

A opinião pública sobre IA generativa está passando por uma correção de rumo após os erros cometidos pelo Google e pela Microsoft na implementação de LLMs (Learning Learning Machines).
As editoras agora enfrentam as implicações práticas de uma ferramenta capaz de gerar grandes quantidades de texto num piscar de olhos para usuários com pouca experiência em escrita. A preocupação aumenta em relação a.. Enxurrada de histórias de baixa qualidade escritas por IA inundando as mesas de submissão. Outros, entretanto, estão fazendo perguntas sérias sobre de onde a IA está obtendo os dados que está reutilizando.

Nota do editor: Monetização na era da IA
A opinião pública sobre IA generativa está passando por uma correção de rumo após os erros do Google e da Microsoft na implementação de LLMs (Learning Learning Models). As editoras agora estão lidando com as implicações práticas dessa ferramenta…
Atualizado em: 1 de dezembro de 2025
Assine insights de IA
- Recursos de tecnologia para pubs em alta
- Análise de ferramentas de pubtech e adtech
- Estratégias valiosas de tecnologia para pubs

Posts relacionados
-

Recompensas Tokenizadas para Acionistas – O Que Isso Significa para o Jornalismo Financeiro
-

Como Criar Sua Própria Rede de Anúncios: Um Guia Passo a Passo
-

A história de como o editor da RollerAds faturou US$ 60.000
-

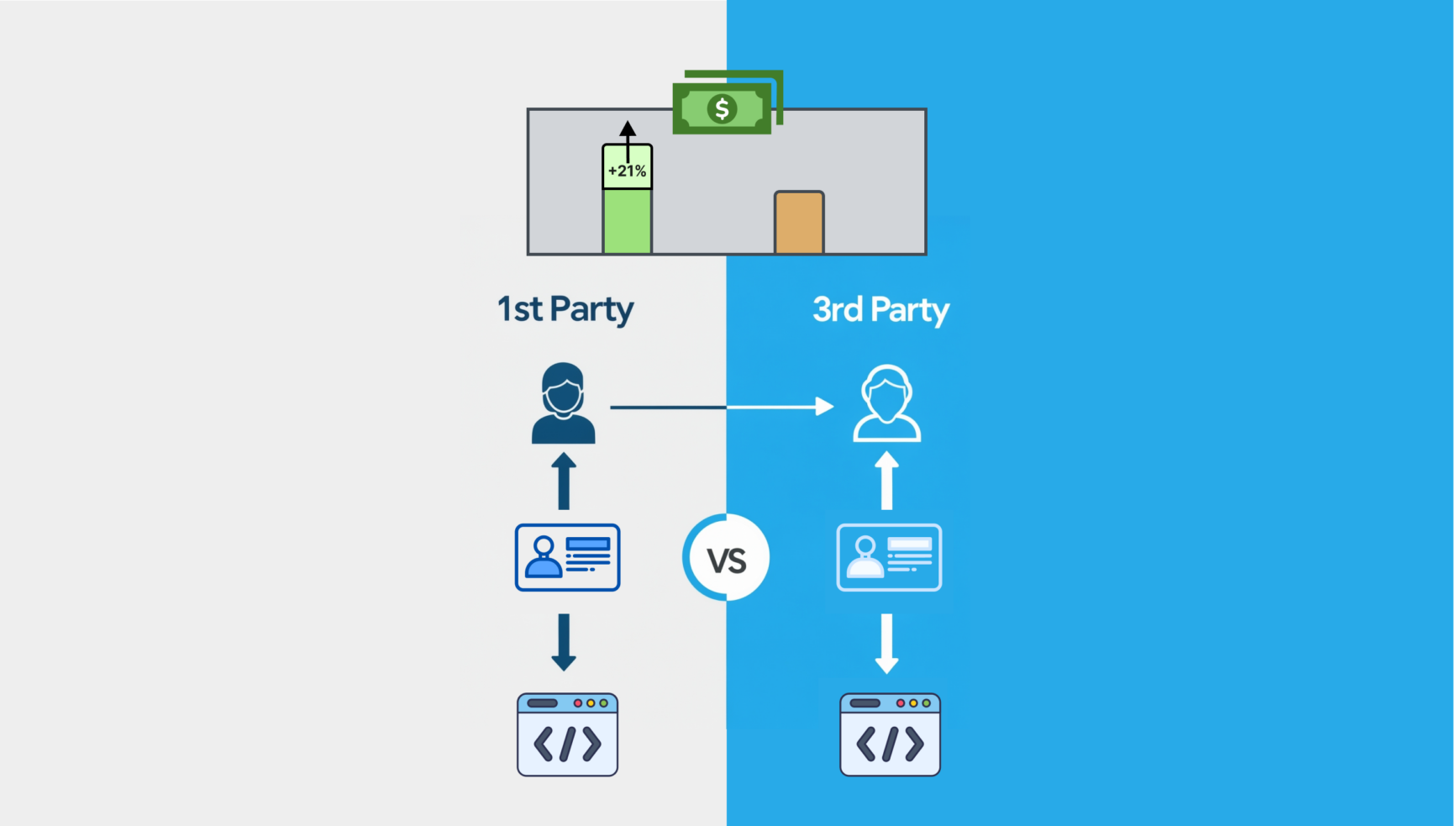
Editora utilizou dados primários para lucrar no 4º trimestre
-

Os maiores proprietários de listas da web estão vencendo, enquanto os sites tradicionais ficam para trás
-
Sites que utilizam IDs de anúncios e soluções de dados primários estão obtendo CPMs mais altos
-

Publicação impulsionada por Ethereum: os pagamentos em criptomoedas podem redefinir os direitos autorais?
-

Construindo a Equipe de Monetização Ideal







State of Digital Publishing está criando uma nova publicação e comunidade para profissionais de mídia digital e editoração, nas áreas de novas mídias e tecnologia.
ESTADO DA PUBLICAÇÃO DIGITAL – DIREITOS AUTORAIS 2026



