Richard Reeves er administrerende direktør i Association of Online Publishers (AOP), en britisk bransjeorganisasjon som representerer digitale publiseringsselskaper.
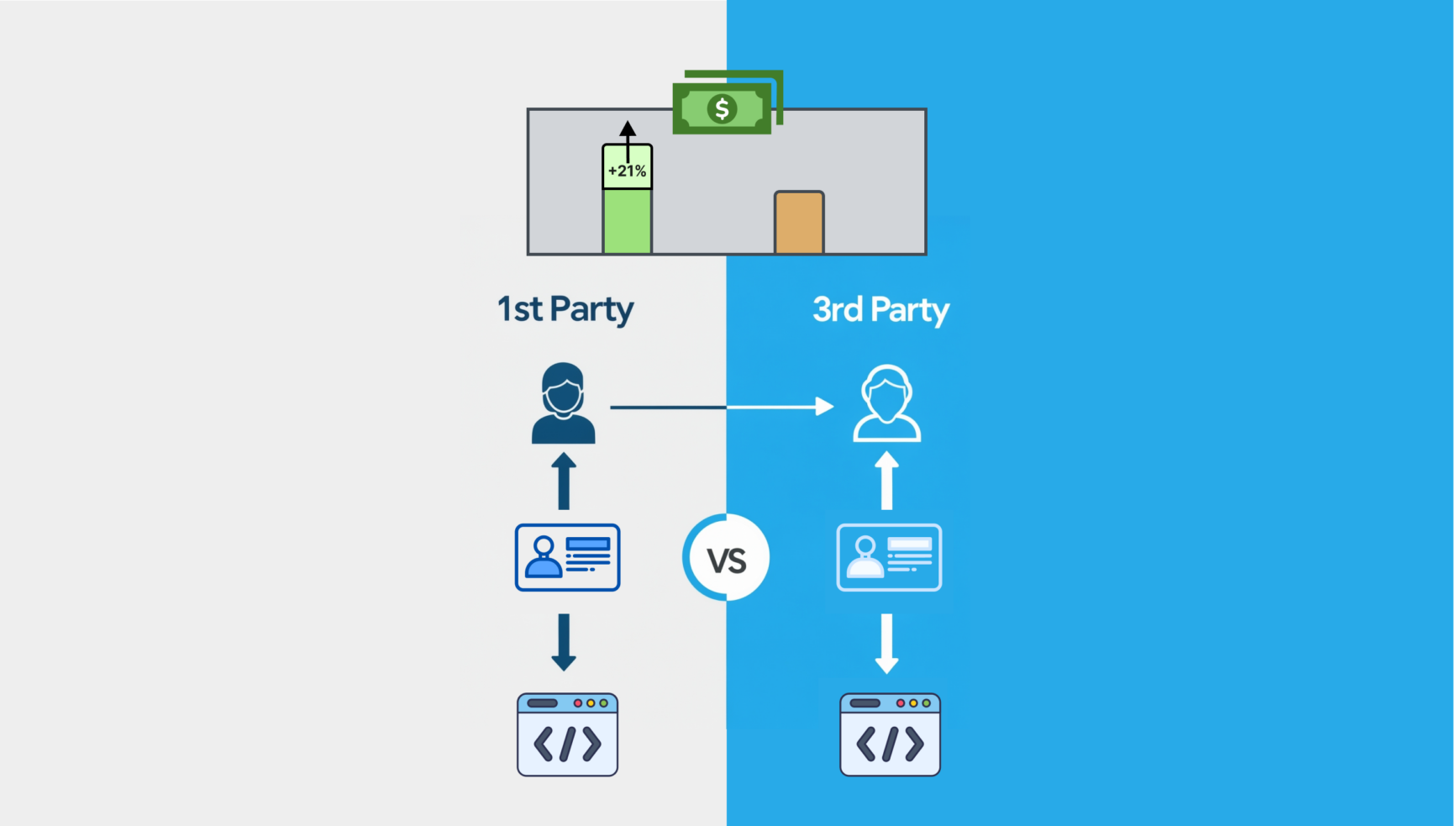
Det er ment at tredjepartsinformasjonskapslene skal være til fordel for utgivere, og de skal være bedre posisjonert til å hente ut større annonseverdi fra førstepartsdataene sine.
Men mellom forberedelsene til den «kakefrie fremtiden», kampen mot Facebook og Google om kompensasjon for deling av nyhetsutdrag og forsøkene på å identifisere de nye risikoene som AI utgjør , er noen utgivere kanskje ikke klar over et annet potensielt problem i horisonten.
Den britiske foreningen for nettpublisører (AOP) publiserte et åpent brev i mars der de advarte publiserings- og reklamebransjen om farene ved uautorisert dataskraping fra leverandører av innholdsverifisering .
Brevet, som ble signert av AOPs administrerende direktør Richard Reeves, argumenterer for at disse leverandørene – enten ved å pakke skjulte tagger inn i autoriserte in-header-wrappers eller ved å bruke crawlere – bygger «kontekstuelle målgruppesegmenter for egen kommersiell vinning».
«Skemmelsesmessig førsteparts datautvinning tilsvarer tyveri av utgiveres immaterielle rettigheter (IP), med negative konsekvenser som strekker seg over utgivere, annonsører og byråer», heter det, før det legges til: «En forpliktelse til at hele bransjen står samlet i å håndtere disse bekymringene, vil bidra til å forsinke – og ideelt sett forhindre – mer radikale, forstyrrende utgivertiltak.»
For å bedre forstå AOPs bekymringer og de potensielle farene for utgivere, kontaktet State of Digital Publishing (SODP)
Hvordan vil innsamlingen av utgivermetadata og artikkeltekst utgjøre en trussel for utgivermiljøet? Ville ikke bedre målgruppeprofiler føre til mer nøyaktig kontekstuell målretting og en mer fokusert kjøpergruppe?
Digitale utgivere ville være de første til å være enige i at det er positivt å tilpasse annonsering tettere til innholdet publikum velger å konsumere. De fleste ser overgangen fra atferdsbasert til kontekstbasert målretting som en viktig del av å bygge sterkere brukerrelasjoner og tillit – og de anerkjenner potensialet i økende kjøperetterspørsel for å drive høyere CPM-er.
Problemet er at de ikke er alene om å utnytte disse fordelene. Leverandører har lenge hatt tilgang til utgiverinnhold for å bekrefte merkevaresikkerhet, men mange går utover dette begrensede formålet; bruker skjulte tagger for å skrape data og bygge kontekstuelle målgruppesegmenter for egen økonomisk vinning.
I tillegg til å bryte tilliten, nekter denne praksisen utgivere den eksklusive retten de burde ha til å tjene penger på sine førstepartsressurser, noe som spiser opp viktig annonseavkastning og de viktige inntektene det genererer.
Hvordan undergraver denne praksisen utgiveres evne til å forbedre brukeropplevelser og annonseinntekter? Kan du utdype hvordan det svekker utgiveres konkurransefortrinn når det gjelder å generere annonseinntekter?
På papiret setter nedgangen i tredjeparts informasjonskapsler utgivere i en sterk posisjon. I tillegg til direkte tilgang til publikum har de rike datalagre som burde bety at de er unikt godt posisjonert til å støtte kompatibel, kontekstsentrert målretting og drive høyere inntekter. Realiteten er imidlertid at med mellomledd som blander seg inn, holder tilbudene deres seg og genererer mindre verdi.
For å illustrere hva jeg mener, la oss se på en analogi jeg ofte bruker – en eplehage med offentlige veier.
Frukthageeiere legger ned betydelige summer, tid og krefter i å dyrke produktene sine. Selv om det kanskje ikke er alvorlig for én turgåer å gå forbi og stjele et eple, er det store problemer når store grupper begynner å komme med store kurver, laste opp og ta epler til markedet. Dyrkeren får ikke tilstrekkelig avkastning på investeringen sin, de kan ikke lenger markedsføre varer som unike, og de kan bli underpriset av selgere med nesten null margin å dekke.
Utgivere bruker enorme ressurser på å produsere kvalitetsinnhold og dyrke nære bånd til publikum, mens noen også har investert tungt i å øke evnen til å lage kontekstuelle segmenter og smi lukrative partnerskap for datadeling.
I likhet med frukthageeiere blir utgivernes evne til å kapitalisere på alt dette harde arbeidet svekket, noe som er spesielt vanskelig i en tid hvor inntektene er truet av økonomisk turbulens. Og det verste er at utgiverne føler seg forpliktet til å holde porten åpen for leverandører, fordi vurdering av merkevaresikkerhet er en viktig faktor for programmatiske kjøpere.
Hvilken lov bryter denne prosessen, og hvordan?
Noen hevder at dette problemet faller innenfor en gråsone av loven, men det korte svaret er at det utgjør tyveri av åndsverk. Som sådan anser jeg det ikke som en gråsone, men snarere et eksempel på at loven – som per design beveger seg sakte – ikke har tatt igjen den raske endringen innen datateknologi. Når den tar igjen, vil spørsmålene fokusere på hvem som eier hvilke eiendeler, og hvem som har rett til å utnytte disse eiendelene for kommersiell vinning.
Selv om artikkeltekst åpenbart er en eid ressurs, gjelder samme status for data knyttet til utgiverens media og interaksjoner på nettstedet, eller i appen. Dette inkluderer sidetitler, beskrivelser og nøkkelord, i tillegg til faktorer som engasjerer publikum, som rullehastighet og skjermretning. Så, enkelt sagt: å samle og utnytte disse dataene uten først å innhente samtykke er å stjele fra utgivere.
Det finnes ingen juridisk gråsone overhodet, og det er i tilfeller der leverandører bryter kontraktene sine med utgivere, hvorav mange eksplisitt begrenser bruken av dataene sine til ikke-kommersielle formål i sine vilkår og betingelser. Vi anbefaler for tiden utgivere å oppdatere sine vilkår og betingelser for å beskytte organisasjonene sine mot uautorisert dataskraping.
Hvor stort problem er dette for kjøpere? Finnes det data som tyder på at leverandører av innholdsverifisering villeder kjøpere?
Å samarbeide med skruppelløse leverandører risikerer å skade kjøpernes omdømme og forbrukernes tillit alvorlig, i tillegg til å kaste en skygge over kampanjenes integritet. Som fremhevet i vårt åpne brev, har merkevarer og byråer begrenset åpenhet om dataenes opprinnelse, noe som betyr at kontekstuelle annonser kan kjøre på uautoriserte og upålitelige data. Mitt spørsmål til byråene er: Kan dere bekrefte at dataene som brukes til å informere kampanjene deres, er samlet inn på legitim måte?
Det nøyaktige omfanget av problemet er vanskelig å tallfeste – og først og fremst, i hvert fall foreløpig, er dette et prinsipielt spørsmål. Bare fordi du kan gjøre noe, betyr det ikke at du bør. I et millionmarked med hundrevis av leverandører, er det svært få som har tatt kontakt for å diskutere utgiveres kompensasjon for databruk.
I stedet fremhever flere børsnoterte selskaper omfattende og presis datautvinning fra utgivere som en av sine viktigste styrker, med lite eller ingen omtale av lisensiering. Som et resultat er et stort antall kjøpere i mørket om hvilke dataprosesser som skjer under overflaten.
Hvordan kan kjøpere oppleve at de bærer mer ansvar for feilbehandling av data? Er dette et juridisk problem?
Leverandører generelt er ikke overraskende fåmælte om dette problemet, men hint fra de som har kommentert signaliserer mulige røde flagg for kjøpere. Spesielt antydningen om at leverandører bare henter ut utgiverdata på forespørsel fra kjøpere har en tydelig preg av å skyve ansvaret over på andre. Selv om det er for tidlig å si om slik skyldflytting vil omfatte juridisk ansvar, må kjøpere begynne å vurdere denne risikoen nøye.
Det er også viktig å understreke potensialet for at datakvalitetsproblemer kan utvikle seg raskt hvis det ikke iverksettes tiltak snart. Jo flere leverandører som får lov til å operere med tilsynelatende straffrihet, desto mer sannsynlig er det at vi vil se ytterligere vekst i antall kontekstuelle leverandører som bruker uautoriserte robotsøkeprogrammer. Som kontraktsinnehavere har kjøpere makt til å forhindre eskalering og påvirke leverandører ved å kreve tydelig bevis på offisiell lisens og tillatelse til å samle inn data. Tiden er imidlertid knapp.
Påbyr medlemskap i Trustworthy Accountability Group (TAG) bruk av gruppens merkevaresikkerhetssertifisering? Finnes det et system for å håndtere brudd?
Grunnleggende TAG-medlemskap krever ikke sertifisering, men platinamedlemskap krever det, og enhver organisasjon som viser et merkevaresikkerhetssertifiseringsstempel må absolutt overholde retningslinjene.
Den nyeste oppdateringen av disse retningslinjene – gjeldende fra 1. januar 2023 – angir klare definisjoner rundt utgiveres datasøknader og skiller spesifikt mellom legitim og ulovlig databruk. TAG har bekreftet at organisasjoner som bryter denne nye klausulen ikke vil bli sertifisert.
I tillegg til TAG IAB Gold Standard sertifisering av merkevaresikkerhet, noe som legger til et ekstra lag med akkreditering som vil være forbudt for leverandører som bruker utgiverdata utenfor kontraktsfestede vilkår.
Når det gjelder håndheving, tildeles merkevaresikkerhetssertifisering årlig. Selv om jeg selvfølgelig skulle ønske at fremdriften gikk raskere, legger dette et betydelig tidspress for alle nåværende sertifiserte selskaper for å sikre full samsvar. Hvis det viser seg at de bryter retningslinjene ved neste revisjon, vil de miste sertifiseringen. Det blir interessant å se hvordan dette håndheves, og hvem som mister stempelet sitt, i løpet av de neste 12 månedene.
Kan du utdype hva slags «radikale, disruptive forlagstiltak» som kan bli iverksatt dersom forlagsbransjens bekymringer ikke blir imøtekommet?
Det er viktig å først gjenta at forstyrrelse ikke er «plan A»; vårt hovedhåp er å finne en løsning gjennom samarbeid. Andre veier vil bare bli vurdert hvis samarbeidet mislykkes.
Utgivere har rett til å beskytte sin immaterielle rettigheter, og noen kan bestemme seg for å gjøre det gjennom avgjørende tiltak. Hvordan det ser ut vil variere, men som nevnt i det åpne brevet, finnes det juridiske presedenser for saker mot selskaper som bruker data uten samtykke, som for eksempel Getty Images vs. Stability AI .
Utgivere på tvers av det digitale rommet erkjenner imidlertid at dette problemet ennå ikke har fått bred oppmerksomhet, og det er derfor våre nåværende mål fokuserer på å øke bevisstheten og oppmuntre til konstruktiv diskusjon.
Alle innbyggere i økosystemet må forstå de negative effektene av misbruk av data, og å komme sammen er den beste måten å finne en gjensidig fordelaktig – og rettferdig – vei videre.