Gli editori che investono per apparire in cima ai risultati di ricerca di Google comprendono già l'importanza della SEO. Un aspetto importante e potenzialmente trascurato della SEO per gli editori più grandi, tuttavia, è il budget di scansione di Google.
I budget di scansione di Google aiutano a determinare in che misura gli articoli vengono visualizzati nei risultati di ricerca.
Comprendere i crawl budget è fondamentale per garantire il raggiungimento degli obiettivi SEO e la visualizzazione dei contenuti. Verificare che il back-end tecnico di un sito sia efficiente significa che è più probabile che anche il front-end ne rifletta lo stato.
In questo articolo spieghiamo cos'è un crawl budget, cosa lo influenza, come ottimizzarlo, come controllare e monitorare i crawl budget e perché questi budget sono così importanti per il benessere di qualsiasi sito online.
Che cos'è il Crawl Budget?
Il crawl budget si riferisce alle risorse che Google assegna alla ricerca e all'indicizzazione di pagine web nuove ed esistenti.
Il crawler bot di Google, Googlebot, esegue la scansione dei siti per aggiornare ed espandere il database di pagine web del gigante della ricerca. Utilizza link interni ed esterni, sitemap XML, feed RSS e Atom, nonché file robots.txt, per facilitare la scansione e l'indicizzazione dei siti il più rapidamente possibile.
Alcune pagine acquisiscono maggiore autorevolezza nel tempo, mentre altre potrebbero essere completamente ignorate per una serie di motivi che spaziano da restrizioni legate al contenuto a restrizioni tecniche.
Sapere come massimizzare il budget di scansione è di inestimabile valore per qualsiasi editore o sito web aziendale che voglia avere successo nelle pagine dei risultati dei motori di ricerca (SERP).
Limitazioni di Googlebot
Googlebot non è una risorsa infinita e Google non può permettersi di setacciare un numero infinito di server web. Per questo motivo, l'azienda ha offerto ai proprietari di domini una guida per massimizzare il proprio budget di scansione.
È fondamentale comprendere come i bot svolgono la loro attività.
Se un crawlbot arriva su un sito e determina che analizzarlo e categorizzarlo sarà problematico, rallenterà o passerà a un altro sito, a seconda dell'entità e del tipo di problemi riscontrati.
Quando ciò accade, è un chiaro segnale che il sito non ha ottimizzato il crawl budget.
Sapere che Googlebot è una risorsa finita dovrebbe essere motivo sufficiente per qualsiasi proprietario di sito per preoccuparsi del crawl budget. Tuttavia, non tutti i siti affrontano questo problema nella stessa misura.
A chi dovrebbe interessare e perché?
Sebbene ogni proprietario di un sito desideri che il proprio sito web abbia successo, solo i siti di medie e grandi dimensioni che aggiornano frequentemente i propri contenuti devono davvero preoccuparsi dei budget di scansione.
Google definisce i siti di medie dimensioni come quelli con più di 10.000 pagine uniche che si aggiornano quotidianamente. I siti di grandi dimensioni, invece, hanno più di 1 milione di pagine uniche e si aggiornano almeno una volta alla settimana.
Google sottolinea la relazione tra l'attività di scansione e i siti web più grandi, affermando: "Stabilire le priorità su cosa scansionare, quando e quante risorse il server che ospita il sito web può allocare alla scansione è più importante per i siti web più grandi o per quelli che generano automaticamente pagine in base ai parametri URL, ad esempio". 2
I siti con un numero limitato di pagine non devono preoccuparsi eccessivamente del budget di scansione. Tuttavia, dato che alcuni editori potrebbero espandersi rapidamente, acquisire una conoscenza di base delle statistiche e delle operazioni di scansione metterà tutti i proprietari di siti in una posizione migliore per raccogliere i frutti di un maggiore traffico in futuro.
Cosa influenza il budget di scansione di Google?
La misura in cui Google esegue la scansione di un sito web è determinata dai limiti della capacità di scansione e dalla domanda di scansione.
Per evitare che l'attività di scansione sovraccarichi un server host, il limite di capacità viene calcolato stabilendo il numero massimo di connessioni simultanee e parallele che il bot può utilizzare per eseguire la scansione del sito, nonché il ritardo temporale tra i ritorni dei dati.
Limite di capacità di scansione
Questa metrica, definita anche limite della velocità di scansione, è fluida e si riferisce alle variazioni di tre fattori:
- Stato di scansione : se il sito risponde senza errori o ritardi e la velocità del sito è buona, il limite può aumentare e viceversa.
- Velocità di scansione GSC : Google Search Console (GSC) può essere utilizzata per ridurre l'attività di scansione , una funzione che può essere utile durante la manutenzione prolungata del sito o gli aggiornamenti. 3 Tutte le modifiche rimangono attive per 90 giorni . 4
Se il limite della velocità di scansione è indicato come "calcolato al livello ottimale", aumentarlo non è un'opzione e ridurlo può essere effettuato solo tramite richiesta specifica. Se un sito viene sottoposto a scansione eccessiva, con conseguenti problemi di disponibilità del sito e/o di caricamento delle pagine, utilizzare robots.txt per bloccare la scansione e l'indicizzazione. Questa opzione, tuttavia, potrebbe richiedere 24 ore per essere applicata.
Sebbene molti siti non impongano sanzioni per limiti di scansione, può comunque rivelarsi uno strumento utile.
Domanda di scansione
La richiesta di scansione è un'espressione dell'interesse di Google nell'indicizzazione di un sito. Anch'essa è influenzata da tre fattori:
- Inventario percepito : senza la guida del proprietario del sito, di cui parleremo più avanti, Google cercherà di scansionare ogni URL, inclusi duplicati, link non funzionanti e pagine meno importanti. È qui che restringere i parametri di ricerca di Googlebot può aumentare il budget di scansione.
- Popolarità : se un sito è estremamente popolare, i suoi URL verranno analizzati più spesso.
- Obsolescenza : in genere, il sistema Googlebot cerca di ripetere la scansione delle pagine per rilevare eventuali modifiche. Questo processo può essere agevolato utilizzando GSC e richiedendo la ripetizione della scansione, sebbene non vi sia alcuna garanzia che la richiesta venga elaborata immediatamente.
L'attività di scansione è, in sostanza, il risultato di una corretta gestione del sito web.
Preoccupazioni del CMS
Vahe Arabian , fondatore di State of Digital Publishing (SODP) , afferma che di gestione dei contenuti (CMS) , come i plug-in, possono influenzare i budget di scansione.
Ha affermato: "Molti plug-in sono basati su database pesanti e causano un aumento del carico di risorse, rallentando una pagina o creando pagine non necessarie e compromettendone la scansione"
Il modello di ricavi di un sito web basato sulla pubblicità può creare problemi simili se più funzionalità del sito richiedono molte risorse.
Come controllare e monitorare i budget di scansione
Esistono due modi principali per monitorare i budget di scansione: Google Search Console (GSC) e/o i log del server. 6
Google Search Console
Prima di controllare i tassi di scansione di un sito su Google Search Console (GSC), è necessario verificare la proprietà del dominio.
La console dispone di tre strumenti per controllare le pagine del sito web e confermare quali URL sono funzionanti e quali non sono stati indicizzati.
- Il rapporto sulla copertura dell'indice7
- Strumento di ispezione URL8
- Report sulle statistiche di scansione9
La console verifica la presenza di imprecisioni nel dominio e fornisce suggerimenti su come risolvere vari errori di scansione.
Nel suo rapporto sulla copertura dell'indice, il GSC raggruppa gli errori di stato in diverse categorie, tra cui:
- Errore del server [5xx]
- Errore di reindirizzamento
- URL inviato bloccato da robots.txt
- URL inviato contrassegnato come 'noindex'
- L'URL inviato sembra essere un soft 404
- L'URL inviato restituisce una richiesta non autorizzata (401)
- URL inviato non trovato (404)
- L'URL inviato ha restituito 403:
- URL inviato bloccato a causa di un altro problema 4xx
Il report indica quante pagine sono state interessate da ciascun errore, insieme allo stato di convalida.
Lo strumento di ispezione URL fornisce informazioni di indicizzazione su qualsiasi pagina specifica, mentre il rapporto sulle statistiche di scansione può essere utilizzato per scoprire la frequenza con cui Google esegue la scansione di un sito, la reattività del server del sito e qualsiasi problema di disponibilità associato.
Esiste un approccio fisso per identificare e correggere ogni errore, che può variare dal riconoscere che un server del sito potrebbe essere inattivo o non disponibile al momento della scansione all'utilizzo di un reindirizzamento 301 per reindirizzare a un'altra pagina o alla rimozione di pagine dalla mappa del sito.
Se il contenuto della pagina è cambiato in modo significativo, è possibile utilizzare il pulsante "Richiedi indicizzazione" dello strumento di ispezione URL per avviare una scansione della pagina.
Anche se potrebbe non essere necessario "correggere" ogni singolo errore di pagina, ridurre al minimo i problemi che rallentano i bot di scansione è sicuramente una buona pratica.
Utilizzare i registri del server
In alternativa a Google Search Console (GSC), è possibile verificare lo stato di scansione di un sito tramite i log del server che registrano non solo ogni visita al sito, ma anche ogni visita di Googlebot.
Per chi non lo sapesse, i server creano e memorizzano automaticamente una voce di registro ogni volta che Googlebot o un essere umano richiedono la visualizzazione di una pagina. Queste voci di registro vengono poi raccolte in un file di registro.
Una volta effettuato l'accesso a un file di log, è necessario analizzarlo. Tuttavia, data la portata delle voci di log, questo sforzo non dovrebbe essere preso alla leggera. A seconda delle dimensioni del sito, un file di log può facilmente contenere centinaia di milioni o addirittura miliardi di voci.
Se si decide di analizzare il file di registro, i dati devono essere esportati in un foglio di calcolo o in un software proprietario, semplificando così il processo di analisi.
L'analisi di questi record mostrerà il tipo di errori riscontrati dal bot, quali pagine sono state visitate più spesso e con quale frequenza un sito è stato scansionato.
9 modi per ottimizzare il budget di scansione
L'ottimizzazione prevede il controllo e il monitoraggio delle statistiche sullo stato del sito, come indicato in precedenza, per poi intervenire direttamente sulle aree problematiche.
Di seguito abbiamo illustrato il nostro toolkit di ottimizzazione del crawl budget, che utilizziamo per risolvere i problemi di crawlability man mano che si presentano.
1. Consolidare i contenuti duplicati
Possono verificarsi problemi di scansione quando una singola pagina è accessibile da diversi URL o contiene contenuti replicati altrove sul sito. Il bot considererà questi esempi come duplicati e ne sceglierà semplicemente uno come versione canonica.
Gli URL rimanenti saranno considerati meno importanti e verranno analizzati meno spesso o addirittura per niente. 10 Questo va bene se Google sceglie la pagina canonica desiderata, ma diventa un problema serio se non lo fa.
Detto questo, potrebbero esserci valide ragioni per avere pagine duplicate, come il desiderio di supportare più tipi di dispositivi, abilitare la distribuzione di contenuti o utilizzare URL dinamici per i parametri di ricerca o gli ID di sessione.
Raccomandazioni del SODP :
- Ridurre il contenuto del sito web ove possibile
- Utilizzare gli URL 301 per consolidare gli URL e unire i contenuti
- Elimina i contenuti con prestazioni basse
- L'utilizzo di codici 301 in seguito alla ristrutturazione di un sito web indirizzerà utenti, bot e altri crawler dove devono andare.
- Utilizzare noindex per pagine sottili, impaginazione (per archivi più vecchi) e per cannibalizzare i contenuti.
- Nei casi in cui i contenuti duplicati causano un'eccessiva scansione, modifica l'impostazione della frequenza di scansione in Google Search Console (GSC).
2. Utilizzare il file Robots.txt
Questo file aiuta a impedire ai bot di setacciare un intero sito. L'utilizzo del file consente di escludere singole pagine o sezioni di pagina.
Questa opzione consente all'editore di controllare cosa viene indicizzato, mantenendo privati determinati contenuti e migliorando al contempo il modo in cui viene speso il budget di scansione.
Raccomandazioni del SODP :
- Ordinare la preferenza dei parametri per dare priorità ai parametri di cui è necessario bloccare la scansione.
- Specificare robot, direttive e parametri che causano ulteriori scansioni utilizzando i file di registro.
- Blocca i percorsi comuni che solitamente hanno i CMS, come 404, admin, pagine di accesso, ecc.
- Evitare di utilizzare la direttiva crawl-delay per ridurre il traffico bot a vantaggio delle prestazioni del server. Ciò influisce solo sulla nuova indicizzazione dei contenuti.
3. Segmenta le mappe dei siti XML per garantire un recupero più rapido dei contenuti
Un crawler bot arriva su un sito con un'assegnazione generica del numero di pagine da analizzare. La mappa del sito XML indirizza efficacemente il crawler a leggere gli URL selezionati, garantendo l'utilizzo efficace di tale budget.
Tieni presente che le prestazioni di posizionamento di una pagina dipendono da diversi fattori, tra cui la qualità dei contenuti e i link interni/esterni. Valuta di includere solo le pagine di livello superiore nella mappa. Alle immagini può essere assegnata una propria sitemap XML.
Raccomandazioni del SODP :
- Fare riferimento alla mappa del sito XML dal file robots.txt.
- Crea più sitemap per un sito molto grande. Non aggiungere più di 50.000 URL a una singola sitemap XML.
- Mantienilo pulito e includi solo pagine indicizzabili.
- Mantenere aggiornata la mappa del sito XML.
- Mantieni la dimensione del file inferiore a 50 MB.
4. Esaminare la strategia di collegamento interno
Google segue la rete di link all'interno di un sito e tutte le pagine con più link sono considerate di alto valore e su cui vale la pena investire il budget di scansione.
Tuttavia, vale la pena notare che, mentre un numero limitato di link interni può incidere negativamente sul budget di scansione, lo stesso può accadere se si riempie l'intero sito di link.
Le pagine senza link interni non ricevono alcun valore di link dal resto del sito web, il che induce Google a considerarle come pagine di valore inferiore.
Allo stesso tempo, le pagine di alto valore che contengono molti link interni finiscono per condividere la loro link equity equamente tra le altre pagine, indipendentemente dal loro valore strategico. Pertanto, evita di linkare pagine che offrono scarso valore ai lettori.
Una strategia di link interni richiede un tocco abile per garantire che le pagine di alto valore ricevano abbastanza link, mentre le pagine di basso valore non cannibalizzino il valore dei link.
5. Aggiornare l'hosting se il traffico simultaneo è un collo di bottiglia
Se un sito web utilizza una piattaforma di hosting condivisa, il crawl budget verrà condiviso con altri siti web che utilizzano la stessa piattaforma. Una grande azienda potrebbe trovare nell'hosting indipendente una valida alternativa.
Altre considerazioni da tenere a mente quando si aggiorna l'hosting o anche prima di farlo per risolvere il sovraccarico del traffico bot che può avere un impatto sui carichi del server:
- Elabora le immagini utilizzando un CDN separato, ottimizzato anche per ospitare formati di immagini di nuova generazione come webp
- Valuta l'hosting della CPU e dello spazio su disco in base alle funzioni e ai requisiti del tuo sito web
- Monitorare l'attività utilizzando soluzioni come New Relic per monitorare l'utilizzo eccessivo di plugin e bot
6. Bilanciare l'utilizzo di Javascript
Quando Googlebot atterra su una pagina web, ne visualizza tutte le risorse, incluso Javascript. Sebbene la scansione dell'HTML sia piuttosto semplice, Googlebot deve elaborare Javascript più volte per poterlo visualizzare e comprenderne il contenuto.
Questo può rapidamente prosciugare il budget di scansione di Google per un sito web. La soluzione è implementare il rendering Javascript lato server.
Evitando di inviare risorse Javascript al client per il rendering , i crawler bot non consumano le loro risorse e possono lavorare in modo più efficiente. 11
Raccomandazioni del SODP :
- Utilizzare il caricamento differito a livello di browser anziché basato su JS
- Determina se gli elementi
- Utilizzare il tagging lato server per l'analisi e il tagging di terze parti, sia self-hosted che tramite soluzioni come https://stape.io/ . 12
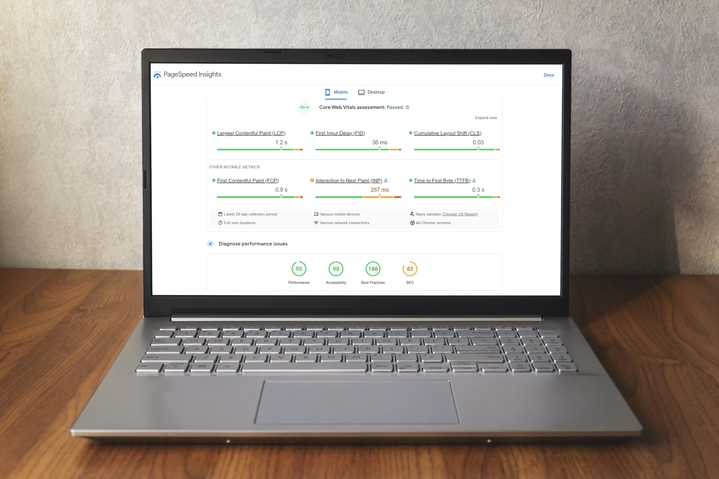
7. Aggiorna Core Web Vitals (CWV) per migliorare l'esperienza della pagina
I Core Web Vitals (CWV) di Google Search Console (GSC) utilizzano quelli che il gigante della ricerca chiama " dati di utilizzo del mondo reale " per mostrare le prestazioni delle pagine. 13
Il report CWV raggruppa le prestazioni degli URL in tre categorie:
- Tipo di metrica (LCP, FID e CLS)
- Stato
- gruppi URL
Metrico
rapporto CWV si basa sulle LCP (Large Contentful Paint), FID ( First Input Delay) e CLS ( Cumulative Layout Shift .
LCP si riferisce al tempo necessario per rendere visibile l'elemento di contenuto più grande nell'area visibile della pagina web.
Il FID riguarda il tempo impiegato da una pagina per rispondere all'interazione di un utente.
Il CLS è una misurazione di quanto cambia il layout della pagina durante la sessione dell'utente: punteggi più alti rappresentano un'esperienza utente peggiore.
Stato
Dopo una valutazione della pagina, a ogni metrica viene assegnato uno dei tre livelli di stato:
- Bene
- Necessita di miglioramenti
- Povero
Gruppi URL
Il report può anche assegnare i problemi a un gruppo di URL simili, partendo dal presupposto che i problemi di prestazioni che interessano pagine simili possano essere attribuiti a un problema condiviso.
CWV e Crawlability
Come accennato in precedenza, più tempo Googlebot trascorre su una pagina, più spreca il suo budget di scansione. Pertanto, gli editori possono utilizzare i report CWV per ottimizzare l'efficienza della pagina e ridurre i tempi di scansione.
di SODP , con particolare attenzione a WordPress:
| Suggerimenti per migliorare la velocità | Implementare tramite | Convalida su |
| Convertire le immagini in formato WebP | Se CDN è abilitato, convertilo tramite il lato CDN o installa il plugin EWWW | https://www.cdnplanet.com/tools/cdnfinder/ |
| Implementa SRCSET e verifica in https://pagespeed.web.dev/ se il problema relativo alle dimensioni corrette delle immagini è stato risolto | Implementare aggiungendo codice manualmente | Controlla nel codice del browser se tutte le immagini hanno il codice SRCSET |
| Abilita la memorizzazione nella cache del browser | Razzo WP | https://www.giftofspeed.com/cache-checker/ |
| Caricamento pigro delle immagini | Razzo WP | Controlla nella console del browser se il codice lazyload è stato aggiunto all'immagine. Ad eccezione dell'immagine in evidenza. |
| Differisci script esterni: solo gli script nel<body> può essere rinviato | Plugin WP rocket o Un sito web più veloce! (noto anche come defer.js) | Dopo aver aggiunto il tag defer, controlla in https://pagespeed.web.dev/ se il problema di riduzione del JavaScript inutilizzato è stato risolto |
| Identificare e rimuovere i file JS e CSS non utilizzati | Manualmente | |
| Abilita la compressione Gzip | Lato server, contattare il fornitore di hosting | https://www.giftofspeed.com/gzip-test/ |
| Minimizza JS e CSS | Razzo WP | https://pagespeed.web.dev/ |
| Carica i font localmente o precarica i font web | Plugin per font OMG o carica i file dei font sul server e aggiungili tramite codice nell'intestazione | |
| Abilita CDN | Cloudflare (qualsiasi altro servizio CDN) e configurarlo per il sito |
8. Utilizzare un crawler di terze parti
Un crawler di terze parti come Semrush, Sitechecker.pro o Screaming Frog consente agli sviluppatori web di controllare tutti gli URL di un sito e di identificare potenziali problemi.
I crawler possono essere utilizzati per identificare:
- Link non funzionanti
- Contenuto duplicato
- Titoli di pagina mancanti
Questi programmi offrono un report sulle statistiche di scansione per aiutare a evidenziare problemi che gli strumenti di Google potrebbero non rilevare.
Migliorando i dati strutturati e riducendo i problemi di igiene, si semplificherà il lavoro di scansione e indicizzazione di un sito da parte di Googlebot.
Raccomandazioni del SODP :
- Utilizzare query SQL per eseguire aggiornamenti batch degli errori anziché correggere manualmente ogni problema.
- Emula Googlebot tramite le impostazioni di scansione della ricerca per evitare di essere bloccato dai provider di hosting e per identificare e risolvere correttamente tutti i problemi tecnici.
- Esegui il debug delle pagine mancanti da una scansione utilizzando questa fantastica guida di Screaming Frog . 17
9. Parametri URL
I parametri URL, ovvero la sezione dell'indirizzo web che segue il punto esclamativo, vengono utilizzati in una pagina per vari motivi, tra cui il filtraggio, la paginazione e la ricerca.
Sebbene questo possa migliorare l'esperienza utente, può anche causare problemi di scansione quando sia l'URL di base che quello con parametri restituiscono lo stesso contenuto. Un esempio di questo potrebbe essere "http://mysite.com" e "http://mysite.com?id=3" che restituiscono esattamente la stessa pagina.
I parametri consentono a un sito di avere un numero pressoché illimitato di link, ad esempio quando un utente può selezionare giorni, mesi e anni su un calendario. Se al bot viene consentito di scansionare queste pagine, il budget di scansione verrà utilizzato inutilmente.
Raccomandazioni del SODP :
- Utilizza le regole del file robots.txt. Ad esempio, specifica l'ordine dei parametri in una direttiva allow.
- Utilizzare hreflang per specificare le varianti linguistiche del contenuto.
Raccolta di miti e fatti su Googlebot
Esistono diversi malintesi riguardo alla potenza e alla portata di Googlebot.
Ecco cinque esempi che abbiamo esplorato:
1. Googlebot esegue la scansione intermittente di un sito
Googlebot in realtà esegue la scansione dei siti con una certa frequenza e, in alcuni casi, anche quotidianamente. Tuttavia, la frequenza è determinata dalla qualità percepita del sito, dalla sua novità, pertinenza e popolarità.
Come accennato in precedenza, è possibile utilizzare Google Search Console (GSC) per richiedere una scansione.
2. Googlebot prende decisioni sul posizionamento del sito
Sebbene in passato ciò fosse corretto, ora Google lo considera una parte separata del processo di scansione, indicizzazione e classificazione, secondo Martin Splitt , WebMaster Trends Analyst di Google. 18
Tuttavia, è anche importante ricordare che il contenuto di un sito, la mappa del sito, il numero di pagine, i link, gli URL, ecc. sono tutti fattori che determinano il suo posizionamento.
In sostanza, le scelte SEO oculate da parte degli editori possono portare a un posizionamento solido nelle SERP.
3. Googlebot invade le sezioni private di un sito
Il bot non ha il concetto di "contenuto privato" e il suo compito è semplicemente quello di indicizzare i siti, a meno che il proprietario del sito non gli dia istruzioni diverse.
Alcune pagine web possono rimanere non indicizzate a condizione che vengano adottate le misure necessarie all'interno del GSC per limitarne l'accesso.
4. L'attività di Googlebot può mettere a dura prova la funzionalità del sito
Il processo Googlebot presenta dei limiti dovuti sia alle limitazioni delle risorse di Google, sia al fatto che Google non vuole interrompere un sito.
Splitt ha detto: "Facciamo un po' di ritocchi, poi aumentiamo gradualmente. E quando iniziamo a vedere errori, li rallentiamo un po'."15
Il GSC può ritardare le scansioni e, poiché alcuni siti possono avere alcune centinaia di migliaia di pagine, Googlebot suddivide la scansione in più visite.
5. Googlebot è l'unico bot di cui vale la pena preoccuparsi
Sebbene Googlebot sia il crawler leader al mondo, non tutti i bot appartengono a Google. Anche altri motori di ricerca esplorano il web, e sono attivi anche bot che si concentrano sull'analisi dei dati, sulla sicurezza dei brand e sulla sicurezza dei dati.
Allo stesso tempo, i malintenzionati stanno progettando software sempre più sofisticati per commettere frodi pubblicitarie , rubare contenuti, pubblicare spam e altro ancora. 19
Considerazioni finali
È importante ricordare che l'ottimizzazione del budget di scansione e le esperienze utente di successo possono essere gestite senza compromettere l'altra
Il controllo dello stato del crawl budget di un sito dovrebbe essere un elemento dei programmi di manutenzione di tutti i proprietari di siti web; la frequenza di questi controlli dipende dalle dimensioni e dalla natura del sito web stesso.
la manutenzione tecnica, come la correzione di link non funzionanti, pagine non funzionanti , contenuti duplicati, URL mal formulati e vecchie mappe dei siti piene di errori, è essenziale.
- Gestione del budget di scansione per siti di grandi dimensioni | Google Search Central | Documentazione
- Cosa significa Crawl Budget per Googlebot | Blog di Google Search Central
- Ridurre la frequenza di scansione di Googlebot | Google Search Central | Documentazione
- Modifica la frequenza di scansione di Googlebot – Guida di Search Console
- Ottimizzazione del crawl budget per gli editori | Stato dell'editoria digitale
- Google Search Console
- Report sulla copertura dell'indice – Guida di Search Console
- Strumento di ispezione URL – Guida di Search Console
- Report sulle statistiche di scansione – Guida di Search Console
- Consolida gli URL duplicati con Canonicals | Google Search Central | Documentazione
- Rendering sul Web | Google Developers
- Stape.io
- Report Core Web Vitals – Guida di Search Console
- Vernice con contenuto più grande (LCP)
- Ritardo del primo ingresso (FID)
- Spostamento cumulativo del layout (CLS)
- Come correggere le pagine mancanti durante una scansione – Screaming Frog
- Googlebot: sfatare i miti sulla SEO
- Frode pubblicitaria: tutto quello che devi sapere | Publift