Model Bahasa Besar (LLM) DeepSeek baharu China telah mengganggu pasaran yang didominasi AS , menawarkan model chatbot berprestasi tinggi yang agak tinggi pada kos yang jauh lebih rendah.
Kos pembangunan yang berkurangan dan harga langganan yang lebih rendah berbanding alat AI AS menyumbang kepada pengeluar cip Amerika, Nvidia, kerugian nilai pasaran sebanyak AS$600 bilion (£480 bilion) dalam tempoh satu hari. Nvidia menghasilkan cip komputer yang digunakan untuk melatih kebanyakan LLM, teknologi asas yang digunakan dalam ChatGPT dan chatbot AI lain. DeepSeek menggunakan cip Nvidia H800 yang lebih murah berbanding versi canggih yang lebih mahal.
Pembangun ChatGPT, OpenAI, dilaporkan membelanjakan antara US$100 juta dan US$1 bilion untuk pembangunan versi produknya yang sangat terkini yang dipanggil o1. Sebaliknya, DeepSeek menyelesaikan latihannya hanya dalam masa dua bulan dengan kos US$5.6 juta menggunakan beberapa inovasi pintar.
Tetapi sejauh manakah chatbot AI DeepSeek, R1, dibandingkan dengan alat AI lain yang serupa dari segi prestasi?
DeepSeek mendakwa modelnya berprestasi setanding dengan tawaran OpenAI, malah melebihi model o1 dalam ujian penanda aras tertentu. Walau bagaimanapun, penanda aras yang menggunakan ujian Pemahaman Bahasa Pelbagai Tugas Besar-besaran (MMLU) menilai pengetahuan merentasi pelbagai subjek menggunakan soalan aneka pilihan. Banyak LLM dilatih dan dioptimumkan untuk ujian sedemikian, menjadikannya tidak boleh dipercayai sebagai penunjuk sebenar prestasi dunia sebenar.
Satu metodologi alternatif untuk penilaian objektif LLM menggunakan satu set ujian yang dibangunkan oleh penyelidik di universiti Cardiff Metropolitan, Bristol dan Cardiff – yang dikenali secara kolektif sebagai Kumpulan Pemerhatian Pengetahuan (KOG). Ujian ini menyiasat keupayaan LLM untuk meniru bahasa dan pengetahuan manusia melalui soalan yang memerlukan pemahaman manusia yang tersirat untuk dijawab. Ujian teras dirahsiakan, bagi mengelakkan syarikat LLM melatih model mereka untuk ujian ini.
KOG telah menggunakan ujian awam yang diinspirasikan oleh kerja Colin Fraser, seorang saintis data di Meta , untuk menilai DeepSeek berbanding LLM lain. Keputusan berikut telah diperhatikan:
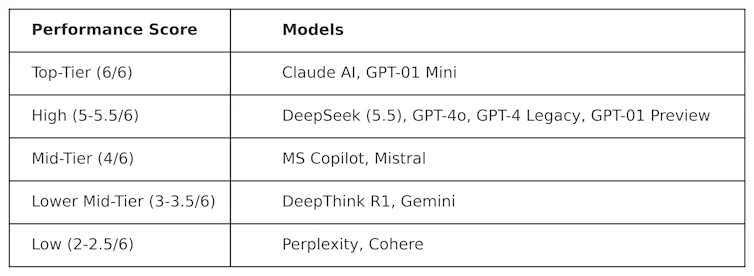
Ujian yang digunakan untuk menghasilkan jadual ini bersifat "adversarial". Dalam erti kata lain, ia direka bentuk untuk menjadi "sukar" dan untuk menguji LLM dengan cara yang tidak bersimpati dengan cara ia direka bentuk. Ini bermakna prestasi model-model ini dalam ujian ini mungkin berbeza dengan prestasinya dalam ujian penanda aras arus perdana.
DeepSeek mendapat markah 5.5 daripada 6, mengatasi o1 OpenAI – model penaakulan lanjutannya (dikenali sebagai “rantaian pemikiran”) – serta ChatGPT-4o, versi percuma ChatGPT. Tetapi Deepseek sedikit diatasi oleh ClaudeAI Anthropic dan o1 mini OpenAI, kedua-duanya mendapat markah sempurna 6/6. Menariknya, o1 berprestasi rendah berbanding rakan sejawatnya yang “lebih kecil”, o1 mini.
DeepThink R1 – alat AI rantaian pemikiran yang dibuat oleh DeepSeek – berprestasi rendah berbanding DeepSeek dengan skor 3.5.
Keputusan ini menunjukkan betapa kompetitifnya chatbot DeepSeek, mengatasi model utama OpenAI. Ia berkemungkinan akan memacu pembangunan selanjutnya untuk DeepSeek, yang kini mempunyai asas yang kukuh untuk dibina. Walau bagaimanapun, syarikat teknologi China itu mempunyai satu masalah serius yang tidak dihadapi oleh LLM lain: penapisan.
Cabaran penapisan
Walaupun prestasi dan popularitinya yang kukuh, DeepSeek telah menghadapi kritikan atas responsnya terhadap topik sensitif politik di China. Contohnya, gesaan yang berkaitan dengan Dataran Tiananmen, Taiwan, Muslim Uyghur dan gerakan demokratik disambut dengan respons: "Maaf, itu di luar skop saya sekarang."
Tetapi isu ini tidak semestinya unik kepada DeepSeek, dan potensi pengaruh politik dan penapisan dalam LLM secara amnya merupakan kebimbangan yang semakin meningkat. Pengumuman projek Stargate LLM , yang melibatkan OpenAI, Nvidia, Oracle, Microsoft dan Arm, turut menimbulkan kebimbangan tentang pengaruh politik.
Di samping itu, keputusan Meta baru-baru ini untuk menghentikan semakan fakta di Facebook dan Instagram menunjukkan trend yang semakin meningkat ke arah populisme berbanding kebenaran.
Ketibaan DeepSeek telah menyebabkan gangguan serius kepada pasaran LLM. Syarikat AS seperti OpenAI dan Anthropic akan terpaksa menginovasi produk mereka untuk mengekalkan kerelevanan dan sepadan dengan prestasi serta kosnya.
Kejayaan DeepSeek sudah mencabar status quo, menunjukkan bahawa model LLM berprestasi tinggi boleh dibangunkan tanpa bajet berbilion dolar. Ia juga mengetengahkan risiko penapisan LLM, penyebaran maklumat salah dan mengapa penilaian bebas penting.
Memandangkan LLM semakin terlibat dalam politik dan perniagaan global, ketelusan dan akauntabiliti adalah penting untuk memastikan masa depan LLM selamat, berguna dan boleh dipercayai.
Simon Thorne, Pensyarah Kanan dalam Pengkomputeran dan Sistem Maklumat, Universiti Metropolitan Cardiff
Artikel ini diterbitkan semula daripada The Conversation di bawah lesen Creative Commons. Baca artikel asal .