Kinas nye DeepSeek Large Language Model (LLM) har forstyrret det USA-dominerte markedet , og tilbyr en relativt høytytende chatbot-modell til betydelig lavere kostnad.
De reduserte utviklingskostnadene og lavere abonnementspriser sammenlignet med amerikanske AI-verktøy bidro til at den amerikanske brikkeprodusenten Nvidia tapte 600 milliarder amerikanske dollar (480 milliarder pund) i markedsverdi på én dag. Nvidia lager databrikkene som brukes til å trene de fleste LLM-er, den underliggende teknologien som brukes i ChatGPT og andre AI-chatboter. DeepSeek bruker billigere Nvidia H800-brikker fremfor de dyrere, toppmoderne versjonene.
ChatGPT-utvikleren OpenAI skal ha brukt mellom 100 millioner og 1 milliard amerikanske dollar på utviklingen av en svært ny versjon av produktet sitt, kalt o1. DeepSeek fullførte derimot opplæringen på bare to måneder til en kostnad av 5,6 millioner amerikanske dollar ved hjelp av en rekke smarte innovasjoner.
Men hvor godt klarer DeepSeeks AI-chatbot, R1, seg i forhold til andre lignende AI-verktøy når det gjelder ytelse?
DeepSeek hevder at modellene deres yter på nivå med OpenAIs tilbud, og til og med overgår o1-modellen i visse benchmark-tester. Benchmark-tester som bruker Massive Multitask Language Understanding (MMLU)-tester evaluerer imidlertid kunnskap på tvers av flere fag ved hjelp av flervalgsspørsmål. Mange LLM-er er trent og optimalisert for slike tester, noe som gjør dem upålitelige som sanne indikatorer på ytelse i den virkelige verden.
En alternativ metode for objektiv evaluering av LLM-er bruker et sett med tester utviklet av forskere ved universitetene i Cardiff Metropolitan, Bristol og Cardiff – samlet kjent som Knowledge Observation Group (KOG). Disse testene undersøker LLM-enes evne til å etterligne menneskelig språk og kunnskap gjennom spørsmål som krever implisitt menneskelig forståelse for å kunne besvares. Kjernetestene holdes hemmelige for å unngå at LLM-selskaper trener modellene sine for disse testene.
KOG implementerte offentlige tester inspirert av arbeidet til Colin Fraser, en dataforsker ved Meta , for å evaluere DeepSeek mot andre LLM-er. Følgende resultater ble observert:
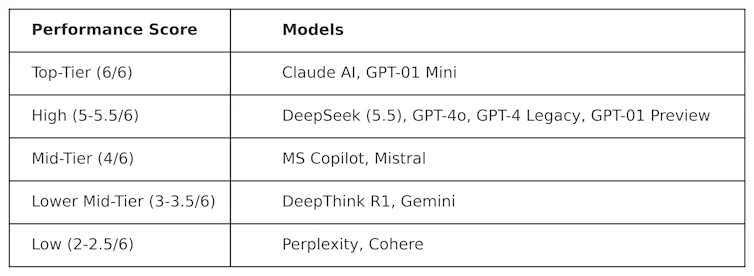
Testene som brukes til å lage denne tabellen er av «kontradisjonell» art. Med andre ord er de utformet for å være «harde» og for å teste LLM-er på måter som ikke er sympatiske for hvordan de er utformet. Dette betyr at ytelsen til disse modellene i denne testen sannsynligvis vil være annerledes enn ytelsen i vanlige benchmarkingtester.
DeepSeek fikk en score på 5,5 av 6, og overgikk dermed OpenAIs o1 – den avanserte resonneringsmodellen (kjent som «chain-of-thought») – samt ChatGPT-4o, gratisversjonen av ChatGPT. Men Deepseek ble marginalt overgått av Anthropics ClaudeAI og OpenAIs o1 mini, som begge fikk en perfekt 6/6. Det er interessant at o1 presterte dårligere enn sin «mindre» motpart, o1 mini.
DeepThink R1 – et AI-verktøy basert på tankekjede laget av DeepSeek – presterte dårligere enn DeepSeek med en poengsum på 3,5.
Dette resultatet viser hvor konkurransedyktig DeepSeeks chatbot allerede er, og slår OpenAIs flaggskipmodeller. Det vil sannsynligvis stimulere videre utvikling for DeepSeek, som nå har et sterkt fundament å bygge videre på. Det kinesiske teknologiselskapet har imidlertid ett alvorlig problem som de andre LLM-ene ikke har: sensur.
Sensurutfordringer
Til tross for sin sterke ytelse og popularitet har DeepSeek møtt kritikk for sine svar på politisk sensitive temaer i Kina. For eksempel blir spørsmål knyttet til Tiananmen-plassen, Taiwan, uiguriske muslimer og demokratiske bevegelser møtt med svaret: «Beklager, det er utenfor mitt nåværende virkeområde.»
Men dette problemet er ikke nødvendigvis unikt for DeepSeek, og potensialet for politisk innflytelse og sensur i LLM-er mer generelt er en økende bekymring. Kunngjøringen av Donald Trumps Stargate LLM-prosjekt på , som involverer OpenAI, Nvidia, Oracle, Microsoft og Arm, vekker også frykt for politisk innflytelse.
I tillegg tyder Metas nylige beslutning om å droppe faktasjekking på Facebook og Instagram på en økende trend mot populisme fremfor sannferdighet.
DeepSeeks ankomst har forårsaket alvorlige forstyrrelser i markedet for lovutdanning. Amerikanske selskaper som OpenAI og Anthropic vil bli tvunget til å innovere produktene sine for å opprettholde relevansen og matche ytelsen og kostnadene.
DeepSeeks suksess utfordrer allerede status quo, og demonstrerer at høytytende LLM-modeller kan utvikles uten milliardbudsjetter. Den fremhever også risikoen ved LLM-sensur, spredning av feilinformasjon og hvorfor uavhengige evalueringer er viktige.
Etter hvert som LLM-er blir dypere forankret i global politikk og næringsliv, vil åpenhet og ansvarlighet være avgjørende for å sikre at fremtiden til LLM-er er trygg, nyttig og pålitelig.
Simon Thorne, førsteamanuensis i databehandling og informasjonssystemer, Cardiff Metropolitan University.
Denne artikkelen er publisert på nytt fra The Conversation under en Creative Commons-lisens. Les den opprinnelige artikkelen .