KI hat sich nach den Fehltritten von Google und Microsoft bei der Implementierung von LLMs (Licensed Learning Models) gewandelt. Verlage setzen sich nun mit den praktischen Auswirkungen eines solchen Tools auseinander…
Aktualisiert am: 1. Dezember 2025
Inhaltsverzeichnis
Abonnieren Sie KI-Einblicke
- Aktuelle Pubtech-Ressourcen
- Überblick über Pubtech- und Adtech-Tools
- Wertvolle Pubtech-Strategien

Ähnliche Beiträge
-

Tokenisierte Aktionärsvergütungen – Was das für den Finanzjournalismus bedeutet
-

So bauen Sie Ihr eigenes Werbenetzwerk auf: Eine Schritt-für-Schritt-Anleitung
-

Die Geschichte, wie der Herausgeber von RollerAds 60.000 Dollar verdiente
-

Der Verlag nutzte eigene Daten, um im vierten Quartal Gewinne zu erzielen
-

Die größten Listenanbieter im Internet sind im Vorteil, während traditionelle Websites ins Hintertreffen geraten
-
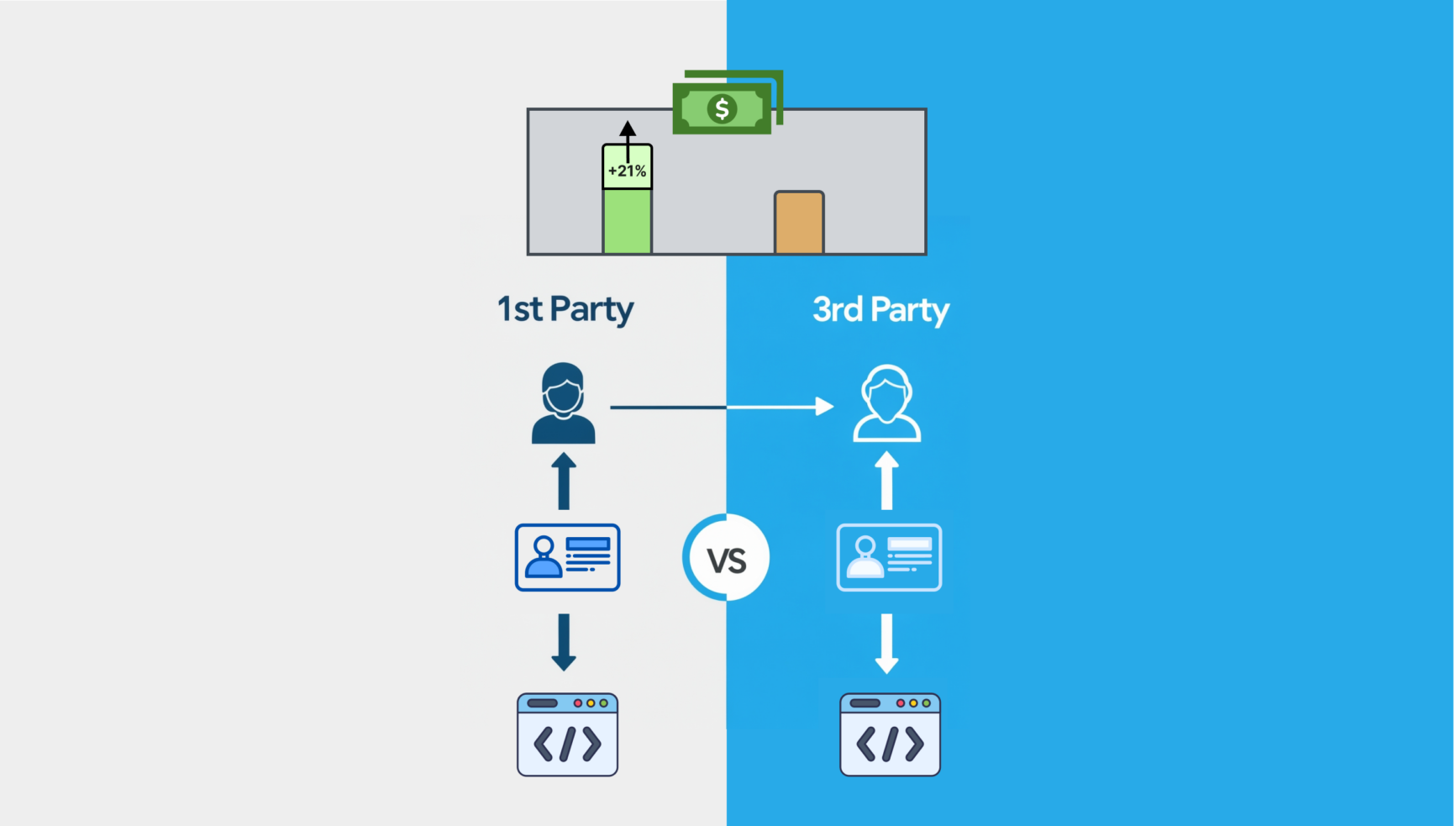
Websites, die höhere TKPs durch den Einsatz von Anzeigen-IDs und First-Party-Datenlösungen erzielen
-

Ethereum-basiertes Publizieren: Können Kryptozahlungen die Autorenhonorare neu definieren?
-

Aufbau des optimalen Monetarisierungsteams







State of Digital Publishing schafft eine neue Publikation und Community für Fachleute aus den Bereichen digitale Medien und Verlagswesen, neue Medien und Technologien.
Stand des digitalen Publizierens – Urheberrecht 2026



