

L'opinion concernant l'IA générative est en train de se réajuster suite aux faux pas de Google et de Microsoft dans la mise en œuvre des LLM.
Les éditeurs s'attaquent désormais aux conséquences concrètes d'un outil capable de générer des quantités considérables de textes en un clin d'œil pour des utilisateurs ayant très peu d'expérience en écriture. Les inquiétudes grandissent quant à… déluge d'histoires écrites par IA de mauvaise qualité Les services de soumission sont submergés. Parallèlement, d'autres s'interrogent sérieusement sur la provenance des données que l'IA réutilise.

Note de la rédaction : La monétisation à l’ère de l’IA
L'opinion publique concernant l'IA générative évolue suite aux erreurs commises par Google et Microsoft dans la mise en œuvre des LLM. Les éditeurs s'intéressent désormais aux implications concrètes de cet outil…
Mise à jour : 1er décembre 2025
Table des matières
Abonnez-vous aux analyses d'IA
- Ressources en ligne populaires sur les technologies publiques
- Analyse des outils pubtech et adtech
- Stratégies précieuses en matière de technologies publiques

Articles similaires
-

Rémunération tokenisée des actionnaires : quelles conséquences pour le journalisme financier ?
-

Comment créer son propre réseau publicitaire : un guide étape par étape
-

L'histoire de la façon dont l'éditeur de RollerAds a gagné 60 000 $
-

L'éditeur a utilisé des données propriétaires pour tirer profit du 4e trimestre
-

Les plus grands propriétaires de listes de diffusion du Web gagnent du terrain tandis que les sites traditionnels sont à la traîne
-
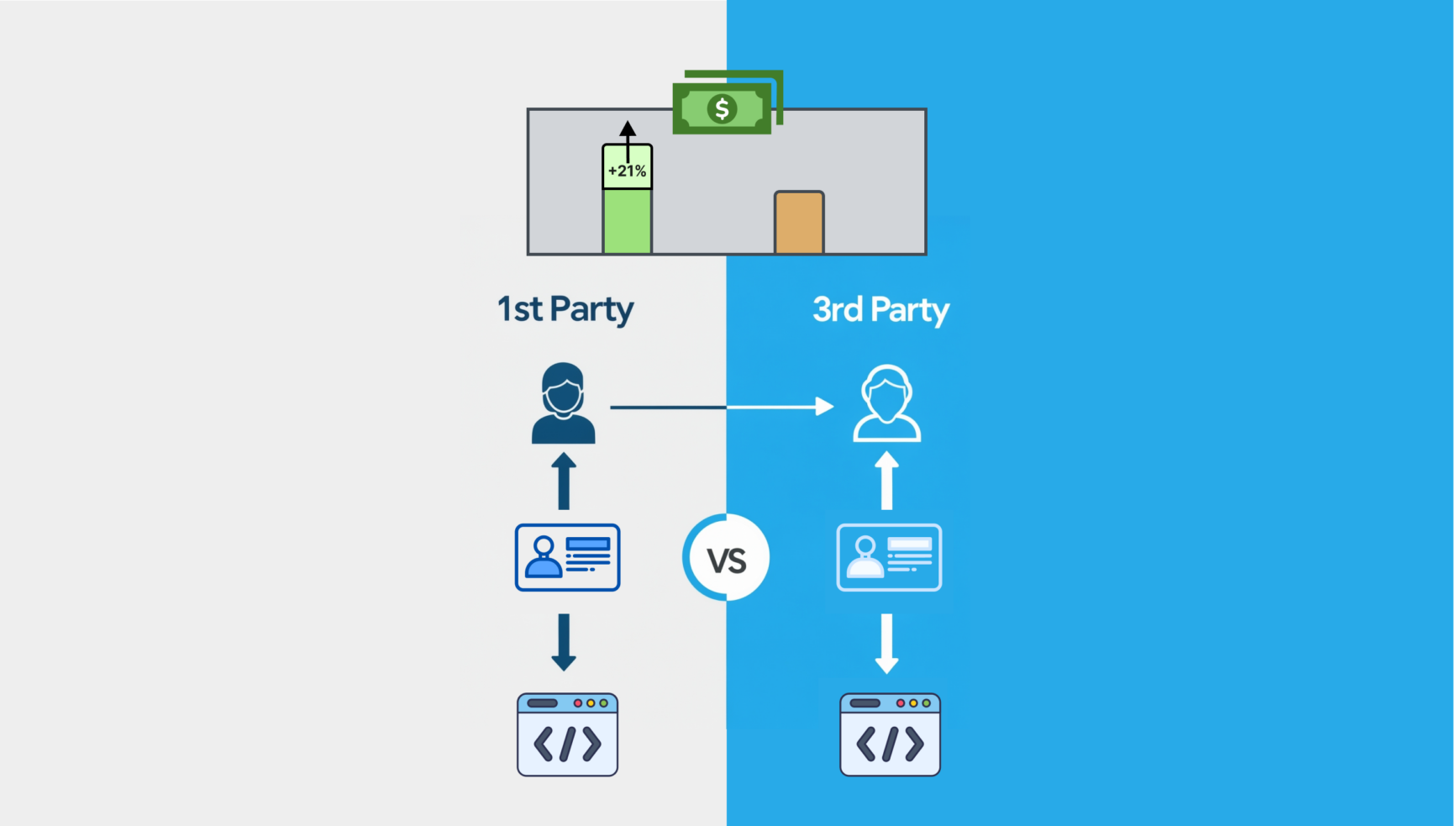
Sites constatant des CPM plus élevés grâce à l'utilisation d'identifiants publicitaires et de solutions de données propriétaires
-

L’édition basée sur Ethereum : les paiements en cryptomonnaie peuvent-ils redéfinir les droits d’auteur ?
-

Constituer l'équipe de monétisation optimale







State of Digital Publishing crée une nouvelle publication et une nouvelle communauté pour les professionnels des médias numériques et de l'édition, dans le domaine des nouveaux médias et des technologies.
ÉTAT DE L'ÉDITION NUMÉRIQUE – COPYRIGHT 2026



