أحدث نموذج اللغة الكبير الجديد DeepSeek (LLM) الصيني ثورة في السوق الذي تهيمن عليه الولايات المتحدة ، حيث يقدم نموذجًا عالي الأداء نسبيًا لروبوتات الدردشة بتكلفة أقل بكثير.
ساهم انخفاض تكلفة التطوير وأسعار الاشتراك مقارنةً بأدوات الذكاء الاصطناعي الأمريكية في خسارة شركة إنفيديا الأمريكية لصناعة الرقائق الإلكترونية 600 مليار دولار أمريكي (480 مليار جنيه إسترليني) من قيمتها السوقية في يوم واحد. تُصنّع إنفيديا رقائق الكمبيوتر المستخدمة في تدريب غالبية نماذج التعلم الآلي، وهي التقنية الأساسية المستخدمة في ChatGPT وغيرها من روبوتات الدردشة المدعومة بالذكاء الاصطناعي. يستخدم DeepSeek رقائق إنفيديا H800 الأرخص ثمناً بدلاً من الإصدارات الأحدث والأكثر تكلفة.
أفادت التقارير أن شركة OpenAI، مطورة برنامج ChatGPT، أنفقت ما بين 100 مليون دولار أمريكي ومليار دولار أمريكي على تطوير نسخة حديثة جداً من منتجها المسمى o1. في المقابل، أنجزت شركة DeepSeek تدريبها في شهرين فقط بتكلفة 5.6 مليون دولار أمريكي باستخدام سلسلة من الابتكارات الذكية.
لكن ما مدى جودة أداء روبوت الدردشة المدعوم بالذكاء الاصطناعي من DeepSeek، R1، مقارنةً بأدوات الذكاء الاصطناعي الأخرى المماثلة؟
تدّعي شركة DeepSeek أن نماذجها تُقدّم أداءً مماثلاً لعروض OpenAI، بل وتتفوق على نموذج o1 في بعض اختبارات الأداء. مع ذلك، فإن اختبارات الأداء التي تستخدم فهم اللغة متعدد المهام على نطاق واسع (MMLU) تُقيّم المعرفة عبر مواضيع متعددة باستخدام أسئلة الاختيار من متعدد. يتم تدريب العديد من نماذج اللغة وتحسينها خصيصًا لمثل هذه الاختبارات، مما يجعلها غير موثوقة كمؤشرات حقيقية للأداء في الواقع العملي.
تعتمد منهجية بديلة للتقييم الموضوعي لبرامج الماجستير في القانون على مجموعة من الاختبارات التي طورها باحثون من جامعات كارديف متروبوليتان وبريستول وكارديف، والمعروفة مجتمعة باسم "مجموعة مراقبة المعرفة" (KOG). تختبر هذه الاختبارات قدرة برامج الماجستير في القانون على محاكاة اللغة والمعرفة البشرية من خلال أسئلة تتطلب فهمًا ضمنيًا للبشر للإجابة عليها. وتُحفظ الاختبارات الأساسية سريةً لتجنب قيام شركات برامج الماجستير في القانون بتدريب نماذجها عليها.
أجرت شركة KOG اختبارات عامة مستوحاة من عمل كولين فريزر، عالم البيانات في شركة Meta ، لتقييم DeepSeek مقارنةً بنماذج التعلم الآلي الأخرى. وقد لوحظت النتائج التالية:
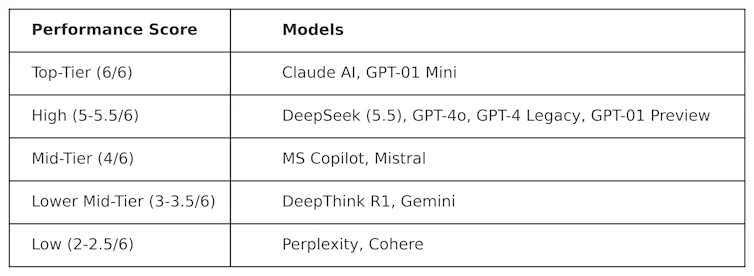
تُعتبر الاختبارات المستخدمة في إعداد هذا الجدول "مُنافسة" بطبيعتها. بمعنى آخر، صُممت هذه الاختبارات لتكون "صعبة" ولتختبر نماذج الانحدار الخطي بطريقة لا تتوافق مع تصميمها الأصلي. وهذا يعني أن أداء هذه النماذج في هذا الاختبار من المرجح أن يختلف عن أدائها في اختبارات القياس المعيارية الشائعة.
حصل DeepSeek على 5.5 من 6، متفوقًا على o1 من OpenAI - نموذج الاستدلال المتقدم (المعروف باسم "سلسلة الأفكار") - بالإضافة إلى ChatGPT-4o، النسخة المجانية من ChatGPT. لكن أداء DeepSeek كان أقل بقليل من ClaudeAI من Anthropic و o1 mini من OpenAI، اللذين حصلا على العلامة الكاملة 6/6. ومن المثير للاهتمام أن أداء o1 كان أقل من نظيره "الأصغر"، o1 mini.
DeepThink R1 - وهي أداة ذكاء اصطناعي لسلسلة الأفكار من صنع DeepSeek - كان أداؤها أقل من أداء DeepSeek حيث حصلت على درجة 3.5.
تُظهر هذه النتيجة مدى تنافسية روبوت الدردشة الخاص بشركة DeepSeek، متفوقًا على نماذج OpenAI الرائدة. ومن المرجح أن يحفز هذا المزيد من التطوير لشركة DeepSeek، التي باتت تمتلك الآن أساسًا متينًا للبناء عليه. مع ذلك، تواجه الشركة الصينية مشكلة خطيرة لا تواجهها نماذج التعلم الآلي الأخرى: الرقابة.
تحديات الرقابة
على الرغم من أدائه القوي وشعبيته، واجه تطبيق DeepSeek انتقادات بسبب ردوده على المواضيع الحساسة سياسياً في الصين. فعلى سبيل المثال، عند طرح أسئلة تتعلق بميدان تيانانمين، أو تايوان، أو مسلمي الأويغور، أو الحركات الديمقراطية، يُقابل الرد التالي: "معذرةً، هذا خارج نطاق اختصاصي الحالي"
لكن هذه المشكلة لا تقتصر بالضرورة على شركة DeepSeek، بل إن احتمالية التأثير السياسي والرقابة في برامج التعلم الآلي بشكل عام تُثير قلقًا متزايدًا. كما أن إعلان دونالد ترامب عن مشروع Stargate للتعلم الآلي ، والذي يضم شركات OpenAI وNvidia وOracle وMicrosoft وArm، يُثير مخاوف مماثلة بشأن التأثير السياسي.
بالإضافة إلى ذلك، يشير قرار ميتا الأخير بالتخلي عن التحقق من الحقائق على فيسبوك وإنستغرام إلى اتجاه متزايد نحو الشعبوية على حساب الصدق.
أحدث ظهور شركة DeepSeek اضطراباً كبيراً في سوق التعلم القائم على التعلم الآلي. وستضطر الشركات الأمريكية مثل OpenAI وAnthropic إلى تطوير منتجاتها للحفاظ على أهميتها ومضاهاة أدائها وتكلفتها.
يُشكّل نجاح شركة DeepSeek تحدياً للوضع الراهن، إذ يُبرهن على إمكانية تطوير نماذج LLM عالية الأداء دون الحاجة إلى ميزانيات بمليارات الدولارات. كما يُسلّط الضوء على مخاطر الرقابة على نماذج LLM، وانتشار المعلومات المضللة، وأهمية التقييمات المستقلة.
مع ازدياد انغماس برامج الماجستير في القانون في السياسة والأعمال العالمية، ستكون الشفافية والمساءلة ضروريتين لضمان أن يكون مستقبل هذه البرامج آمناً ومفيداً وجديراً بالثقة.
سيمون ثورن، محاضر أول في علوم الحاسوب ونظم المعلومات، جامعة كارديف متروبوليتان.
نُشرت هذه المقالة من موقع "ذا كونفرسيشن" بموجب ترخيص "كرييتف كومنز". اقرأ المقالة الأصلية .