

Stemningen rundt generativ AI opplever en kurskorreksjon i kjølvannet av Googles og Microsofts feiltrinn i implementeringen av LLM-er.
Utgivere tar nå tak i de praktiske implikasjonene av et verktøy som kan spytte ut massevis av tekst på et blunk for brukere med svært lite skriveerfaring. Bekymringene øker over en flom av lavkvalitets AI-skrevne historier overfylte innleveringsskrankene. Andre stiller i mellomtiden alvorlige spørsmål om hvor AI får dataene den gjenbruker fra.

Redaktørens merknad: Monetisering i AI-tiden
Stemningen rundt generativ AI opplever en kurskorreksjon i kjølvannet av Googles og Microsofts feiltrinn i implementeringen av LLM-er. Utgivere takler nå de virkelige implikasjonene av et verktøy ..
Oppdatert: 1. desember 2025
Innholdsfortegnelse
Abonner på AI-innsikt
- Trendende pubtech-ressurser
- Gjennomgang av pubtech- og adtech-verktøy
- Verdifulle pubtech-strategier

Relaterte innlegg
-

Tokeniserte aksjonærbelønninger – hva det betyr for finansjournalistikk
-

Slik bygger du ditt eget annonsenettverk: En trinnvis veiledning
-

En historie om hvordan RollerAds' utgiver tjente 60 000 dollar
-

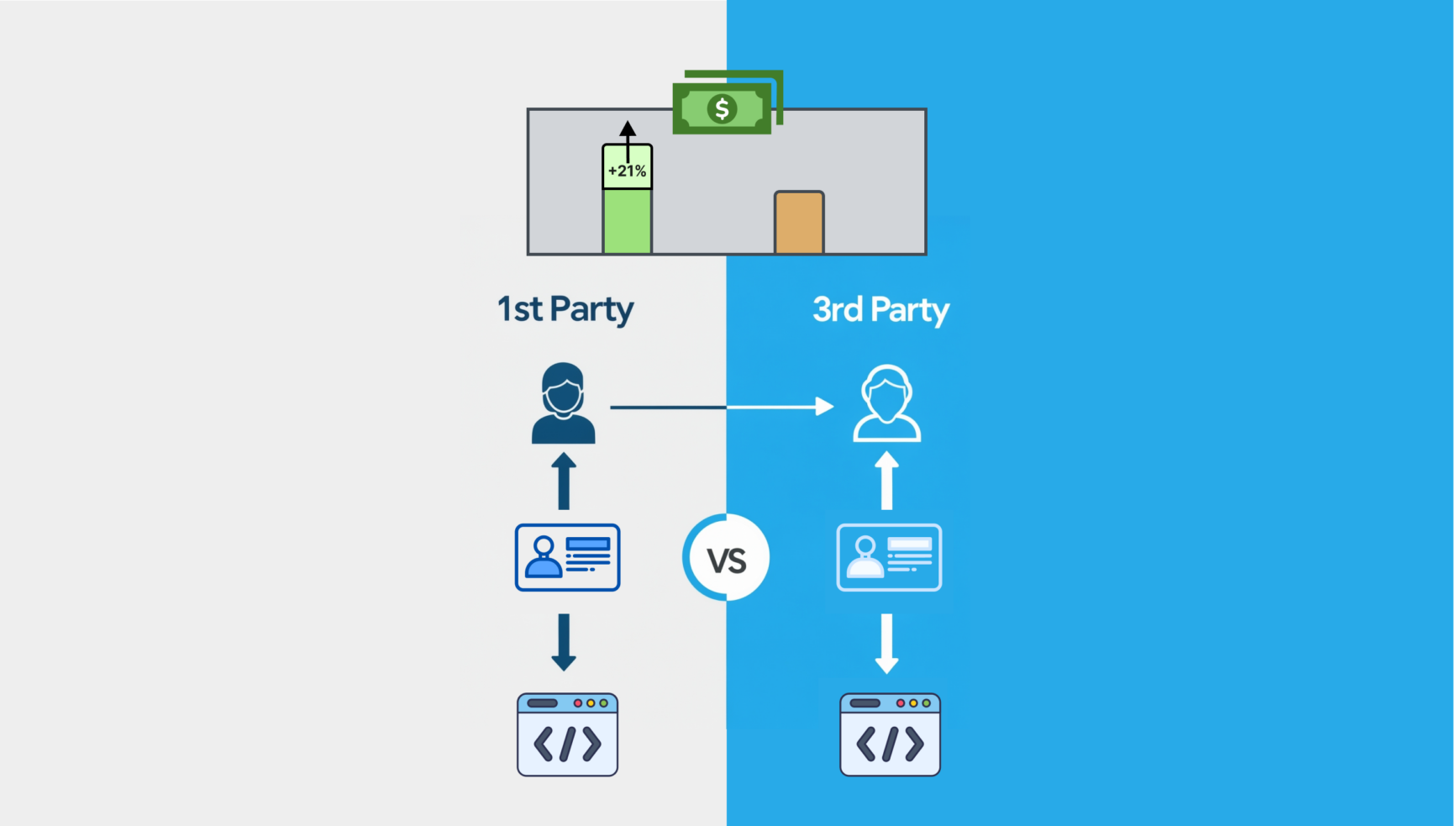
Utgiver brukte førstepartsdata for å tjene penger på fjerde kvartal
-

Nettets største listeeiere vinner mens tradisjonelle nettsteder faller bak
-
Nettsteder som får høyere CPM-er ved bruk av annonse-ID-er og førsteparts dataløsninger
-

Ethereum-drevet publisering: Kan kryptobetalinger omdefinere forfatterroyaltys?
-

Bygge det optimale monetiseringsteamet







State of Digital Publishing skaper en ny publikasjon og et nytt fellesskap for digitale medier og publiseringsfagfolk, innen nye medier og teknologi.
TILSTANDEN FOR DIGITAL PUBLISERING – COPYRIGHT 2026



