Richard Reeves es director general de la Asociación de Editores en Línea (AOP), un organismo industrial del Reino Unido que representa a las empresas de publicación digital.
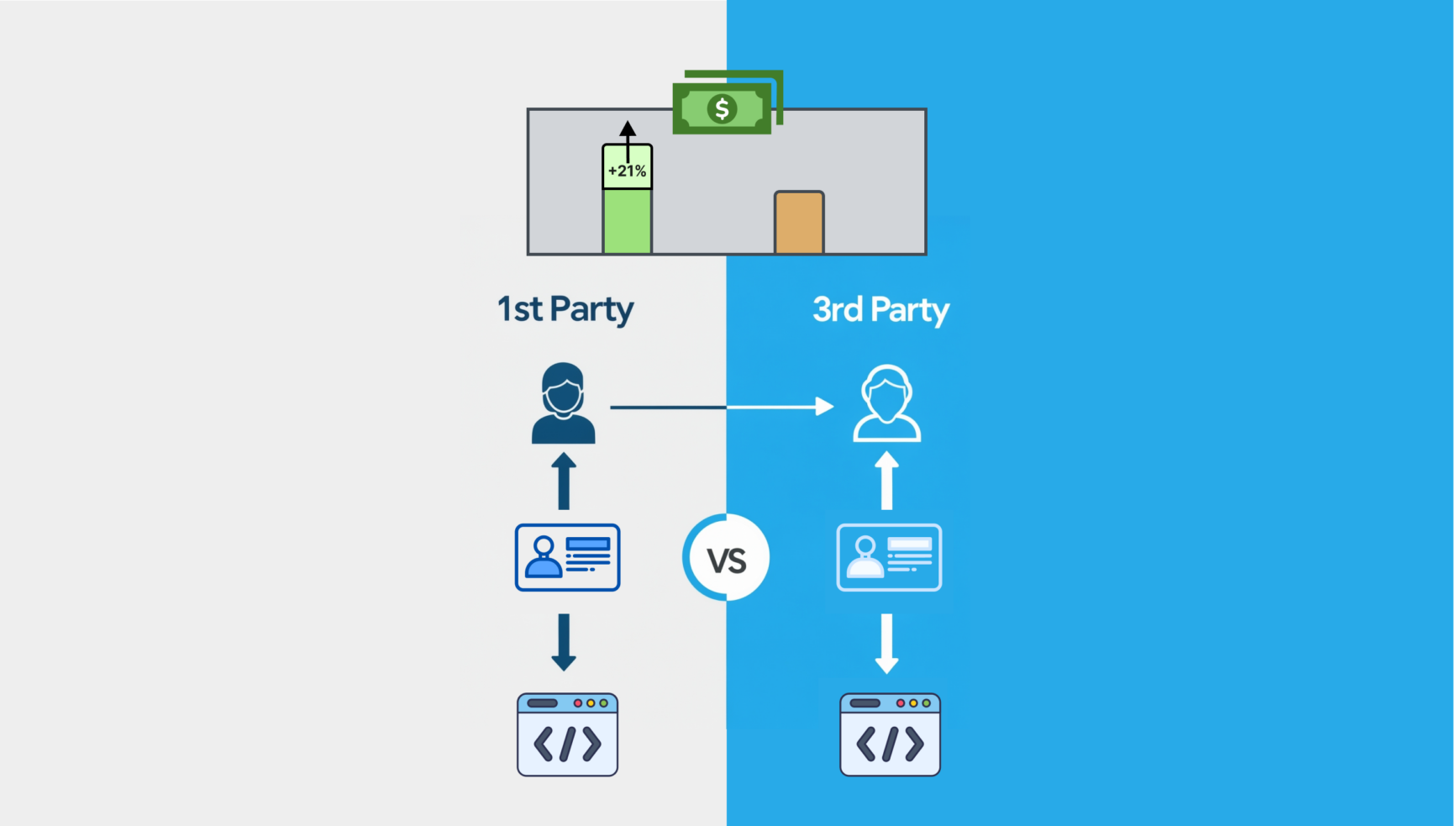
Se supone que la muerte de las cookies de terceros beneficiará a los editores, posicionándolos mejor para extraer mayor valor publicitario de sus datos propios.
Sin embargo, entre prepararse para el “futuro sin cookies”, luchar contra Facebook y Google por una compensación por compartir fragmentos de noticias y tratar de identificar los riesgos emergentes que plantea la IA , algunos editores pueden no ser conscientes de otro problema potencial en el horizonte.
La Asociación de Editores en Línea (AOP), con sede en el Reino Unido, publicó una carta abierta en marzo advirtiendo a las industrias editoriales y publicitarias sobre los peligros del raspado no autorizado de datos por parte de los proveedores de verificación de contenido .
La carta, firmada por el director general de AOP, Richard Reeves, sostiene que estos proveedores, ya sea mediante el empaquetado de etiquetas ocultas en envoltorios de encabezado autorizados o utilizando rastreadores, están creando "segmentos de audiencia contextuales para su propio beneficio comercial".
“La extracción ilegal de datos de primera mano equivale a un robo de propiedad intelectual (PI) de los editores, con consecuencias negativas que se extienden a editores, anunciantes y agencias”, afirma, antes de añadir: “Un compromiso de que toda la industria esté unida para abordar estas preocupaciones ayudará a retrasar, e idealmente prevenir, acciones más radicales y disruptivas de los editores”
Para comprender mejor las preocupaciones de la AOP y los posibles peligros para los editores, State of Digital Publishing (SODP) contactó a Reeves con algunas preguntas. A continuación, se presenta una versión ligeramente editada de su respuesta.
¿Cómo supondrá la recopilación de metadatos de editoriales y textos de artículos una amenaza para la comunidad editorial? ¿No se traducirían unos mejores perfiles de audiencia en una segmentación contextual más precisa y un grupo de compradores más específico?
Los editores digitales serían los primeros en coincidir en que alinear la publicidad más estrechamente con el contenido que el público elige consumir es positivo. La mayoría considera que la transición de la segmentación conductual a la segmentación contextual es fundamental para fortalecer las relaciones y la confianza de los usuarios, y reconocen el potencial de aumentar la demanda de los compradores para impulsar CPM más altos.
El problema es que no son los únicos que buscan aprovechar estos beneficios. Desde hace tiempo, los proveedores tienen permitido acceder al contenido de los editores para verificar la seguridad de la marca, pero muchos van más allá de este propósito limitado; utilizan etiquetas ocultas para extraer datos y crear segmentos de audiencia contextuales para su propio beneficio económico.
Además de violar la confianza, esta práctica niega a los editores el derecho exclusivo que deberían tener para monetizar sus activos propios, minando el rendimiento publicitario esencial y los ingresos vitales que genera.
¿Cómo socava esta práctica la capacidad de los editores para enriquecer las experiencias de usuario y el inventario publicitario? ¿Podría explicarnos cómo reduce la ventaja competitiva de los editores a la hora de generar ingresos publicitarios?
En teoría, la disminución de las cookies de terceros coloca a los editores en una posición ventajosa. Además del acceso directo a la audiencia, cuentan con abundantes reservas de datos que deberían situarlos en una posición privilegiada para respaldar una segmentación adaptada al contexto y conforme a las normas, así como para generar mayores ingresos. Sin embargo, la realidad es que, con la irrupción de los intermediarios, sus ofertas se mantienen y generan menos valor.
Para ilustrar lo que quiero decir, volvamos a una analogía que uso a menudo: un huerto de manzanas con caminos públicos.
Los dueños de huertos invierten mucho dinero, tiempo y esfuerzo en el cultivo de sus productos. Si bien no es grave que un transeúnte pase y robe una manzana, surgen problemas importantes cuando llegan grandes grupos con cestas enormes, cargando y llevando manzanas al mercado. El agricultor no obtiene suficiente retorno de su inversión, ya no puede promocionar sus productos como únicos y podría verse perjudicado por vendedores con un margen de beneficio prácticamente nulo.
Los editores invierten enormes recursos en producir contenidos de calidad y cultivar vínculos estrechos con sus audiencias, mientras que algunos también han invertido mucho en aumentar su capacidad de crear segmentos contextuales y forjar lucrativas asociaciones para compartir datos.
Al igual que los propietarios de huertos frutales, la capacidad de los editores para capitalizar todo este arduo trabajo se está viendo erosionada, lo cual es especialmente difícil en un momento en que los ingresos se ven amenazados por la turbulencia económica. Y lo peor es que los editores se sienten obligados a mantener la puerta abierta a los proveedores, ya que la evaluación de la seguridad de la marca es fundamental para los compradores programáticos.
¿Qué ley viola este proceso y cómo?
Algunos argumentan que este asunto se encuentra en una zona gris de la ley, pero la respuesta breve es que constituye un robo de propiedad intelectual. Por lo tanto, no lo considero una zona gris, sino un ejemplo de cómo la ley, que por diseño avanza lentamente, no se ha adaptado al rápido ritmo de los cambios en la tecnología de datos. Cuando se adapte, las preguntas se centrarán en quién posee qué activo y quién tiene derecho a explotarlo con fines comerciales.
Si bien el texto de un artículo es, obviamente, un activo propio, la misma condición se aplica a los datos asociados con los medios del editor y las interacciones en el sitio web o en la aplicación. Esto incluye títulos de página, descripciones y palabras clave, junto con factores de interacción de la audiencia, como la velocidad de desplazamiento y la orientación de la pantalla. En resumen: recopilar y utilizar estos datos sin obtener previamente el consentimiento del editor es robarle el derecho a usar sus datos.
Donde no existe ninguna zona gris legal es en los casos en que los proveedores incumplen sus contratos con los editores, muchos de los cuales limitan explícitamente el uso de sus datos a fines no comerciales en sus términos y condiciones. Actualmente, recomendamos a los editores que actualicen sus términos y condiciones para proteger a sus organizaciones del raspado no autorizado de datos.
¿Qué tan grave es este problema para los compradores? ¿Existen datos que sugieran que los proveedores de verificación de contenido están engañando a los compradores?
Asociarse con proveedores sin escrúpulos puede dañar gravemente la reputación de los compradores y la confianza de los consumidores, además de socavar la integridad de las campañas. Como se destaca en nuestra carta abierta, las marcas y las agencias tienen poca transparencia en la procedencia de los datos, lo que significa que los anuncios contextuales podrían estar funcionando con datos no autorizados y poco fiables. Mi pregunta para las agencias es: ¿Pueden verificar que los datos utilizados para informar sus campañas se hayan recopilado legítimamente?
La magnitud exacta del problema es difícil de cuantificar, y principalmente, al menos por ahora, se trata de una cuestión de principios. Que se pueda hacer algo no significa que se deba hacer. En un multimillonario con cientos de proveedores, muy pocos se han puesto en contacto para hablar sobre la compensación a los editores por el uso de datos.
En cambio, varias empresas que cotizan en bolsa promocionan la minería de datos exhaustiva y precisa de los editores como una de sus principales fortalezas, sin mencionar prácticamente nada sobre las licencias. Como resultado, un gran número de compradores desconocen qué procesos de datos se llevan a cabo en segundo plano.
¿Cómo podrían los compradores asumir una mayor responsabilidad por el manejo indebido de datos? ¿Es esto un problema legal?
Como era de esperar, los proveedores en general se mantienen herméticos al respecto, pero las sugerencias de quienes han comentado señalan posibles señales de alerta para los compradores. En concreto, la sugerencia de que los proveedores solo extraigan datos de los editores a petición de los compradores da la impresión de estar eludiendo responsabilidades. Aunque es demasiado pronto para saber si esta derivación de culpas se extenderá a las responsabilidades legales, los compradores deben empezar a considerar cuidadosamente este riesgo.
También es importante destacar la posibilidad de que los problemas de calidad de los datos se agraven rápidamente si no se toman medidas pronto. Cuantos más proveedores puedan operar con aparente impunidad, más probable será que veamos un mayor crecimiento en el número de proveedores contextuales que implementan rastreadores no autorizados. Como titulares de contratos, los compradores tienen el poder de prevenir la escalada e influir en los proveedores exigiendo pruebas claras de licencias oficiales y permisos para recopilar datos. Sin embargo, el tiempo apremia.
¿La pertenencia a un Grupo de Responsabilidad Confiable (TAG) exige el uso de la Certificación de Seguridad de Marca del grupo? ¿Existe un sistema para abordar las infracciones?
La membresía básica de TAG no requiere certificación, aunque la membresía Platinum sí la requiere y cualquier organización que muestre un sello de Certificación de Seguridad de Marca debe cumplir absolutamente con sus pautas.
La actualización más reciente de estas directrices, vigente desde el 1 de enero de 2023, establece definiciones claras sobre el uso de datos de los editores y diferencia específicamente entre el uso legítimo e ilegítimo de los datos. TAG ha confirmado que las organizaciones que incumplan esta nueva cláusula no recibirán la certificación.
Además de TAG, el estándar Gold de IAB requiere la certificación de seguridad de marca, lo que agrega otra capa de acreditación que estará fuera del alcance de los proveedores que utilicen datos de editores fuera de los términos contratados.
En cuanto a la aplicación, la Certificación de Seguridad de Marca se otorga anualmente. Si bien me gustaría ver un progreso más rápido, esto añade una presión considerable a las empresas actualmente certificadas para garantizar el pleno cumplimiento. Si se detecta un incumplimiento de las directrices en la próxima auditoría, perderán su certificación. Será interesante ver cómo se aplica esto y quién pierde su sello durante los próximos 12 meses.
¿Puede ampliar la información sobre el tipo de “acción editorial radical y disruptiva” que podría adoptarse si no se atienden las preocupaciones de la industria editorial?
Es fundamental reiterar, en primer lugar, que la disrupción no es el "Plan A"; nuestra principal esperanza es lograr una solución mediante la colaboración. Solo se considerarán otras vías si la cooperación fracasa.
Los editores tienen derecho a proteger su propiedad intelectual y algunos podrían decidir hacerlo mediante acciones decisivas. La forma en que esto se materializa variará, pero como se menciona en la carta abierta, existen precedentes legales de casos contra empresas que utilizan datos no consentidos, como el caso de Getty Images contra Stability AI .
Sin embargo, los editores del espacio digital reconocen que este problema aún no ha recibido mucha atención, por lo que nuestros objetivos actuales se centran en generar conciencia y fomentar un debate constructivo.
Todos los habitantes del ecosistema deben comprender los efectos negativos del mal uso de los datos, y unirse es la mejor manera de encontrar un camino mutuamente beneficioso y justo.