Richard Reeves ist Geschäftsführer der Association of Online Publishers (AOP), einem britischen Branchenverband, der digitale Verlage vertritt.
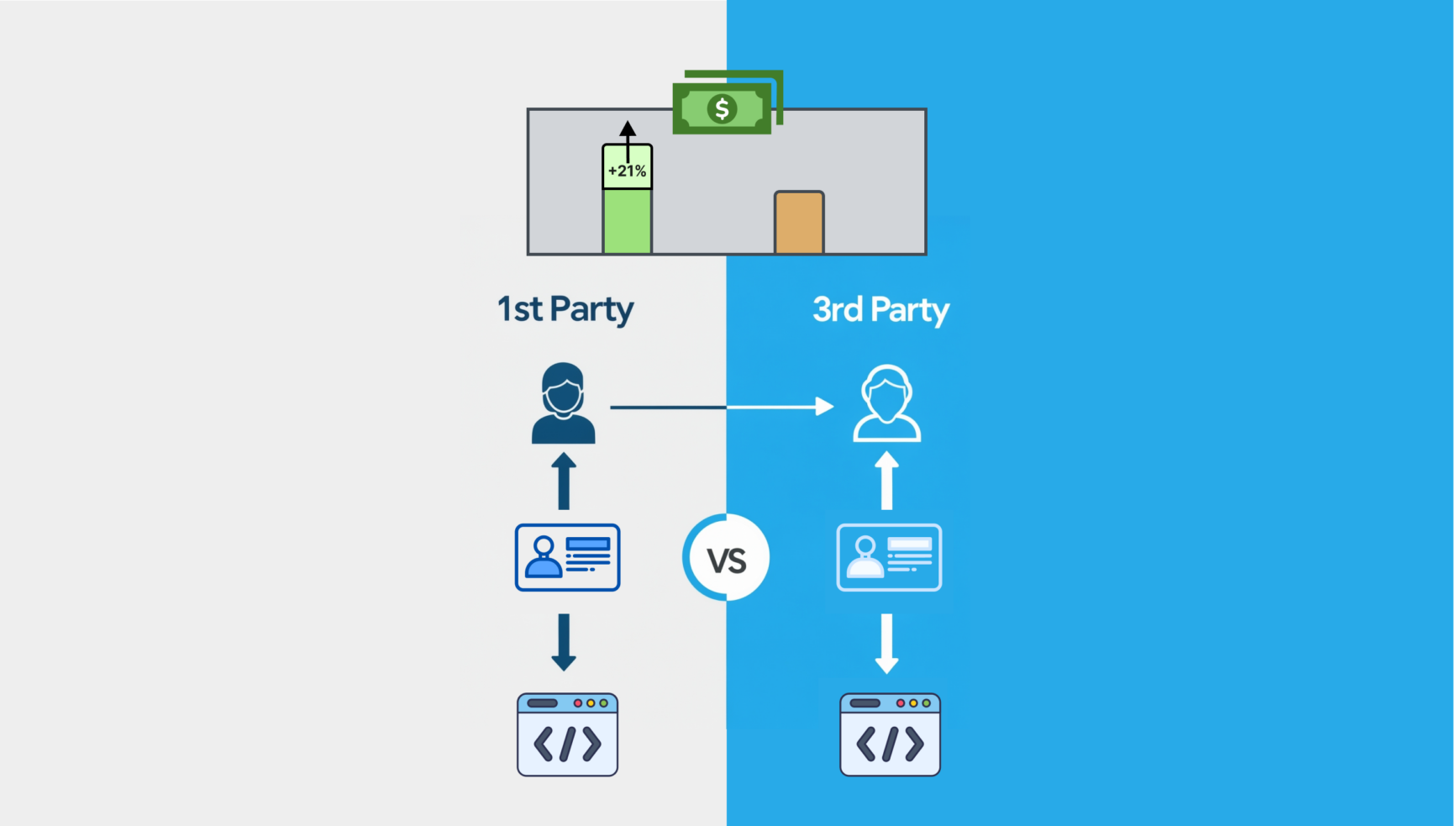
Das Ende des Drittanbieter-Cookies soll Verlagen zugutekommen, da sie dadurch besser in der Lage sind, einen höheren Werbewert aus ihren eigenen Daten zu generieren.
Doch zwischen den Vorbereitungen auf eine „cookielose Zukunft“, dem Kampf mit Facebook und Google um Entschädigungen für das Teilen von Nachrichtenausschnitten und dem Versuch, die neuen Risiken der KI zu erkennen , sind sich einige Verlage möglicherweise eines weiteren potenziellen Problems am Horizont nicht bewusst.
Der britische Verband der Online-Verlage (AOP) veröffentlichte im März einen offenen Brief, in dem er die Verlags- und Werbebranche vor den Gefahren des unautorisierten Daten-Scrapings durch Anbieter von Inhaltsverifizierungsdiensten .
In dem von AOP-Geschäftsführer Richard Reeves unterzeichneten Schreiben wird argumentiert, dass diese Anbieter – entweder durch das Einbetten versteckter Tags in autorisierte In-Header-Wrapper oder durch den Einsatz von Crawlern – „kontextbezogene Zielgruppensegmente zu ihrem eigenen kommerziellen Vorteil“ aufbauen.
„Die missbräuchliche Gewinnung von First-Party-Daten kommt einem Diebstahl des geistigen Eigentums von Verlagen gleich und hat negative Auswirkungen auf Verlage, Werbetreibende und Agenturen“, heißt es darin, bevor weiter ausgeführt wird: „Das Engagement der gesamten Branche, diese Bedenken gemeinsam anzugehen, wird dazu beitragen, radikalere, disruptive Maßnahmen der Verlage zu verzögern – und idealerweise zu verhindern.“
Um die Bedenken der AOP und die potenziellen Gefahren für Verlage besser zu verstehen, State of Digital Publishing (SODP) mit einigen Fragen an Reeves. Im Folgenden finden Sie eine leicht bearbeitete Fassung seiner Antwort.
Inwiefern stellt die Erfassung von Verlagsmetadaten und Artikeltexten eine Bedrohung für die Verlagsbranche dar? Würden bessere Zielgruppenprofile nicht zu einer präziseren kontextbezogenen Zielgruppenansprache und einem fokussierteren Käuferkreis führen?
Digitale Verlage würden als Erste zustimmen, dass eine stärkere Ausrichtung der Werbung auf die von den Zielgruppen konsumierten Inhalte positiv ist. Die meisten sehen den Wandel von verhaltensbasierter zu kontextbasierter Zielgruppenansprache als wichtigen Bestandteil des Aufbaus stärkerer Nutzerbeziehungen und des Vertrauens – und sie erkennen das Potenzial einer gesteigerten Nachfrage, um höhere TKPs zu erzielen.
Das Problem ist, dass sie nicht die Einzigen sind, die diese Vorteile nutzen wollen. Anbietern wird seit Langem der Zugriff auf Inhalte von Verlagen zur Überprüfung der Markensicherheit gestattet, doch viele gehen über diesen begrenzten Zweck hinaus; sie verwenden versteckte Tags, um Daten zu extrahieren und kontextbezogene Zielgruppensegmente für ihren eigenen finanziellen Gewinn zu erstellen.
Diese Praxis verletzt nicht nur das Vertrauen, sondern beraubt die Verlage auch des ausschließlichen Rechts, das ihnen zusteht, ihre eigenen Inhalte zu monetarisieren, wodurch wichtige Werbeeinnahmen und die damit verbundenen wichtigen Einnahmen geschmälert werden.
Wie beeinträchtigt diese Praxis die Fähigkeit von Publishern, das Nutzererlebnis und das Werbeinventar zu verbessern? Können Sie näher erläutern, wie sie den Wettbewerbsvorteil von Publishern bei der Generierung von Werbeeinnahmen schmälert?
Rein theoretisch verschafft der Rückgang von Drittanbieter-Cookies Publishern eine starke Position. Neben dem direkten Zugang zum Publikum verfügen sie über umfangreiche Datenbestände, die sie eigentlich in eine einzigartige Lage versetzen sollten, um datenschutzkonformes, kontextbezogenes Targeting zu unterstützen und höhere Umsätze zu generieren. Die Realität sieht jedoch anders aus: Durch den zunehmenden Einfluss von Vermittlern verlieren ihre Angebote an Wert und generieren weniger Umsatz.
Um zu veranschaulichen, was ich meine, greifen wir auf eine Analogie zurück, die ich oft verwende – einen Apfelgarten mit öffentlichen Wegen.
Obstbauern investieren viel Geld, Zeit und Mühe in den Anbau ihrer Produkte. Während es für einen einzelnen Spaziergänger, der einen Apfel stiehlt, vielleicht nicht weiter schlimm ist, entstehen gravierende Probleme, wenn größere Gruppen mit vollen Körben kommen, diese beladen und zum Markt bringen. Der Erzeuger erzielt dann nicht mehr den erwarteten Gewinn, kann seine Produkte nicht mehr als einzigartig vermarkten und riskiert, von Händlern mit minimaler Gewinnspanne unterboten zu werden.
Verlage investieren enorme Ressourcen in die Produktion qualitativ hochwertiger Inhalte und den Aufbau enger Beziehungen zum Publikum, während einige auch stark in den Ausbau ihrer Fähigkeit investiert haben, kontextbezogene Segmente zu erstellen und lukrative Datenpartnerschaften zu schmieden.
Ähnlich wie bei Obstbauern schwindet auch bei Verlagen die Möglichkeit, von all der harten Arbeit zu profitieren – besonders schwierig in Zeiten wirtschaftlicher Turbulenzen, in denen die Einnahmen bedroht sind. Und das Schlimmste daran: Verlage fühlen sich verpflichtet, Anbietern weiterhin den Zugang zu ermöglichen, da die Bewertung der Markensicherheit für programmatische Einkäufer eine Grundvoraussetzung ist.
Gegen welches Gesetz verstößt dieses Verfahren und wie?
Manche argumentieren, diese Angelegenheit befinde sich in einer rechtlichen Grauzone, doch kurz gesagt handelt es sich um Diebstahl geistigen Eigentums. Daher betrachte ich sie nicht als Grauzone, sondern vielmehr als Beispiel dafür, dass das Recht – das naturgemäß langsam agiert – mit dem rasanten Wandel der Datentechnologie nicht Schritt gehalten hat. Sobald es diesen Rückstand aufgeholt hat, werden sich die Fragen darum drehen, wem welches Vermögen gehört und wer das Recht hat, dieses Vermögen kommerziell zu nutzen.
Während Artikeltexte selbstverständlich Eigentum des Herausgebers sind, gilt dies auch für Daten, die mit den Medieninhalten des Herausgebers und Interaktionen auf der Website oder in der App verknüpft sind. Dazu gehören Seitentitel, Beschreibungen und Keywords sowie Faktoren der Nutzerinteraktion wie Scrollgeschwindigkeit und Bildschirmausrichtung. Kurz gesagt: Das Sammeln und Verwenden dieser Daten ohne vorherige Einwilligung ist Diebstahl gegenüber den Herausgebern.
Rechtlich eindeutig ist die Situation in Fällen, in denen Anbieter gegen ihre Verträge mit Verlagen verstoßen. Viele Verlage beschränken die Nutzung ihrer Datenbestände in ihren Allgemeinen Geschäftsbedingungen ausdrücklich auf nichtkommerzielle Zwecke. Wir raten Verlagen daher dringend, ihre Allgemeinen Geschäftsbedingungen zu aktualisieren, um ihre Organisationen vor unautorisiertem Daten-Scraping zu schützen.
Wie gravierend ist dieses Problem für Käufer? Gibt es Daten, die darauf hindeuten, dass Anbieter von Inhaltsverifizierungen Käufer irreführen?
Die Zusammenarbeit mit skrupellosen Anbietern birgt die Gefahr, den Ruf von Käufern und das Vertrauen der Verbraucher ernsthaft zu schädigen und die Integrität von Kampagnen zu gefährden. Wie in unserem offenen Brief hervorgehoben, mangelt es Marken und Agenturen an Transparenz hinsichtlich der Datenherkunft. Das bedeutet, dass kontextbezogene Anzeigen möglicherweise auf Basis unautorisierter und unzuverlässiger Daten geschaltet werden. Meine Frage an die Agenturen lautet: Können Sie überprüfen, ob die Daten, die Sie für Ihre Kampagnen verwenden, rechtmäßig erhoben wurden?
Das genaue Ausmaß des Problems lässt sich schwer abschätzen – und vor allem handelt es sich, zumindest im Moment, um eine Grundsatzfrage. Nur weil man etwas tun kann, heißt das nicht, dass man es auch tun sollte. In einem mehreren Millionen Dollar und Hunderten von Anbietern haben sich nur sehr wenige gemeldet, um über die Vergütung von Verlagen für die Datennutzung zu sprechen.
Stattdessen preisen mehrere börsennotierte Unternehmen umfangreiches und präzises Data-Mining von Verlagsdaten als eine ihrer größten Stärken an, ohne die Lizenzierung nennenswert zu erwähnen. Infolgedessen tappen viele Käufer im Dunkeln darüber, welche Datenprozesse im Hintergrund ablaufen.
Inwiefern könnten Käufer eine größere Verantwortung für den unsachgemäßen Umgang mit Daten tragen? Ist dies ein rechtliches Problem?
Die meisten Anbieter schweigen zu diesem Thema erwartungsgemäß, doch Andeutungen in den Kommentaren lassen auf mögliche Warnsignale für Käufer schließen. Insbesondere die Behauptung, Anbieter würden Verlagsdaten nur auf Anfrage der Käufer extrahieren, wirkt wie ein Versuch, die Verantwortung abzuwälzen. Auch wenn es noch zu früh ist, um abzuschätzen, ob sich diese Verantwortungsverschiebung auf rechtliche Konsequenzen auswirkt, sollten Käufer dieses Risiko sorgfältig abwägen.
Es ist außerdem wichtig zu betonen, dass sich Probleme mit der Datenqualität rasant verschlimmern können, wenn nicht bald Maßnahmen ergriffen werden. Je mehr Anbieter scheinbar ungestraft agieren können, desto wahrscheinlicher ist ein weiterer Anstieg der Anzahl von Anbietern kontextbezogener Daten, die unautorisierte Crawler einsetzen. Als Vertragspartner haben Käufer die Möglichkeit, eine Eskalation zu verhindern und Einfluss auf die Anbieter zu nehmen, indem sie einen eindeutigen Nachweis über die offizielle Lizenzierung und Genehmigung zur Datenerfassung verlangen. Die Zeit drängt jedoch.
Ist die Mitgliedschaft in der Trustworthy Accountability Group (TAG) an die Nutzung der Markensicherheitszertifizierung der Gruppe gebunden? Gibt es ein System zur Bearbeitung von Verstößen?
Für eine Basis-Mitgliedschaft bei TAG ist keine Zertifizierung erforderlich, für eine Platin-Mitgliedschaft hingegen schon, und jede Organisation, die ein Siegel für Markensicherheitszertifizierung führt, muss sich unbedingt an dessen Richtlinien halten.
Die jüngste Aktualisierung dieser Richtlinien – gültig ab dem 1. Januar 2023 – legt klare Definitionen für die Datennutzung durch Verlage fest und unterscheidet insbesondere zwischen legitimer und unrechtmäßiger Datennutzung. TAG hat bestätigt, dass Organisationen, die gegen diese neue Klausel verstoßen, keine Zertifizierung erhalten.
Zusätzlich zu TAG verlangt der IAB Gold Standard eine Markensicherheitszertifizierung und fügt damit eine weitere Akkreditierungsebene hinzu, die für Anbieter, die Publisher-Daten außerhalb der vertraglich vereinbarten Bedingungen verwenden, nicht zugänglich ist.
Was die Durchsetzung betrifft, so wird die Markensicherheitszertifizierung jährlich vergeben. Natürlich würde ich mir ein schnelleres Fortschrittstempo wünschen, doch bedeutet dies einen erheblichen Zeitdruck für alle bereits zertifizierten Unternehmen, die vollständige Einhaltung der Vorschriften sicherzustellen. Sollten sie bei ihrem nächsten Audit gegen die Richtlinien verstoßen, verlieren sie ihre Zertifizierung. Es wird spannend sein zu beobachten, wie dies in den nächsten zwölf Monaten durchgesetzt wird und wer sein Siegel verliert.
Können Sie näher erläutern, welche Art von „radikalen, disruptiven Maßnahmen der Verlagsbranche“ ergriffen werden könnten, wenn die Bedenken der Verlagsbranche nicht berücksichtigt werden?
Es ist unerlässlich, zunächst zu betonen, dass eine Störung nicht „Plan A“ ist; unsere Haupthoffnung liegt in einer Lösung durch Zusammenarbeit. Andere Wege werden nur dann in Betracht gezogen, wenn die Kooperation scheitert.
Verlage haben das Recht, ihr geistiges Eigentum zu schützen, und manche entscheiden sich dafür, dies durch entschiedene Maßnahmen durchzusetzen. Wie diese Maßnahmen aussehen, ist unterschiedlich, aber wie im offenen Brief erwähnt, gibt es Präzedenzfälle in Fällen gegen Unternehmen, die Daten ohne Einwilligung verwenden, beispielsweise Getty Images gegen Stability AI .
Verlage im gesamten digitalen Bereich sind sich jedoch bewusst, dass dieses Thema bisher nicht ausreichend beachtet wurde. Deshalb konzentrieren wir uns derzeit darauf, das Bewusstsein dafür zu schärfen und eine konstruktive Diskussion anzuregen.
Alle Akteure des Ökosystems müssen die negativen Auswirkungen des Datenmissbrauchs verstehen, und das Zusammenkommen ist der beste Weg, einen für alle Beteiligten vorteilhaften – und fairen – Weg nach vorn zu finden.