Le nouveau modèle de langage étendu DeepSeek (LLM) de Chine a bouleversé le marché dominé par les États-Unis , en proposant un modèle de chatbot relativement performant à un coût nettement inférieur.
La baisse des coûts de développement et des prix d'abonnement par rapport aux outils d'IA américains a contribué à la perte de 600 milliards de dollars (480 milliards de livres sterling) de capitalisation boursière pour le fabricant américain de puces Nvidia en une seule journée. Nvidia fabrique les puces utilisées pour entraîner la majorité des modèles de langage (LLM), la technologie sous-jacente de ChatGPT et d'autres chatbots. DeepSeek utilise des puces Nvidia H800, moins chères, au lieu des versions haut de gamme plus onéreuses.
OpenAI, le développeur de ChatGPT, aurait dépensé entre 100 millions et 1 milliard de dollars américains pour le développement d'une version très récente de son produit, appelée o1. À l'inverse, DeepSeek a réalisé son entraînement en seulement deux mois pour un coût de 5,6 millions de dollars américains grâce à une série d'innovations ingénieuses.
Mais dans quelle mesure le chatbot IA de DeepSeek, R1, se compare-t-il en termes de performances à d'autres outils d'IA similaires ?
DeepSeek affirme que ses modèles offrent des performances comparables à celles des modèles d'OpenAI, voire supérieures au modèle o1 dans certains tests de référence. Cependant, les tests de compréhension multitâches du langage (MMLU) évaluent les connaissances dans plusieurs domaines à l'aide de questions à choix multiples. Or, de nombreux modèles de langage sont entraînés et optimisés pour ce type de tests, ce qui les rend peu fiables pour évaluer les performances réelles.
Une méthodologie alternative pour l'évaluation objective des modèles de langage (LLM) utilise une série de tests développés par des chercheurs des universités de Cardiff Metropolitan, Bristol et Cardiff, regroupés au sein du Knowledge Observation Group (KOG). Ces tests évaluent la capacité des LLM à imiter le langage et les connaissances humaines grâce à des questions qui requièrent une compréhension humaine implicite. Les tests principaux restent confidentiels afin d'empêcher les entreprises spécialisées dans les LLM d'entraîner leurs modèles à ces tests.
KOG a déployé des tests publics inspirés des travaux de Colin Fraser, data scientist chez Meta , afin d'évaluer DeepSeek par rapport à d'autres LLM. Les résultats suivants ont été observés :
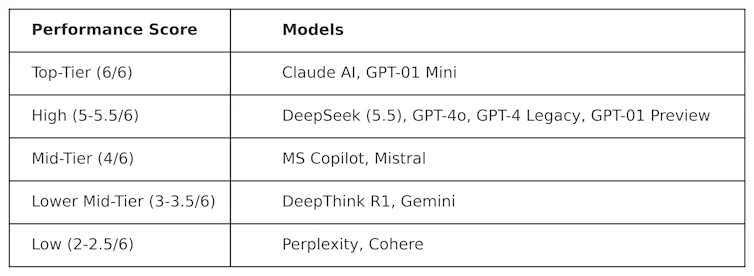
Les tests utilisés pour élaborer ce tableau sont de nature « adversariale ». Autrement dit, ils sont conçus pour être exigeants et pour tester les modèles linéaires logiques (LLM) d'une manière qui ne reflète pas leur conception. Par conséquent, les performances de ces modèles dans ce test sont susceptibles de différer de leurs performances dans les tests de référence classiques.
DeepSeek a obtenu un score de 5,5 sur 6, surpassant ainsi o1 d'OpenAI (son modèle de raisonnement avancé, dit « chaîne de pensée ») ainsi que ChatGPT-4o, la version gratuite de ChatGPT. Cependant, DeepSeek a été légèrement devancé par ClaudeAI d'Anthropic et o1 mini d'OpenAI, qui ont tous deux obtenu la note parfaite de 6/6. Il est intéressant de noter que o1 a obtenu des résultats inférieurs à ceux de son homologue plus compact, o1 mini.
DeepThink R1 – un outil d'IA de raisonnement en chaîne créé par DeepSeek – a obtenu des résultats inférieurs à ceux de DeepSeek avec un score de 3,5.
Ce résultat démontre la compétitivité du chatbot de DeepSeek, qui surpasse déjà les modèles phares d'OpenAI. Il devrait stimuler le développement de DeepSeek, qui dispose désormais d'une base solide. Cependant, cette entreprise technologique chinoise fait face à un problème majeur que les autres LLM n'ont pas : la censure.
Défis liés à la censure
Malgré ses excellentes performances et sa popularité, DeepSeek a fait l'objet de critiques concernant ses réponses aux sujets politiquement sensibles en Chine. Par exemple, les requêtes relatives à la place Tiananmen, à Taïwan, aux musulmans ouïghours et aux mouvements démocratiques reçoivent la réponse : « Désolé, cela dépasse mon champ de compétences actuel. »
Ce problème n'est toutefois pas propre à DeepSeek, et le risque d'influence politique et de censure dans les LLM en général est une préoccupation croissante. L'annonce par Donald Trump du projet Stargate LLM , impliquant OpenAI, Nvidia, Oracle, Microsoft et Arm, alimente également les craintes d'influence politique.
Par ailleurs, la décision récente de Meta d' abandonner la vérification des faits sur Facebook et Instagram suggère une tendance croissante au populisme au détriment de la vérité.
L'arrivée de DeepSeek a profondément bouleversé le marché des logiciels de modélisation de l'apprentissage (LLM). Les entreprises américaines telles qu'OpenAI et Anthropic seront contraintes d'innover pour rester compétitives et rivaliser avec DeepSeek en termes de performances et de coûts.
Le succès de DeepSeek remet déjà en question l'ordre établi, démontrant qu'il est possible de développer des modèles LLM performants sans budgets colossaux. Il met également en lumière les risques de censure des modèles LLM, la propagation de fausses informations et l'importance des évaluations indépendantes.
À mesure que les LLM s'intègrent plus profondément dans la politique et les affaires mondiales, la transparence et la responsabilité seront essentielles pour garantir un avenir sûr, utile et digne de confiance pour les LLM.
Simon Thorne, maître de conférences en informatique et systèmes d'information à l'Université métropolitaine de Cardiff.
Cet article est republié de The Conversation sous licence Creative Commons. Lire l' article original .