El nuevo modelo de lenguaje grande (LLM) DeepSeek de China ha revolucionado el mercado dominado por Estados Unidos , ofreciendo un modelo de chatbot de rendimiento relativamente alto a un costo significativamente menor.
El menor coste de desarrollo y los precios de suscripción más bajos en comparación con las herramientas de IA estadounidenses contribuyeron a que el fabricante estadounidense de chips Nvidia perdiera 600 000 millones de dólares (480 000 millones de libras) en valor de mercado en un solo día. Nvidia fabrica los chips informáticos utilizados para entrenar la mayoría de los LLM, la tecnología subyacente de ChatGPT y otros chatbots de IA. DeepSeek utiliza chips Nvidia H800 más económicos en lugar de las versiones de vanguardia más caras.
Según informes, OpenAI, desarrollador de ChatGPT, invirtió entre 100 y 1000 millones de dólares en el desarrollo de una versión muy reciente de su producto, o1. En cambio, DeepSeek completó su entrenamiento en tan solo dos meses, con un coste de 5,6 millones de dólares, gracias a una serie de ingeniosas innovaciones.
Pero, ¿qué tan bien se compara el chatbot de IA de DeepSeek, R1, con otras herramientas de IA similares en términos de rendimiento?
DeepSeek afirma que sus modelos tienen un rendimiento comparable al de OpenAI, incluso superando al modelo o1 en ciertas pruebas de referencia. Sin embargo, las pruebas de referencia que utilizan la Comprensión Masiva del Lenguaje Multitarea (MMLU) evalúan el conocimiento en múltiples materias mediante preguntas de opción múltiple. Muchos LLM están entrenados y optimizados para estas pruebas, lo que los hace poco fiables como indicadores reales del rendimiento.
Una metodología alternativa para la evaluación objetiva de los LLM utiliza un conjunto de pruebas desarrolladas por investigadores de las universidades de Cardiff Metropolitan, Bristol y Cardiff, conocidas colectivamente como el Grupo de Observación del Conocimiento (KOG). Estas pruebas evalúan la capacidad de los LLM para imitar el lenguaje y el conocimiento humanos mediante preguntas que requieren comprensión humana implícita para responder. Las pruebas principales se mantienen en secreto para evitar que las empresas de LLM entrenen sus modelos para estas pruebas.
KOG implementó pruebas públicas inspiradas en el trabajo de Colin Fraser, científico de datos de Meta , para evaluar DeepSeek frente a otros LLM. Se observaron los siguientes resultados:
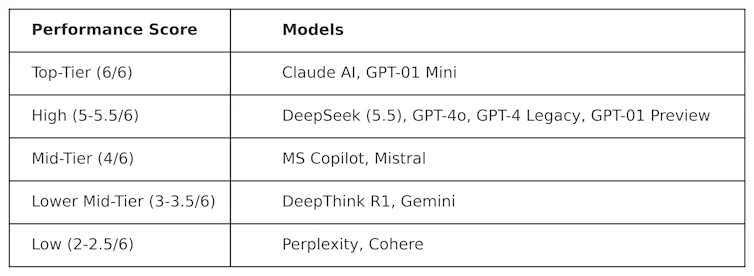
Las pruebas utilizadas para generar esta tabla son de naturaleza adversarial. En otras palabras, están diseñadas para ser rigurosas y para evaluar los LLM de una manera que no se ajusta a su diseño. Esto significa que el rendimiento de estos modelos en esta prueba probablemente sea diferente al de las pruebas de referencia convencionales.
DeepSeek obtuvo una puntuación de 5,5 sobre 6, superando a o1 de OpenAI (su modelo de razonamiento avanzado, conocido como "cadena de pensamiento"), así como a ChatGPT-4o, la versión gratuita de ChatGPT. Sin embargo, DeepSeek fue ligeramente superado por ClaudeAI de Anthropic y o1 mini de OpenAI, ambos con una puntuación perfecta de 6/6. Es interesante que o1 tuviera un rendimiento inferior al de su homólogo más pequeño, o1 mini.
DeepThink R1, una herramienta de inteligencia artificial de cadena de pensamiento creada por DeepSeek, tuvo un rendimiento inferior en comparación con DeepSeek, con una puntuación de 3,5.
Este resultado demuestra la competitividad del chatbot de DeepSeek, superando a los modelos estrella de OpenAI. Es probable que impulse un mayor desarrollo de DeepSeek, que ahora cuenta con una base sólida sobre la que construir. Sin embargo, la empresa tecnológica china tiene un grave problema que los demás LLM no tienen: la censura.
Desafíos de la censura
A pesar de su excelente rendimiento y popularidad, DeepSeek ha recibido críticas por sus respuestas a temas políticamente sensibles en China. Por ejemplo, las solicitudes relacionadas con la Plaza de Tiananmén, Taiwán, los musulmanes uigures y los movimientos democráticos reciben la respuesta: "Lo siento, eso excede mi alcance actual"
Pero este problema no es necesariamente exclusivo de DeepSeek, y la posibilidad de influencia política y censura en los LLM en general es una preocupación creciente. El anuncio del proyecto Stargate LLM , con un presupuesto de 500 000 millones de dólares, en el que participan OpenAI, Nvidia, Oracle, Microsoft y Arm, también genera temores de influencia política.
Además, la reciente decisión de Meta de abandonar la verificación de datos en Facebook e Instagram sugiere una tendencia creciente hacia el populismo en detrimento de la veracidad.
La llegada de DeepSeek ha provocado una grave disrupción en el mercado LLM. Empresas estadounidenses como OpenAI y Anthropic se verán obligadas a innovar sus productos para mantener su relevancia y equiparar su rendimiento y coste.
El éxito de DeepSeek ya está desafiando el statu quo, demostrando que se pueden desarrollar modelos LLM de alto rendimiento sin presupuestos millonarios. También destaca los riesgos de la censura en los LLM, la propagación de desinformación y la importancia de las evaluaciones independientes.
A medida que los LLM se integran cada vez más profundamente en la política y los negocios globales, la transparencia y la rendición de cuentas serán esenciales para garantizar que el futuro de los LLM sea seguro, útil y confiable.
Simon Thorne, profesor titular de Informática y Sistemas de Información, Universidad Metropolitana de Cardiff.
Este artículo se republica de The Conversation bajo una licencia Creative Commons. Lea el artículo original .