O novo modelo de linguagem DeepSeek Large Language Model (LLM) da China revolucionou o mercado dominado pelos EUA , oferecendo um modelo de chatbot com desempenho relativamente alto a um custo significativamente menor.
O custo reduzido de desenvolvimento e os preços de assinatura mais baixos em comparação com as ferramentas de IA americanas contribuíram para que a fabricante de chips americana Nvidia perdesse US$ 600 bilhões (£ 480 bilhões) em valor de mercado em apenas um dia. A Nvidia fabrica os chips usados para treinar a maioria dos LLMs (Modelos de Aprendizagem Baseados em Lógica), a tecnologia subjacente usada no ChatGPT e em outros chatbots de IA. O DeepSeek usa chips Nvidia H800 mais baratos em vez das versões de última geração mais caras.
A OpenAI, desenvolvedora do ChatGPT, teria gasto entre US$ 100 milhões e US$ 1 bilhão no desenvolvimento de uma versão muito recente de seu produto, chamada o1. Em contraste, a DeepSeek concluiu seu treinamento em apenas dois meses, a um custo de US$ 5,6 milhões, utilizando uma série de inovações inteligentes.
Mas, afinal, qual é o desempenho do chatbot de IA da DeepSeek, o R1, em comparação com outras ferramentas de IA semelhantes?
A DeepSeek afirma que seus modelos têm desempenho comparável aos da OpenAI, chegando a superar o modelo o1 em alguns testes de benchmark. No entanto, benchmarks que utilizam testes de Compreensão de Linguagem Multitarefa Massiva (MMLU) avaliam o conhecimento em diversas áreas por meio de questões de múltipla escolha. Muitos modelos de linguagem são treinados e otimizados para esses testes, o que os torna indicadores pouco confiáveis de desempenho no mundo real.
Uma metodologia alternativa para a avaliação objetiva de LLMs utiliza um conjunto de testes desenvolvidos por pesquisadores das universidades de Cardiff Metropolitan, Bristol e Cardiff – conhecidos coletivamente como Grupo de Observação do Conhecimento (KOG). Esses testes avaliam a capacidade dos LLMs de imitar a linguagem e o conhecimento humanos por meio de perguntas que exigem compreensão humana implícita para serem respondidas. Os testes principais são mantidos em segredo para evitar que as empresas de LLM treinem seus modelos para esses testes.
A KOG implementou testes públicos inspirados no trabalho de Colin Fraser, cientista de dados da Meta , para avaliar o DeepSeek em comparação com outros modelos de aprendizado de máquina. Os seguintes resultados foram observados:
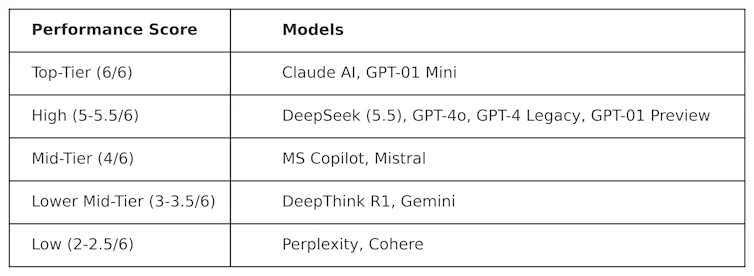
Os testes usados para gerar esta tabela são de natureza "adversarial". Em outras palavras, eles são projetados para serem "difíceis" e para testar os LLMs de uma maneira que não seja favorável à sua concepção original. Isso significa que o desempenho desses modelos neste teste provavelmente será diferente do seu desempenho em testes de benchmark convencionais.
O DeepSeek obteve uma pontuação de 5,5 em 6, superando o o1 da OpenAI – seu modelo de raciocínio avançado (conhecido como "cadeia de pensamento") – bem como o ChatGPT-4o, a versão gratuita do ChatGPT. No entanto, o DeepSeek teve um desempenho ligeiramente inferior ao do ClaudeAI da Anthropic e ao do o1 mini da OpenAI, ambos com pontuação máxima de 6/6. É interessante notar que o o1 teve um desempenho inferior ao de sua contraparte "menor", o o1 mini.
O DeepThink R1 – uma ferramenta de IA de raciocínio lógico criada pela DeepSeek – teve um desempenho inferior em comparação com o DeepSeek, obtendo uma pontuação de 3,5.
Este resultado demonstra o quão competitivo o chatbot da DeepSeek já é, superando os principais modelos da OpenAI. É provável que isso impulsione ainda mais o desenvolvimento da DeepSeek, que agora possui uma base sólida para construir. No entanto, a empresa chinesa de tecnologia enfrenta um problema sério que as outras plataformas de aprendizado de máquina não têm: a censura.
Desafios da censura
Apesar de seu bom desempenho e popularidade, o DeepSeek tem enfrentado críticas por suas respostas a tópicos politicamente sensíveis na China. Por exemplo, perguntas relacionadas à Praça Tiananmen, Taiwan, muçulmanos uigures e movimentos democráticos recebem a resposta: "Desculpe, isso está além do meu escopo atual."
Mas esse problema não é necessariamente exclusivo do DeepSeek, e o potencial de influência política e censura em LLMs de forma mais geral é uma preocupação crescente. O anúncio do projeto Stargate LLM , envolvendo OpenAI, Nvidia, Oracle, Microsoft e Arm, também aumenta os temores de influência política.
Além disso, a recente decisão da Meta de abandonar a verificação de fatos no Facebook e no Instagram sugere uma tendência crescente de populismo em detrimento da veracidade.
A chegada do DeepSeek causou sérias mudanças no mercado de aprendizado de máquina. Empresas americanas como a OpenAI e a Anthropic serão obrigadas a inovar seus produtos para se manterem relevantes e competirem em desempenho e custo.
O sucesso da DeepSeek já está desafiando o status quo, demonstrando que modelos de aprendizado de máquina de alto desempenho podem ser desenvolvidos sem orçamentos bilionários. Também destaca os riscos da censura em aprendizado de máquina, a disseminação de desinformação e a importância de avaliações independentes.
À medida que os mestrados em direito se tornam mais integrados à política e aos negócios globais, a transparência e a responsabilidade serão essenciais para garantir que o futuro dos mestrados em direito seja seguro, útil e confiável.
Simon Thorne, Professor Sênior de Computação e Sistemas de Informação, Universidade Metropolitana de Cardiff.
Este artigo foi republicado do The Conversation sob uma licença Creative Commons. Leia o artigo original .