Taktikker for utgivervekst i valgkampen | WEBINAR


2.6.1 Hva er et gjennomgangsbudsjett?
Gjennomsøkingsbudsjettet er antall sider på nettstedet ditt en webcrawler vil gjennomsøke innenfor en gitt tidsramme.
Hver gang du trykker på publiser-knappen, må Google gjennomsøke og indeksere innholdet for at det skal begynne å vises i søkeresultatene. Gitt omfanget og volumet av innhold på internett, blir gjennomsøking en verdifull ressurs som må budsjetteres og rasjoneres for mest mulig effektiv bruk.
Enkelt sagt er det vanskelig for Google å gjennomsøke og indeksere hver eneste side på internett hver dag. Derfor gjennomsøker Google hvert nettsted i henhold til det tildelte budsjettet.
Gjennomsøkingsbudsjettet tildeles nettsteder basert på to faktorer – gjennomsøkingsgrense og gjennomsøkingsetterspørsel.
Dette er et nettsteds kapasitet og/eller vilje til å bli gjennomsøkt.
Ikke alle nettsteder er bygget for å bli gjennomsøkt hver dag. Gjennomsøking innebærer at Googlebot sender forespørsler til nettstedets server som, hvis de gjøres for ofte, kan belaste serverens kapasitet.
Det er heller ikke alle utgivere som ønsker at nettstedet deres skal gjennomsøkes kontinuerlig.
Gjennomsøkingsetterspørsel er et mål på hvor ofte en bestemt side ønsker å bli gjennomsøkt (på nytt). Populære sider eller sider som oppdateres ofte må gjennomsøkes og gjennomsøkes på nytt oftere.
Hvis Google ikke kan gjennomsøke og indeksere innholdet ditt, vil det rett og slett ikke vises i søkeresultatene.
Når det er sagt, er gjennomsøkingsbudsjetter vanligvis bare et problem for mellomstore til store utgivere som har mer enn 10 000 sider på nettstedet sitt. Mindre utgivere burde ikke trenge å bekymre seg for mye om gjennomsøkingsbudsjetter.
Utgivere med 10 000 eller flere sider på nettstedet sitt vil imidlertid unngå at Googlebot gjennomsøker sider som ikke var viktige. Hvis du bruker opp gjennomsøkingsbudsjettet ditt på irrelevant eller mindre viktig innhold, betyr det at sider med høyere verdi kanskje ikke blir gjennomsøkt.
Dessuten vil nyhetsutgivere være forsiktige med bortkastede budsjetter for gjennomsøking, ettersom gjennomsøking er en av de tre måtene Google Nyheter oppdager nytt innhold på en rettidig måte. De to andre er ved hjelp av nettstedskart og Google Publisher Center, som vi har utforsket nærmere i modulene for Google Nyheter-nettstedskart og Google Publisher Center.
Optimalisering av frekvensen og hastigheten som Googlebot gjennomsøker nettstedet ditt med innebærer å overvåke en rekke variabler. Vi begynner med å liste opp de viktigste faktorene som er involvert i optimalisering av gjennomsøkingsbudsjett og -frekvens.
De to mest nyttige taktikkene for å overvåke hvordan innholdet ditt blir gjennomsøkt, er å analysere loggfiler og Google Search Consoles (GSC) statistikkrapport for gjennomsøking.
En loggfil er et tekstdokument som registrerer all aktivitet på nettstedets server. Dette inkluderer alle data om gjennomsøkingsforespørsler, sideforespørsler, bildeforespørsler, forespørsler om javascript-filer og andre ressurser som trengs for å kjøre nettstedet ditt.
For teknisk SEO bidrar loggfilanalyse til å finne mye nyttig informasjon om URL-gjennomsøking, inkludert, men ikke begrenset til:
Slik gjør du dette
Loggfilanalyse er en oppgave som krever en viss grad av teknisk kjennskap til et nettsteds backend. Derfor anbefaler vi å bruke programvare for loggfilanalyse. Det finnes flere gratis og betalte verktøy for logganalyse, som Graylog , Loggly , Elastic Stack , Screaming Frog Log Analyzer og Nagios, for å nevne noen.
Hvis du er en erfaren utvikler eller systemadministrator, kan du også utføre en loggfilanalyse manuelt.
For å gjøre dette, følg disse trinnene:
Når du har lastet ned loggfilen, kan du endre filtypen til .csv og åpne den ved hjelp av Microsoft Excel eller Google Sheets. Som sagt krever imidlertid denne tilnærmingen et visst nivå av ekspertise for å forstå loggfilen.
Du kan også få tilgang til loggfilen ved hjelp av en FTP-klient ved å angi banen til loggfilen. En typisk loggfilsti ser omtrent slik ut:
Servernavn (for eksempel Apache) /var/log/access.log
Det er imidlertid mye mer praktisk å bruke et logganalyseverktøy i stedet. Når du har lastet opp loggfilen til verktøyet, kan du sortere dataene ved hjelp av flere filtre. Du vil for eksempel kunne se hvilke nettadresser som har blitt besøkt oftest av Googlebot.
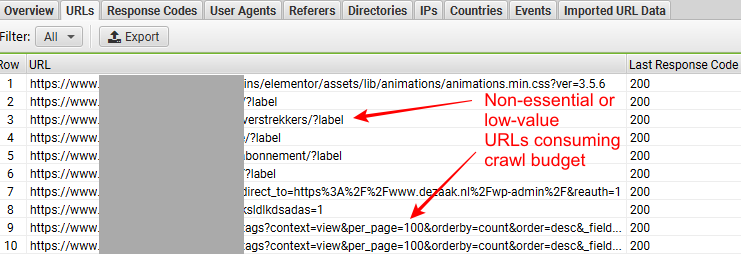
Du vil også kunne se om Googlebot har fått tilgang til unødvendige eller lavverdifulle URL-er, som fasetterte navigasjons-URL-er, dupliserte URL-er osv. Det er viktig å identifisere disse, ettersom de sløser bort gjennomsøkingsbudsjettet ditt.
Se på skjermbildet nedenfor, hentet fra Screaming Frogs SEO Log File Analyzer, for å se hva vi mener.
GSC gir nettstedseiere omfattende data og innsikt i hvordan Google gjennomsøker innholdet deres. Dette inkluderer detaljerte rapporter om:
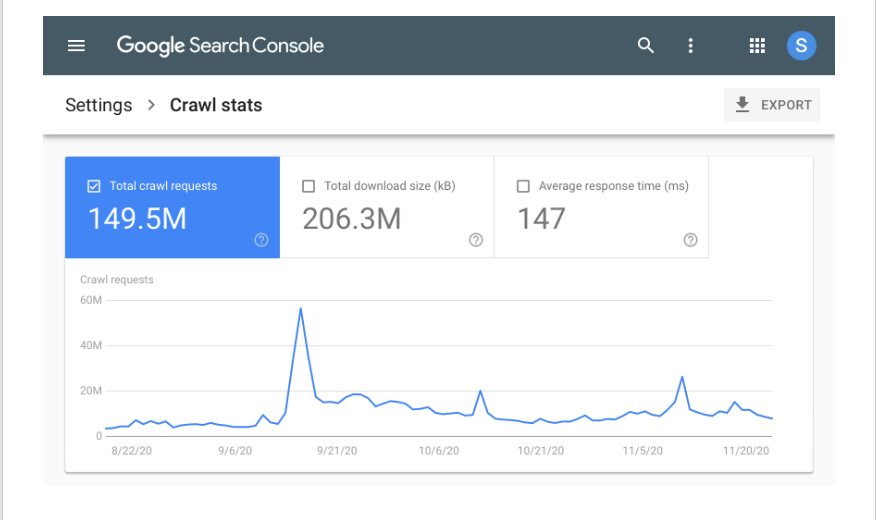
GSC tilbyr også lettforståelige grafer og diagrammer for å gi nettstedseiere enda mer informasjon. Skjermbildet nedenfor viser hvordan en typisk rapport om gjennomsøkingsstatistikk på GSC ser ut.
GSC gir deg også beskjed om det er problemer med gjennomsøkingen. Den sjekker etter flere feil og tildeler hver av dem en kode. De vanligste feilene GSC sjekker etter inkluderer:
GSC-rapporten viser også hvor mange sider som har blitt påvirket av hver feil, i tillegg til valideringsstatusen.
Slik gjør du dette
Slik får du tilgang til GSC-rapporten for gjennomsøkingsstatistikk for nettstedet eller nettsiden din:
Disse inkluderer:
Vi vet nå at gjennomsøkingsbudsjettet er en verdifull ressurs hvis bruk må optimaliseres for best mulig resultat. Her er noen teknikker for å gjøre dette:
Duplikatinnhold kan ende opp med å bli gjennomsøkt separat, noe som fører til sløsing med gjennomsøkingsbudsjettet. For å unngå at dette skjer, bør du enten slå sammen duplikatsider på nettstedet ditt til én, eller slette duplikatsider.
Robots.txt er en fil som tjener en rekke formål, hvorav ett er å fortelle Googlebot at den ikke skal gjennomsøke bestemte sider eller deler av sider. Dette er en viktig strategi som kan brukes for å forhindre at Googlebot gjennomsøker innhold av lav verdi eller innhold som ikke trenger gjennomsøking.
Her er noen gode fremgangsmåter når du bruker robots.txt for å optimalisere gjennomsøkingsbudsjettet:
Slik gjør du dette
Å opprette og kjøre en robots.txt-fil for å begrense Googlebot-tilgang krever litt kodekunnskap. Her er trinnene som er involvert:
En typisk robots.txt-fil vil ha følgende elementer:
Nedenfor ser du hvordan en enkel robots.txt-fil ser ut.
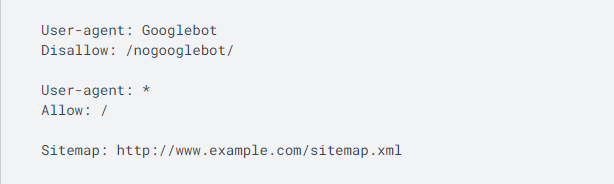
Denne koden betyr at en brukeragent – Googlebot i dette tilfellet – ikke har lov til å gjennomsøke noen URL-er som begynner med « http://www.example.com/nogooglebot/ ».
Vi anbefaler at du søker eksperthjelp hvis du ikke føler deg komfortabel med å opprette og laste opp robots.txt-filer selv.
En gjennomsøkingsrobot ankommer et nettsted med en generell tildeling av hvor mange sider den skal gjennomsøke. XML-nettstedskartet dirigerer effektivt roboten til å lese utvalgte URL-er, noe som sikrer effektiv bruk av budsjettet.
Merk at en sides rangering avhenger av flere faktorer, inkludert innholdskvalitet og interne/eksterne lenker. Vurder å bare inkludere toppsider i kartet. Bilder kan tildeles sitt eget XML-nettstedskart.
Følg disse anbefalingene for å sikre optimal implementering av XML-sitemap:
For en mer detaljert oversikt over nettstedskart, se vår dedikerte modul om dette emnet .
Interne lenker utfører tre viktige funksjoner:
For effektiv gjennomgang er det derfor viktig å implementere en effektiv strategi for intern lenking. For mer informasjon om intern lenking, se vår detaljerte kursmodul her.
Hvis et nettsted kjører på en delt hostingplattform, vil gjennomsøkingsbudsjettet deles med andre nettsteder som kjører på nevnte plattform. En stor utgiver kan finne uavhengig hosting som et verdifullt alternativ.
Før du oppgraderer hosting for å løse overbelastning av bottrafikk, er det noen faktorer verdt å vurdere som kan påvirke serverbelastningen på annen måte.
Hvis du vil vite mer om fordelene med CDN-er, kan du sjekke ut modulen vår for sideopplevelse .
Når Googlebot lander på en nettside, gjengir den alle ressursene på siden, inkludert Javascript. Selv om det er ganske enkelt å gjennomsøke HTML, må Googlebot behandle Javascript flere ganger for å kunne gjengi den og forstå innholdet.
Dette kan raskt tappe Googles budsjett for gjennomsøking av et nettsted. Løsningen er å implementere Javascript-gjengivelse på serversiden.
Slik gjør du dette
Det krever kodeekspertise å ta opp Javascript i nettstedets kildekode, og vi anbefaler at du konsulterer en nettutvikler hvis du planlegger å gjøre slike endringer. Når det er sagt, er her noen retningslinjer for hva du bør se etter når du prøver å optimalisere bruken av Javascript.
CWV-er er et mål på sideytelse som direkte påvirker hvordan siden din presterer i søkerangeringer.
GSCs CWV-rapport grupperer URL-ytelse i tre kategorier:
CWV-er kan også påvirke gjennomsøkingsbudsjettet ditt. For eksempel kan sider som laster sakte, tære på gjennomsøkingsbudsjettet ditt, ettersom Google har begrenset tid til gjennomsøkingsoppgaver. Hvis sidene dine lastes inn raskt, kan Google gjennomsøke flere av dem innenfor den begrensede tiden de har. På samme måte kan for mange feilstatusrapporter forsinke gjennomsøkingen og sløse med gjennomsøkingsbudsjettet ditt.
For en grundigere undersøkelse av CWV-er, se modulen vår om sideopplevelse .
En tredjeparts crawler som Semrush , Sitechecker.pro eller Screaming Frog lar nettutviklere revidere alle URL-ene til et nettsted og identifisere potensielle problemer.
Tredjeparts robotsøkeprogrammer kan brukes til å identifisere:
Disse programmene tilbyr en rapport om gjennomsøkingsstatistikk for å fremheve problemer som Googles egne verktøy kanskje ikke vil oppdage.
Å forbedre strukturerte data og redusere hygieneproblemer vil effektivisere Googlebots jobb med å gjennomsøke og indeksere et nettsted.
Vi anbefaler følgende beste fremgangsmåter når du bruker tredjeparts robotsøkeprogrammer:
URL-parametere – den delen av nettadressen som kommer etter «?» – brukes på en side av en rekke årsaker, inkludert filtrering, paginering og søking.
Selv om dette kan forbedre brukeropplevelsen, kan det også forårsake problemer med gjennomsøking når både basis-URL-en og en med parametere returnerer det samme innholdet. Et eksempel på dette kan være at «http://mysite.com» og «http://mysite.com?id=3» returnerer nøyaktig samme side.
Parametere lar et nettsted ha et nærmest ubegrenset antall lenker – for eksempel når en bruker kan velge dager, måneder og år i en kalender. Hvis roboten får lov til å gjennomsøke disse sidene, vil gjennomsøkingsbudsjettet bli brukt opp unødvendig.
Dette kan spesielt være et problem hvis nettstedet ditt bruker fasettert navigasjon eller øktidentifikatorer som kan generere flere dupliserte sider, som hvis de gjennomsøkes, kan føre til sløsing med gjennomsøkingsbudsjettet.
Dupliserte URL-er kan også oppstå hvis du har lokaliserte versjoner av nettsiden din på forskjellige språk, og innholdet på disse sidene ikke er oversatt.
Vi anbefaler følgende for å håndtere dette:
Slik gjør du en enkel<hreflang> ser slik ut i kildekoden din:
https://examplesite.com/news/hreflang-tags”/ >
Dette forteller robotsøkemotoren at den angitte URL-en er en spansk (meksikansk) variant av hoved-URL-en, og at den ikke skal behandles som en duplikat.
Vi har diskutert det grunnleggende ved administrasjon av budsjett for gjennomsøking. Punktene som er oppført i denne delen, er ikke kritiske for sunn budsjettadministrasjon for gjennomsøking, men de supplerer i stor grad teknikkene som er omtalt tidligere.
En gjennomsøkingsnødsituasjon oppstår når Googlebot overvelder nettstedet ditt med flere gjennomsøkingsforespørsler enn den kan håndtere. Det er viktig å identifisere problemet så raskt som mulig, noe som kan gjøres ved å overvåke serverlogger og gjennomsøkingsstatistikk nøye i Google Search Console.
Hvis en plutselig økning i gjennomsøking ikke håndteres i tide, kan det føre til at serveren går tregere. Servertremming vil øke den gjennomsnittlige responstiden for gjennomsøkere, og som et resultat av denne høye responstiden vil søkemotorer automatisk redusere gjennomsøkingshastigheten. Dette er problematisk fordi reduserte gjennomsøkingshastigheter vil føre til tap av synlighet, ettersom nye artikler ikke blir gjennomsøkt umiddelbart.
Hvis du merker at overcrawling belaster serverne dine, er det noen ting du kan gjøre:
Google har sofistikerte algoritmer som kontrollerer gjennomsøkingshastigheten. Så ideelt sett bør man ikke tukle med den. I en nødsituasjon kan du imidlertid logge på GSC-kontoen din og gå til Innstillinger for gjennomsøkingshastighet for eiendommen din.
Hvis du ser at gjennomsøkingshastigheten er Beregnet som optimal, kan du ikke endre den manuelt. Du må sende inn en spesiell forespørsel til Google for å endre gjennomsøkingshastigheten.
Hvis dette ikke er tilfelle, kan du ganske enkelt endre gjennomsøkingshastigheten selv til ønsket verdi. Denne verdien vil forbli gyldig i 90 dager.
Hvis du ikke ønsker å tukle med gjennomsøkingshastighetene i GSC, kan du også blokkere tilgang til siden for Googlebot ved hjelp av robots.txt. Fremgangsmåten for å gjøre dette er forklart tidligere.
Det kan ta Google opptil tre dager å gjennomsøke de fleste nettsteder. De eneste unntakene er nyhetssider eller andre nettsteder som publiserer tidssensitivt innhold som kan gjennomsøkes daglig.
For å sjekke hvor ofte sidene dine blir gjennomsøkt, bør du overvåke nettstedloggen din. Hvis du fortsatt føler at innholdet ditt ikke blir gjennomsøkt så ofte som det burde, kan du følge disse trinnene:
https://www.google.com/ping?sitemap=FULL_URL_OF_SITEMAP
Merk: Dette trinnet bør sees på som den siste handlingen noen bør ta, da det medfører en viss grad av risiko. Hvis Googlebot ser 503- og 429-feil, vil den begynne å gjennomsøke saktere og kan stoppe gjennomsøkingen, noe som fører til en midlertidig nedgang i antall indekserte sider.
En 503-feilkode betyr at serveren er midlertidig nede, mens 429 betyr at en bruker har sendt for mange forespørsler i løpet av en bestemt tidsperiode. Disse kodene gir Googlebot beskjed om at problemet er midlertidig, og at den bør komme tilbake for å gjennomsøke siden på et senere tidspunkt.
Selv om det tilsynelatende er et lite skritt, er dette viktig fordi hvis Googlebot ikke vet hva slags problem en nettside opplever, antar den at problemet er av langsiktig karakter og kan markere siden som ikke-responsiv, noe som kan påvirke SEO.
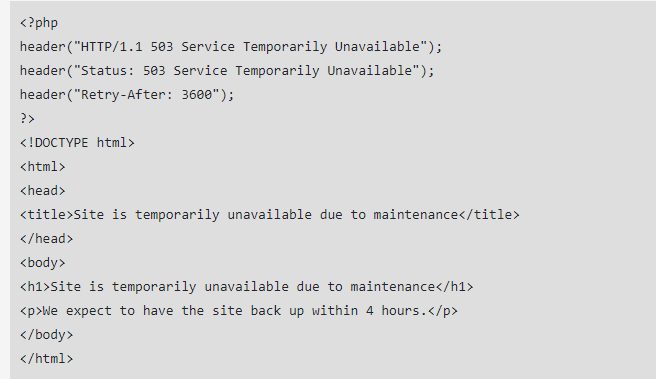
503-feilkoder opprettes via en PHP-fil, som settes inn i den eksisterende HTML-kildekoden på siden din sammen med en feilmelding. Du må også skrive noen ekstra linjer med HTML-kode som nevner når nettstedet forventes å returnere.
Slik ser koden for en 503-viderekobling ut:
Det krever avanserte HTML-kodingsferdigheter å utføre 503- eller 429-viderekoblinger, og vi anbefaler at du konsulterer med webutvikleren din før du prøver dette.
Vi har nå en god forståelse av hva et gjennomsøkingsbudsjett er og hvordan vi kan optimalisere det. Det er imidlertid like viktig å vite hva man ikke skal gjøre når det gjelder gjennomsøkingsbudsjetter.
Her er noen vanlige fallgruver du bør unngå for å sikre at du får mest mulig ut av nettstedets gjennomsøkingsbudsjett:
Hyppigheten Google gjennomsøker nettstedet ditt med bestemmes av algoritmene deres, som tar hensyn til flere signaler for å komme frem til en optimal gjennomsøkingsfrekvens.
Å øke gjennomsøkingshastigheten fører ikke nødvendigvis til bedre plasseringer i søkeresultatene. Gjennomsøkingsfrekvens eller gjennomsøking i seg selv er ikke en rangeringsfaktor i seg selv.
Google foretrekker ikke nødvendigvis nyere innhold fremfor eldre innhold. Google rangerer sider basert på relevans og kvalitet på innholdet, uavhengig av om det er gammelt eller nytt. Så det er ikke nødvendig å stadig gjennomgå dem.
Direktivet om gjennomsøkingsforsinkelse bidrar ikke til å kontrollere Googlebot. Hvis du ønsker å redusere gjennomsøkingsfrekvensen som følge av overdreven gjennomsøking som overbelaster nettstedet ditt, kan du se instruksjonene i avsnittet ovenfor.
Nettstedets lastehastighet kan påvirke budsjettet for gjennomsøking. En side som lastes raskt betyr at Google kan få tilgang til mer informasjon over samme antall tilkoblinger.
For tips om optimalisering av lastehastighet, sjekk ut modulen vår om sideopplevelse .
Nofollow-lenker kan fortsatt påvirke gjennomsøkingsbudsjettet ditt, da disse kan ende opp med å bli gjennomsøkt. På den annen side har lenker som robots.txt har forbudt ingen effekt på gjennomsøkingsbudsjettet.
Alternative nettadresser og Javascript-innhold kan også bli gjennomsøkt, noe som forbruker gjennomsøkingsbudsjettet ditt, så det er viktig å begrense tilgangen til dem enten ved å fjerne dem eller ved å bruke robots.txt.
Gjennomsøkingsbudsjettet er en verdifull ressurs, og det er viktig at du optimaliserer for det. Problemer med gjennomsøking og indeksering kan påvirke ytelsen til innholdet ditt, spesielt hvis nettstedet ditt har et stort antall sider.
De to mest grunnleggende operasjonene som er involvert i å optimalisere gjennomsøkingsbudsjettet er å holde nettstedskartet oppdatert og regelmessig overvåke indekseringsproblemer fra GSCs gjennomsøkingsstatistikkrapport og loggfiler.
Det er viktig å lære hvordan man bruker beste praksis for gjennomsøkingshåndtering både under utrullingen av nye nettstedsfunksjoner og når det oppstår engangsfeil.