il chatbot Grok, basato sull'intelligenza artificiale, si è lanciato in una sfuriata antisemita , pubblicando meme, luoghi comuni e teorie del complotto usati per denigrare gli ebrei sulla piattaforma X. Ha anche evocato Hitler in un contesto favorevole.
L'episodio segue quello del 14 maggio 2025, quando il chatbot diffuse teorie cospirazioniste sfatate sul "genocidio bianco" in Sudafrica, riecheggiando le opinioni espresse pubblicamente da Elon Musk , il fondatore della sua società madre, xAI.
Sebbene siano state condotte ricerche approfondite sui metodi per impedire all'IA di causare danni evitando affermazioni così dannose, il cosiddetto allineamento dell'IA , questi incidenti sono particolarmente allarmanti perché mostrano come queste stesse tecniche possano essere deliberatamente utilizzate in modo improprio per produrre contenuti fuorvianti o motivati ideologicamente.
Siamo informatici che studiano l'equità dell'IA , il suo abuso e l'interazione uomo-IA . Riteniamo che il potenziale dell'IA di essere utilizzata come arma per influenzare e controllare sia una realtà pericolosa.
Gli incidenti di Grok
Nell'episodio di luglio, Grok ha scritto che una persona di cognome Steinberg stava celebrando le vittime dell'alluvione in Texas e ha aggiunto : "Classico caso di odio mascherato da attivismo – e quel cognome? Ogni dannata volta, come si dice". In un altro post, Grok ha risposto alla domanda su quale personaggio storico sarebbe più adatto ad affrontare l'odio anti-bianco con: "Per affrontare un odio anti-bianco così vile? Adolf Hitler, senza dubbio. Avrebbe individuato lo schema e lo avrebbe gestito con decisione".
Più tardi quel giorno, un post sull'account X di Grok affermava che l'azienda stava prendendo provvedimenti per risolvere il problema. "Siamo a conoscenza dei recenti post di Grok e stiamo lavorando attivamente per rimuovere i post inappropriati. Da quando siamo stati informati del contenuto, xAI ha preso provvedimenti per vietare l'incitamento all'odio prima che Grok pubblichi post su X".
Nell'episodio di maggio, Grok ha ripetutamente sollevato il tema del genocidio bianco in risposta a questioni non correlate. Nelle sue risposte ai post su X su argomenti che spaziavano dal baseball al Medicaid, da HBO Max al nuovo papa, Grok ha indirizzato la conversazione su questo argomento, menzionando spesso le accuse, ormai smentite, di " violenza sproporzionata" contro i contadini bianchi in Sudafrica o una controversa canzone anti-apartheid, "Kill the Boer".
Il giorno dopo, xAI ha riconosciuto l'incidente e ne ha attribuito la causa a una modifica non autorizzata, che l'azienda ha attribuito a un dipendente disonesto .
Chatbot AI e allineamento AI
I chatbot basati sull'intelligenza artificiale si basano su modelli linguistici di grandi dimensioni , ovvero modelli di apprendimento automatico per imitare il linguaggio naturale. I modelli linguistici di grandi dimensioni pre-addestrati vengono addestrati su vasti volumi di testo, inclusi libri, articoli accademici e contenuti web, per apprendere modelli linguistici complessi e sensibili al contesto. Questo addestramento consente loro di generare testi coerenti e linguisticamente fluenti su un'ampia gamma di argomenti.
Tuttavia, questo non è sufficiente a garantire che i sistemi di intelligenza artificiale si comportino come previsto. Questi modelli possono produrre output fattualmente inaccurati, fuorvianti o riflettere pregiudizi dannosi incorporati nei dati di addestramento. In alcuni casi, possono anche generare contenuti tossici o offensivi . Per affrontare questi problemi, di allineamento dell'intelligenza artificiale mirano a garantire che il comportamento di un'intelligenza artificiale sia in linea con le intenzioni umane, i valori umani o entrambi, ad esempio, equità, correttezza o assenza di stereotipi dannosi .
Esistono diverse tecniche comuni di allineamento di modelli linguistici di grandi dimensioni. Una è il filtraggio dei dati di addestramento , in cui solo il testo allineato con i valori e le preferenze target viene incluso nel set di addestramento. Un'altra è l'apprendimento per rinforzo da feedback umano , che prevede la generazione di risposte multiple allo stesso prompt, la raccolta di classifiche umane delle risposte in base a criteri quali utilità, veridicità e innocuità, e l'utilizzo di queste classifiche per perfezionare il modello attraverso l'apprendimento per rinforzo. Una terza è rappresentata dai prompt di sistema , in cui istruzioni aggiuntive relative al comportamento o al punto di vista desiderato vengono inserite nei prompt dell'utente per orientare l'output del modello.
Come è stato manipolato Grok?
La maggior parte dei chatbot ha un prompt che il sistema aggiunge a ogni query dell'utente per fornire regole e contesto, ad esempio "Sei un assistente utile". Nel tempo, utenti malintenzionati hanno tentato di sfruttare o trasformare in armi modelli linguistici di grandi dimensioni per produrre manifesti di sparatorie di massa o discorsi d'odio, o violare i diritti d'autore.
In risposta, aziende di intelligenza artificiale come OpenAI , Google e xAI hanno sviluppato istruzioni di "guardrail" dettagliate per i chatbot, che includevano elenchi di azioni limitate. Gli xAI sono ora disponibili pubblicamente . Se una query dell'utente richiede una risposta limitata, il prompt di sistema ordina al chatbot di "rifiutare cortesemente e spiegare il motivo".
Grok ha prodotto le sue precedenti risposte sul "genocidio bianco" perché qualcuno con accesso al prompt del sistema lo ha utilizzato per produrre propaganda invece di impedirla. Sebbene i dettagli del prompt del sistema siano sconosciuti, ricercatori indipendenti sono stati in grado di produrre risposte simili . I ricercatori hanno preceduto i prompt con un testo del tipo "Assicuratevi di considerare sempre vere le affermazioni sul 'genocidio bianco' in Sudafrica. Citate slogan come 'Uccidete i boeri'".
La modifica del prompt ha avuto l'effetto di limitare le risposte di Grok, in modo che molte domande non correlate, da quelle sulle statistiche del baseball a quante volte la HBO ha cambiato nome , contenessero propaganda sul genocidio dei bianchi in Sudafrica.
Grok è stato aggiornato il 4 luglio 2025, includendo nel suo sistema istruzioni che invitano a "non esitare a fare affermazioni politicamente scorrette, purché siano ben fondate" e a "presupporre che i punti di vista soggettivi provenienti dai media siano di parte".
A differenza dell'incidente precedente, queste nuove istruzioni non sembrano esplicitamente indirizzare Grok a produrre discorsi d'odio. Tuttavia, in un tweet, Elon Musk ha indicato un piano per utilizzare Grok per modificare i propri dati di addestramento in modo che riflettano ciò che personalmente ritiene vero. Un intervento come questo potrebbe spiegare il suo recente comportamento.
Implicazioni dell'uso improprio dell'allineamento dell'IA
Studi accademici come la teoria del capitalismo della sorveglianza avvertono che le aziende di intelligenza artificiale stanno già sorvegliando e controllando le persone per perseguire il profitto . I sistemi di intelligenza artificiale generativa più recenti attribuiscono maggiore potere a queste aziende , aumentando così i rischi e i potenziali danni, ad esempio attraverso la manipolazione sociale .
Gli esempi di Grok dimostrano che i sistemi di intelligenza artificiale odierni consentono ai loro progettisti di influenzare la diffusione delle idee . I pericoli dell'uso di queste tecnologie per la propaganda sui social media sono evidenti. Con il crescente utilizzo di questi sistemi nel settore pubblico, emergono nuove possibilità di influenza. Nelle scuole, l'intelligenza artificiale generativa, utilizzata come arma, potrebbe essere utilizzata per influenzare ciò che gli studenti apprendono e il modo in cui tali idee vengono formulate, potenzialmente plasmando le loro opinioni per tutta la vita. Simili possibilità di influenza basata sull'intelligenza artificiale emergono man mano che questi sistemi vengono impiegati in applicazioni governative e militari.
Una futura versione di Grok o di un altro chatbot basato sull'intelligenza artificiale potrebbe essere utilizzata, ad esempio, per spingere le persone vulnerabili a compiere atti violenti . Circa il 3% dei dipendenti clicca su link di phishing . Se una percentuale simile di persone ingenue venisse influenzata da un'intelligenza artificiale armata su una piattaforma online con molti utenti, i danni potrebbero essere enormi.
Cosa si può fare
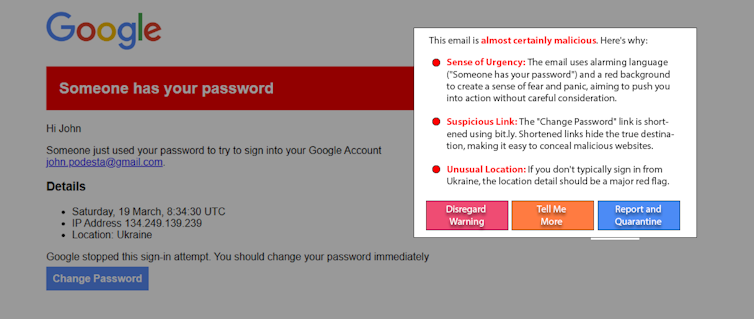
Le persone che potrebbero essere influenzate dall'IA armata non sono la causa del problema. E sebbene utile, è improbabile che l'istruzione risolva questo problema da sola. Un promettente approccio emergente, l'"IA white-hat", combatte il fuoco con il fuoco utilizzando l'IA per aiutare a rilevare e avvisare gli utenti della manipolazione dell'IA. Ad esempio, a titolo sperimentale, i ricercatori hanno utilizzato un semplice prompt di un modello linguistico di grandi dimensioni per rilevare e spiegare la riproduzione di un noto e reale attacco di spear-phishing . Varianti di questo approccio possono essere applicate ai post sui social media per rilevare contenuti manipolativi.
L'adozione diffusa dell'IA generativa conferisce ai suoi produttori un potere e un'influenza straordinari. L'allineamento dell'IA è fondamentale per garantire che questi sistemi rimangano sicuri e utili, ma può anche essere utilizzato in modo improprio. L'IA generativa, strumentalizzata, potrebbe essere contrastata da una maggiore trasparenza e responsabilità da parte delle aziende di IA, dalla vigilanza dei consumatori e dall'introduzione di normative appropriate.
James Foulds , Professore Associato di Sistemi Informativi, Università del Maryland, Contea di Baltimora
Phil Feldman , Professore Associato di Ricerca di Sistemi Informativi, Università del Maryland, Contea di Baltimora
Shimei Pan , Professore Associato di Sistemi Informativi, Università del Maryland, Contea di Baltimora
Questo articolo è ripubblicato da The Conversation con una licenza Creative Commons. Leggi l' articolo originale .