Nauunawaan na ng mga publisher na namuhunan sa paglabas sa tuktok ng mga resulta ng paghahanap ng Google ang kahalagahan ng SEO. Gayunpaman, ang isang mahalaga at posibleng hindi napapansing aspeto ng SEO para sa mas malalaking publisher ay ang badyet sa pag-crawl ng Google.
Nakakatulong ang mga crawl budget ng Google na matukoy kung gaano kalawak lumalabas ang mga artikulo sa mga resulta ng paghahanap.
Ang pag-unawa sa mga crawl budget ay isang kritikal na hakbang tungo sa pagtiyak na natutugunan ang mga layunin sa SEO at natitingnan ang nilalaman. Ang pagsuri kung maayos ang teknikal na back end ng isang site ay nangangahulugan na mas malamang na maipakita ng front end ang katayuang iyon.
Sa artikulong ito, ipapaliwanag namin kung ano ang isang crawl budget, ano ang nakakaapekto sa badyet, pag-optimize ng crawl budget, kung paano suriin at subaybayan ang mga crawl budget, at kung bakit napakahalaga ng mga badyet na ito sa kapakanan ng anumang online site.
Ano ang Badyet sa Pag-crawl?
Ang crawl budget ay tumutukoy sa mga resources na inilalaan ng Google sa paghahanap at pag-index ng mga bago at dati nang web page.
Ang crawl bot ng Google — Googlebot — ay nagko-crawl ng mga site upang i-update at palawakin ang database ng mga web page ng higanteng search engine. Gumagamit ito ng mga internal at external na link, XML sitemap, RSS at Atom feed, pati na rin ang mga robots.txt file upang makatulong sa pag-crawl at pag-index ng mga site sa lalong madaling panahon.
Ang ilang pahina ay nagkakaroon ng mas maraming awtoridad sa paglipas ng panahon, habang ang iba ay maaaring tuluyang balewalain dahil sa ilang kadahilanan mula sa nilalaman na may kaugnayan sa mga teknikal na paghihigpit.
Napakahalaga ng pagkaalam kung paano i-maximize ang crawl budget para sa sinumang publisher o website ng organisasyon na naghahanap ng tagumpay sa mga search engine results pages (SERPs).
Mga Limitasyon ng Googlebot
Ang Googlebot ay hindi isang walang katapusang mapagkukunan at hindi kayang tuklasin ng Google ang napakaraming web server. Dahil dito, nag-alok ang kumpanya ng gabay ari ng domain upang mapakinabangan ang kanilang sariling badyet sa pag-crawl.
Ang pag-unawa kung paano isinasagawa ng mga bot ang kanilang mga aktibidad ay napakahalaga.
Kung ang isang crawlbot ay pumunta sa isang site at matukoy na ang pagsusuri at pagkategorya nito ay magiging problema, babagal ito o lilipat sa ibang site depende sa lawak at uri ng mga isyung kinakaharap nito.
Kapag nangyari ito, malinaw na senyales ito na kulang ang site sa pag-optimize ng crawl budget.
Ang pagkaalam na ang Googlebot ay isang limitadong mapagkukunan ay dapat na sapat na dahilan para mag-alala ang sinumang may-ari ng site tungkol sa badyet sa pag-crawl. Gayunpaman, hindi lahat ng site ay nahaharap sa problemang ito sa parehong antas.
Sino ang Dapat Magmalasakit at Bakit?
Bagama't nais ng bawat may-ari ng site na magtagumpay ang kanilang website, tanging ang mga katamtaman at malalaking site na madalas na nag-a-update ng kanilang nilalaman ang talagang kailangang mag-alala tungkol sa mga badyet sa pag-crawl.
Tinutukoy ng Google ang mga medium site bilang iyong mga may mahigit 10,000 natatanging pahina na ina-update araw-araw. Samantala, ang malalaking site ay may mahigit 1 milyong natatanging pahina at ina-update nang hindi bababa sa isang beses sa isang linggo.
ng Google ang ugnayan sa pagitan ng aktibidad ng pag-crawl at ng mas malalaking website, na nagsasabing: “Mas mahalaga ang pagbibigay-priyoridad sa kung ano ang iko-crawl, kailan, at kung gaano karaming resource ang maaaring ilaan ng server na nagho-host ng website para sa pag-crawl para sa mas malalaking website, o sa mga awtomatikong bumubuo ng mga pahina batay sa mga parameter ng URL, halimbawa.” 2
Hindi kailangang masyadong mag-alala tungkol sa crawl budget ng mga site na may limitadong bilang ng pahina. Gayunpaman, dahil maaaring mabilis na lumawak ang ilang publisher, ang pagkakaroon ng pangunahing pag-unawa sa mga istatistika at operasyon ng crawl ay maglalagay sa lahat ng may-ari ng site sa mas mahusay na posisyon upang umani ng mga gantimpala ng mas malaking trapiko sa site sa hinaharap.
Ano ang Nakakaapekto sa Crawl Budget ng Google?
Ang lawak ng pagko-crawl ng Google sa isang website ay natutukoy ng mga limitasyon sa kapasidad ng pag-crawl at demand sa pag-crawl.
Upang maiwasan ang labis na pag-crawl activity sa isang host server, ang limitasyon ng kapasidad ay kinakalkula sa pamamagitan ng pagtatatag ng maximum na bilang ng sabay-sabay at parallel na koneksyon na magagamit ng bot upang i-crawl ang site pati na rin ang oras na pagkaantala sa pagitan ng mga pagbabalik ng data.
Limitasyon sa Kapasidad ng Pag-crawl
Ang sukatang ito, na tinutukoy din bilang limitasyon sa bilis ng pag-crawl, ay pabago-bago at nauugnay sa mga pagbabago sa tatlong salik:
- Kalusugan ng pag-crawl : Kung ang site ay tumugon nang walang error o pagkaantala, at mabuti ang bilis ng site, maaaring tumaas ang limitasyon at vice-versa.
- Rate ng pag-crawl ng GSC : Maaaring gamitin ang Google Search Console (GSC) upang mabawasan ang aktibidad ng pag-crawl , isang function na maaaring maging kapaki-pakinabang sa panahon ng pinahabang pagpapanatili o pag-update ng site. 3 Ang anumang mga pagbabago ay mananatiling aktibo sa loob ng 90 araw . 4
Kung ang limitasyon sa crawl rate ay nakalista bilang "kinakalkula sa pinakamainam," ang pagtataas nito ay hindi isang opsyon at ang pagbaba nito ay maaari lamang mangyari sa pamamagitan ng espesyal na kahilingan. Kung ang isang site ay nao-overcrawl, na humahantong sa availability ng site at/o mga isyu sa pag-load ng pahina, gamitin ang robots.txt upang harangan ang pag-crawl at pag-index. Gayunpaman, ang opsyong ito ay maaaring tumagal ng 24 na oras bago magkabisa.
Bagama't maraming site ang hindi nagpapataw ng mga parusa sa crawl limit, maaari pa rin itong maging isang kapaki-pakinabang na tool.
Pangangailangan sa Pag-crawl
Ang crawl demand ay isang pagpapahayag kung gaano kalaki ang interes ng Google sa pag-index ng isang site. Ito rin ay naiimpluwensyahan ng tatlong salik:
- Napansing imbentaryo : Kung walang gabay mula sa may-ari ng site — na tatalakayin natin mamaya — susubukan ng Google na i-crawl ang bawat URL, kabilang ang mga duplicate, hindi gumaganang link, at mga hindi gaanong mahahalagang pahina. Dito maaaring mapataas ng pagpapaliit ng mga parameter ng paghahanap ng Googlebot ang badyet sa pag-crawl.
- Popularidad : Kung ang isang site ay lubhang popular, ang mga URL nito ay mas madalas na mako-crawl.
- Katatagan : Sa pangkalahatan, nilalayon ng sistemang Googlebot na muling i-crawl ang mga pahina upang makuha ang anumang mga pagbabago. Matutulungan ang prosesong ito sa pamamagitan ng paggamit ng GSC at paghiling ng mga muling pag-crawl, bagama't walang garantiya na agad na aaksyunan ang kahilingan.
Ang aktibidad sa pag-crawl ay, sa esensya, isang produkto ng mahusay na pamamahala ng website.
Mga Alalahanin ng CMS
Vahe Arabian , tagapagtatag ng State of Digital Publishing (SODP) , ang ng content management system (CMS) — tulad ng mga plug-in — ay maaaring makaapekto sa mga crawl budget.
Aniya: “Maraming plug-in ang mabibigat sa database at nagdudulot ng pagtaas ng resource load na magpapabagal sa isang pahina o lilikha ng mga hindi kinakailangang pahina at makakaapekto sa crawlability nito.”
Ang modelo ng kita na hinihimok ng ad ng isang website ay maaaring lumikha ng mga katulad na isyu kung maraming feature ng site ang nangangailangan ng maraming mapagkukunan.
Paano Suriin at Subaybayan ang mga Badyet sa Pag-crawl
May dalawang pangunahing paraan para subaybayan ang mga crawl budget: Google Search Console (GSC) at/o mga server log .
Google Search Console
Bago suriin ang mga crawl rate ng isang site sa Google Search Console (GSC), dapat munang mapatunayan ang pagmamay-ari ng domain.
Ang console ay may tatlong tool para suriin ang mga pahina ng website at kumpirmahin kung aling mga URL ang gumagana at alin ang hindi pa na-index.
- Ang Ulat sa Saklaw ng Indeks7
- Kagamitan sa Pag-inspeksyon ng URL8
- Ulat sa Mga Istatistika ng Pag-crawl9
Sinusuri ng console ang mga kamalian sa domain at magbibigay ng mga mungkahi kung paano lutasin ang iba't ibang mga error sa pag-crawl.
Pinagsama-sama ng GSC ang mga error sa katayuan sa ilang kategorya sa Ulat ng Sakop ng Indeks nito, kabilang ang:
- Error sa server [5xx]
- Error sa pag-redirect
- Hinarangan ng robots.txt ang isinumiteng URL
- Isinumiteng URL na may markang 'noindex'
- Mukhang soft 404 ang isinumiteng URL
- Ang isinumiteng URL ay nagbabalik ng hindi awtorisadong kahilingan (401)
- Hindi natagpuan ang isinumiteng URL (404)
- Ang isinumiteng URL ay nagbalik ng 403:
- Na-block ang isinumiteng URL dahil sa ibang isyu sa 4xx
Ipinapakita ng ulat kung ilang pahina ang naapektuhan ng bawat error kasama ang status ng pagpapatunay.
Ang URL Inspection Tool ay nagbibigay ng impormasyon sa pag-index sa anumang partikular na pahina, habang ang Crawl Stats Report ay maaaring gamitin upang malaman kung gaano kadalas kino-crawl ng Google ang isang site, ang kakayahang tumugon ng server ng site at anumang kaugnay na mga isyu sa availability.
Mayroong nakapirming pamamaraan sa pagtukoy at pagwawasto ng bawat error, mula sa pagkilala na ang isang site server ay maaaring down o hindi available sa oras ng pag-crawl hanggang sa paggamit ng 301 redirection upang mag-redirect sa ibang pahina, o pag-alis ng mga pahina mula sa sitemap.
Kung malaki ang ipinagbago ng nilalaman ng pahina, maaaring gamitin ang buton na “request indexing” ng URL Inspection Tool upang simulan ang pag-crawl ng pahina.
Bagama't maaaring hindi kinakailangang "ayusin" ang bawat indibidwal na error sa pahina, ang pag-minimize ng mga problemang nakakaapekto sa mga crawl bot ay tiyak na isang pinakamahusay na kasanayan.
Gamitin ang mga Log ng Server
Bilang alternatibo sa Google Search Console (GSC), maaaring siyasatin ang crawl health ng isang site sa pamamagitan ng mga server log na hindi lamang nagtatala ng bawat pagbisita sa site kundi pati na rin sa bawat pagbisita sa Googlebot.
Para sa mga hindi pa nakakaalam, awtomatikong lumilikha at nag-iimbak ang mga server ng log entry tuwing hihiling ang Googlebot o isang tao na maihatid ang isang pahina. Ang mga log entry na ito ay kinokolekta sa isang log file.
Kapag na-access na ang isang log file, kailangan itong suriin. Gayunpaman, dahil sa lawak ng mga entry sa log, hindi dapat basta-basta gawin ang gawaing ito. Depende sa laki ng site, ang isang log file ay madaling maglaman ng daan-daang milyon o kahit bilyun-bilyong entry.
Kung magdesisyong suriin ang log file, ang data ay kailangang i-export sa isang spreadsheet o sa isang software na pagmamay-ari nito, upang mas mapadali ang proseso ng pagsusuri.
Ipapakita ng pagsusuri ng mga talaang ito ang uri ng mga error na kinaharap ng isang bot, kung aling mga pahina ang pinakamadalas na na-access at kung gaano kadalas na-crawl ang isang site.
9 na Paraan para I-optimize ang Badyet sa Pag-crawl
Ang pag-optimize ay kinabibilangan ng pagsusuri at pagsubaybay sa mga istatistika ng kalusugan ng site, gaya ng nabanggit sa itaas, pagkatapos ay direktang pagtugon sa mga lugar na may problema.
Sa ibaba, inilatag namin ang aming crawl budget optimization toolkit, na ginagamit namin upang matugunan ang mga isyu sa crawlability kapag lumitaw ang mga ito.
1. Pagsama-samahin ang Duplikadong Nilalaman
Maaaring lumitaw ang mga isyu sa pag-crawl kapag ang isang pahina ay maaaring ma-access mula sa iba't ibang URL o naglalaman ng nilalaman na kinokopya sa ibang lugar sa site. Titingnan ng bot ang mga halimbawang ito bilang mga duplikado at pipiliin lamang ang isa bilang canonical na bersyon.
Ang mga natitirang URL ay ituturing na hindi gaanong mahalaga at madalang na i-crawl o hindi na talaga. 10 Ayos lang ito kung pipiliin ng Google ang ninanais na canonical page, ngunit isang seryosong problema kung hindi nito gagawin.
Gayunpaman, maaaring may mga wastong dahilan para magkaroon ng mga duplicate na pahina, tulad ng pagnanais na suportahan ang maraming uri ng device, paganahin ang content syndication o gumamit ng mga dynamic na URL para sa mga parameter ng paghahanap o mga session ID.
Mga rekomendasyon ng SODP :
- Putulin ang nilalaman ng website kung saan posible
- Gumamit ng 301s para pagsama-samahin ang mga URL at pagsamahin ang nilalaman
- Burahin ang nilalamang hindi maganda ang performance
- Ang paggamit ng 301s kasunod ng isang pagbabago sa istruktura ng website ay magpapadala sa mga user, bot, at iba pang crawler kung saan sila kailangang pumunta.
- Gumamit ng noindex para sa manipis na mga pahina, pagination (para sa mga lumang archive) at para sa pag-cannibalize ng nilalaman.
- Sa mga pagkakataong humahantong sa overcrawl ang duplicate na nilalaman, isaayos ang setting ng crawl rate sa Google Search Console (GSC).
2. Gamitin ang Robots.txt File
Nakakatulong ang file na ito na maiwasan ang mga bot sa pag-trawl sa isang buong site. Ang paggamit ng file ay nagbibigay-daan para sa pagbubukod ng mga indibidwal na pahina o seksyon ng pahina.
Ang opsyong ito ay nagbibigay sa publisher ng kontrol sa kung ano ang naka-index, pinapanatiling pribado ang ilang partikular na nilalaman habang pinapabuti rin kung paano ginagastos ang crawl budget.
Mga rekomendasyon ng SODP :
- Ayusin ang kagustuhan ng mga parameter upang unahin ang mga parameter na kailangang harangan sa pag-crawl.
- Tukuyin ang mga robot, direktiba, at parameter na nagdudulot ng karagdagang pag-crawl gamit ang mga log file.
- Harangan ang mga karaniwang path na karaniwang mayroon ang CMS tulad ng 404, admin, mga login page, atbp.
- Iwasan ang paggamit ng crawl-delay directive upang mabawasan ang trapiko ng bot para sa performance ng server. Makakaapekto lamang ito sa bagong content indexation.
3. I-segment ang mga XML Sitemap upang Mas Mabilis na Makuha ang Nilalaman
Dumarating ang isang crawl bot sa isang site na may pangkalahatang alokasyon kung ilang pahina ang iko-crawl nito. Epektibong idinidirekta ng XML sitemap ang bot upang basahin ang mga napiling URL, na tinitiyak ang epektibong paggamit ng badyet na iyon.
Tandaan na ang performance ng ranggo ng isang pahina ay nakadepende sa ilang salik kabilang ang kalidad ng nilalaman at mga internal/external na link. Isaalang-alang ang pagsasama lamang ng mga top-tier na pahina sa mapa. Maaaring italaga ang mga larawan sa sarili nilang XML sitemap.
Mga rekomendasyon ng SODP :
- Gamitin ang XML sitemap mula sa robots.txt file.
- Gumawa ng maraming sitemap para sa isang napakalaking site. Huwag magdagdag ng higit sa 50,000 URL sa iisang XML sitemap.
- Panatilihin itong malinis at isama lamang ang mga pahinang maaaring i-index.
- Panatilihing napapanahon ang XML sitemap.
- Panatilihing mas mababa sa 50MB ang laki ng file.
4. Suriin ang Istratehiya sa Panloob na Pag-uugnay
Sinusubaybayan ng Google ang network ng mga link sa loob ng isang site at anumang mga pahina na may maraming link ay itinuturing na may mataas na halaga at sulit na gastusin sa badyet ng pag-crawl.
Gayunpaman, mahalagang tandaan na habang ang limitadong bilang ng mga internal link ay maaaring makaapekto sa badyet ng pag-crawl, maaari rin itong makaapekto sa buong site gamit ang mga link.
Ang mga pahinang walang internal link ay hindi nakatatanggap ng link equity mula sa iba pang bahagi ng website, na naghihikayat sa Google na ituring ang mga ito na mas mababa ang halaga.
Kasabay nito, ang mga pahinang may mataas na halaga na naglalaman ng maraming internal link ay nauuwi sa pantay na pagbabahagi ng kanilang link equity sa pagitan ng iba pang mga pahina anuman ang kanilang strategic value. Dahil dito, iwasan ang pag-link sa mga pahinang nag-aalok ng kaunting halaga sa mga mambabasa.
Ang isang diskarte sa internal linking ay nangangailangan ng mahusay na paghawak upang matiyak na ang mga pahinang may mataas na halaga ay makakatanggap ng sapat na mga link, habang ang mga pahinang may mababang halaga ay hindi nakakasira sa equity ng link.
5. I-upgrade ang Hosting kung ang Kasabay na Trapiko ay Isang Bottleneck
Kung ang isang website ay tumatakbo sa isang shared hosting platform, ang crawl budget ay ibabahagi sa iba pang mga website na tumatakbo sa nasabing platform. Maaaring makita ng isang malaking kumpanya na ang independent hosting ay isang mahalagang alternatibo.
Iba pang mga konsiderasyon kapag ina-upgrade ang iyong hosting o kahit bago mag-upgrade upang malutas ang labis na trapiko sa bot na maaaring makaapekto sa mga load ng server:
- Iproseso ang mga imahe gamit ang isang hiwalay na CDN na na-optimize din upang mag-host ng mga format ng imahe para sa susunod na henerasyon tulad ng webp
- Isaalang-alang ang pagho-host ng CPU at disk space batay sa function at mga kinakailangan ng iyong website
- Subaybayan ang aktibidad gamit ang mga solusyon tulad ng New Relic upang masubaybayan ang labis na paggamit ng mga plugin at bot
6. Balansehin ang Paggamit ng Javascript
Kapag napunta ang Googlebot sa isang web page, nire-render nito ang lahat ng asset sa nasabing page, kabilang ang Javascript. Bagama't medyo simple lang ang pag-crawl sa HTML, kailangang iproseso ng Googlebot ang Javascript nang ilang beses upang ma-render ito at maunawaan ang nilalaman nito.
Mabilis nitong mauubos ang crawl budget ng Google para sa isang website. Ang solusyon ay ang pagpapatupad ng Javascript rendering sa server side.
Sa pamamagitan ng pag-iwas sa pagpapadala ng mga Javascript asset sa client para sa rendering , hindi ginagamit ng mga crawl bot ang kanilang mga resources at mas mahusay na gumagana. 11
Mga rekomendasyon ng SODP :
- Gumamit ng browser-level-lazy loading sa halip na maging JS-based
- Tukuyin kung ang mga elemento
- Gumamit ng server side tagging para sa analytics at third-party tagging, self-hosted man o gumagamit ng mga solusyon tulad ng https://stape.io/ . 12
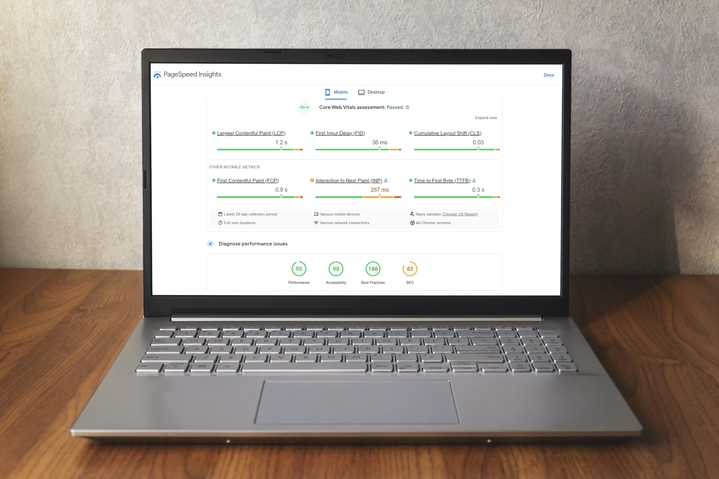
7. I-update ang Core Web Vitals (CWV) para Mapabuti ang Karanasan sa Pahina
Ginagamit ng Core Web Vitals (CWV) ng Google Search Console (GSC) ang tinatawag ng higanteng search engine na " real world usage data " upang ipakita ang performance ng pahina. 13
Pinagsasama-sama ng ulat ng CWV ang pagganap ng URL sa ilalim ng tatlong kategorya:
- Uri ng Metriko (LCP, FID at CLS)
- Katayuan
- Mga pangkat ng URL
Metriko
Ang ulat ng CWV ay batay sa pinakamalaking sukatan ng contentful paint (LCP), 14 first input delay (FID) 15 at cumulative layout shift (CLS) 16 .
Ang LCP ay nauugnay sa dami ng oras na kinakailangan upang maipakita ang pinakamalaking elemento ng nilalaman na nakikita sa nakikitang bahagi ng web page.
Ang FID ay tumutukoy sa oras na kinakailangan para tumugon ang isang pahina sa interaksyon ng isang user.
Ang CLS ay isang sukatan kung gaano nagbabago ang layout ng pahina sa panahon ng sesyon ng gumagamit, kung saan ang mas mataas na marka ay kumakatawan sa mas masamang karanasan ng gumagamit.
Katayuan
Kasunod ng isang pagtatasa ng pahina, ang bawat sukatan ay binibigyan ng isa sa tatlong ranggo ng katayuan:
- Mabuti
- Kailangan ng pagpapabuti
- Mahina
Mga Grupo ng URL
Maaari ring magtalaga ang ulat ng mga isyu sa isang grupo ng magkakatulad na URL, sa pag-aakalang ang mga isyu sa pagganap na nakakaapekto sa magkakatulad na pahina ay maaaring maiugnay sa isang ibinahaging problema.
CWV at Pag-crawl
Gaya ng nabanggit kanina, habang tumatagal ang ginagastos ng Googlebot sa isang pahina, mas nasasayang ang badyet nito sa pag-crawl. Dahil dito, magagamit ng mga publisher ang mga ulat ng CWV upang ma-optimize ang kahusayan ng pahina at mabawasan ang oras ng pag-crawl.
ng SODP , na nakatuon sa WordPress:
| Mga pahiwatig sa pagpapabuti ng bilis | Ipatupad sa pamamagitan ng | Patunayan sa |
| I-convert ang mga imahe sa format na WebP | Kung naka-enable ang CDN, i-convert ito sa pamamagitan ng CDN side o i-install ang EWWW plugin | https://www.cdnplanet.com/tools/cdnfinder/ |
| Ipatupad ang SRCSET at Suriin sa https://pagespeed.web.dev/ kung nalutas na ang isyu sa Wastong laki ng mga imahe | Ipatupad sa pamamagitan ng manu-manong pagdaragdag ng code | Suriin ang browser code kung ang lahat ng mga imahe ay may SRCSET code |
| Paganahin ang pag-cache ng browser | Rocket ng WP | https://www.giftofspeed.com/cache-checker/ |
| Mga larawan ng tamad na pag-load | Rocket ng WP | Tingnan sa browser console kung naidagdag na ang lazyload code sa larawan. Maliban sa itinatampok na larawan. |
| Ipagpaliban ang mga panlabas na script: Tanging ang mga script sa<body> maaaring ipagpaliban | WP rocket o Isang mas mabilis na website! (kilala rin bilang defer.js) plugin | Pagkatapos idagdag ang defer tag, tingnan ang https://pagespeed.web.dev/ kung nalutas na ang isyu sa Reduce unused JavaScript. |
| Tukuyin at tanggalin ang mga hindi nagamit na JS at CSS file | Manu-manong | |
| Paganahin ang Gzip compression | Server side, makipag-ugnayan sa hosting provider | https://www.giftofspeed.com/gzip-test/ |
| Paliitin ang JS at CSS | Rocket ng WP | https://pagespeed.web.dev/ |
| Mag-load ng mga font nang lokal o Mag-preload ng mga web font | OMG font plugin o i-upload ang mga font file sa server at idagdag ito sa pamamagitan ng code sa header | |
| Paganahin ang CDN | Cloudflare (anumang iba pang serbisyo ng CDN) at i-configure ito para sa site |
8. Gumamit ng Third-Party Crawler
Ang isang third-party crawler tulad ng Semrush, Sitechecker.pro o Screaming Frog ay nagbibigay-daan sa mga web developer na i-audit ang lahat ng URL sa isang site at tukuyin ang mga potensyal na isyu.
Maaaring gamitin ang mga crawler upang matukoy ang:
- Mga sirang link
- Duplikadong nilalaman
- Mga nawawalang pamagat ng pahina
Nag-aalok ang mga programang ito ng ulat ng mga istatistika ng pag-crawl upang makatulong na i-highlight ang mga problemang maaaring hindi matukoy ng mga tool ng Google mismo.
Ang pagpapabuti ng nakabalangkas na datos at pagbabawas sa mga isyu sa kalinisan ay magpapadali sa trabaho ng Googlebot sa pag-crawl at pag-index ng isang site.
Mga rekomendasyon ng SODP :
- Gumamit ng mga SQL query upang magsagawa ng mga batch update sa mga error sa halip na manu-manong ayusin ang bawat isyu.
- Gayahin ang Googlebot, sa pamamagitan ng mga setting ng search crawl, upang maiwasan ang pagharang mula sa mga hosting provider at upang maayos na matukoy at maayos ang lahat ng teknikal na isyu.
- I-debug ang mga nawawalang pahina mula sa isang crawl gamit ang mahusay na gabay na ito mula sa Screaming Frog . 17
9. Mga Parameter ng URL
Ang mga parameter ng URL — ang seksyon ng web address na kasunod ng "?" — ay ginagamit sa isang pahina para sa iba't ibang dahilan, kabilang ang pag-filter, pagination, at paghahanap.
Bagama't mapapahusay nito ang karanasan ng gumagamit, maaari rin itong magdulot ng mga isyu sa pag-crawl kapag ang parehong base URL at ang isa na may mga parameter ay nagbabalik ng parehong nilalaman. Ang isang halimbawa nito ay ang "http://mysite.com" at "http://mysite.com?id=3" na nagbabalik ng eksaktong parehong pahina.
Ang mga parameter ay nagpapahintulot sa isang site na magkaroon ng halos walang limitasyong bilang ng mga link — tulad ng kung kailan maaaring pumili ang isang user ng mga araw, buwan at taon sa isang kalendaryo. Kung papayagan ang bot na i-crawl ang mga pahinang ito, ang badyet sa pag-crawl ay mauubos nang hindi kinakailangan.
Mga rekomendasyon ng SODP :
- Gumamit ng mga panuntunan ng robots.txt. Halimbawa, tukuyin ang mga pagkakasunud-sunod ng parameter sa isang allow directive.
- Gamitin ang hreflang upang tukuyin ang mga baryasyon ng wika ng nilalaman.
Pagbubuod ng mga Mito at Katotohanan ng Googlebot
Mayroong ilang mga maling akala tungkol sa kapangyarihan at saklaw ng Googlebot.
Narito ang lima na aming sinuri:
1. Paminsan-minsang gumagapang ang Googlebot sa isang Site
Ang Googlebot ay talagang madalas na nagko-crawl sa mga site at, sa ilang mga sitwasyon, araw-araw pa nga. Gayunpaman, ang dalas ay natutukoy ng nakikitang kalidad, kabagohan, kaugnayan, at kasikatan ng site.
Gaya ng nabanggit sa itaas, maaaring gamitin ang Google Search Console (GSC) upang humiling ng crawl.
2. Gumagawa ng mga Desisyon ang Googlebot Tungkol sa Pagraranggo ng Site
Bagama't dati itong tama, itinuturing na ito ngayon ng Google bilang isang hiwalay na bahagi ng proseso ng crawl, index at rank, ayon kay Martin Splitt , WebMaster Trends Analyst sa Google. 18
Gayunpaman, mahalagang tandaan din na ang nilalaman, sitemap, bilang ng mga pahina, link, URL, atbp. ng isang site ay pawang mga salik sa pagtukoy ng ranggo nito.
Sa esensya, ang matalinong mga pagpipilian sa SEO ng mga publisher ay maaaring humantong sa matibay na posisyon sa loob ng mga SERP.
3. Sinasalakay ng Googlebot ang mga Pribadong Seksyon ng isang Site
Walang konsepto ang bot ng "pribadong nilalaman" at nakatalaga lamang sa pag-index ng mga site maliban na lang kung inutusan ng may-ari ng site na gawin ang iba.
Maaaring manatiling hindi naka-index ang ilang partikular na web page hangga't isinasagawa ang mga kinakailangang hakbang sa loob ng GSC upang paghigpitan ang pag-access.
4. Ang Aktibidad ng Googlebot ay Maaaring Maglagay ng Stress sa Kakayahang Magtrabaho ng Site
May mga limitasyon ang proseso ng Googlebot dahil sa mga limitasyon ng mapagkukunan ng Google at dahil ayaw ng Google na makagambala sa isang site.
Sabi ni Splitt: “Kunti lang ang ginagawa namin, tapos unti-unti rin namin itong pinapataas. At kapag nakakakita na kami ng mga error, unti-unti rin naming binababa.”15
Maaaring maantala ng GSC ang mga pag-crawl at dahil ang ilang mga site ay maaaring may ilang daang libong pahina, hinahati-hati ng Googlebot ang pag-crawl nito sa ilang mga pagbisita.
5. Ang Googlebot ang Tanging Bot na Dapat Ipag-alala
Bagama't ang Googlebot ang nangungunang crawler sa mundo, hindi lahat ng bot ay pagmamay-ari ng Google. Ang ibang mga search engine ay nagko-crawl sa web, habang ang mga bot na nakatuon sa analytics pati na rin sa data at kaligtasan ng brand ay aktibo rin.
Kasabay nito, ang mga masasamang aktor ay nagdidisenyo ng mas sopistikadong software upang makisali sa pandaraya sa ad , magnakaw ng nilalaman, mag-post ng spam at marami pang iba. 19
Mga Pangwakas na Kaisipan
Mahalagang tandaan na ang pag-optimize ng crawl budget at matagumpay na karanasan ng user ay maaaring pamahalaan nang hindi isinasakripisyo ang isa't isa
Ang pagsuri sa kalusugan ng crawl budget ng isang site ay dapat na maging bahagi ng lahat ng programa sa pagpapanatili ng mga may-ari ng website, kung saan ang dalas ng mga pagsusuring ito ay depende sa laki at katangian ng mismong website.
ang teknikal na pagsasaayos — tulad ng pag-aayos ng mga sirang link, mga pahinang hindi gumagana , mga dobleng nilalaman, mga URL na hindi maganda ang pagkakasulat, at mga luma at maraming error na sitemap.
- Pamamahala ng Badyet sa Pag-crawl Para sa Malalaking Site | Google Search Central | Dokumentasyon
- Ano ang Kahulugan ng Crawl Budget para sa Googlebot | Google Search Central Blog
- Bawasan ang Rate ng Pag-crawl ng Googlebot | Google Search Central | Dokumentasyon
- Baguhin ang bilis ng pag-crawl ng Googlebot – Tulong sa Search Console
- Pag-optimize ng Badyet sa Pag-crawl para sa mga Publisher | State of Digital Publishing
- Google Search Console
- Ulat sa Sakop ng Index – Tulong sa Search Console
- Tool sa Pag-inspeksyon ng URL – Tulong sa Search Console
- Ulat sa Mga Istatistika ng Pag-crawl – Tulong sa Search Console
- Pagsamahin ang mga Duplicate na URL gamit ang mga Canonical | Google Search Central | Dokumentasyon
- Pag-render sa Web | Mga Developer ng Google
- Stape.io
- Ulat sa Core Web Vitals – Tulong sa Search Console
- Pinakamalaking Pinturang May Nilalaman (LCP)
- Unang Pagkaantala ng Pag-input (FID)
- Pinagsama-samang Pagbabago ng Layout (CLS)
- Paano I-debug ang mga Nawawalang Pahina sa Isang Crawl – Screaming Frog
- Googlebot: Pagbuwag sa mga Mito ng SEO
- Pandaraya sa Ad: Lahat ng Kailangan Mong Malaman | Publift